— между исходным и целевым сайтом (site-to-site); — между кластерами внутри сайта; — между несколькими исходными сайтами и общим целевым сайтом (many-to-one).
Disaster Recovery в облако: кому нужно и как его обеспечить
Мы расскажем вам, кто должен заботиться об аварийном восстановлении и какие существуют варианты реализации DR.
Аварийное восстановление — это набор инструментов, позволяющих быстро восстановить инфраструктуру, данные и все системы в случае критического сбоя.
Причины отказов могут быть как общими — перебои в подаче электроэнергии в районе расположения оборудования и проблемы с сетью, — так и исключительными. Например, DR готовит службу к землетрясениям, пожарам и наводнениям. Любое событие, которое может нанести серьезный ущерб инфраструктуре центра обработки данных компании, вплоть до полной катастрофы.
По сути, аварийное восстановление требует наличия резервного сайта для восстановления полного «клона» или части инфраструктуры предприятия. Чтобы соответствовать требованиям DR, сайт должен быть:
→ быть географически удаленным от основного сайта (чтобы катастрофа, произошедшая в первом центре обработки данных, не повлияла на второй),
→ иметь хорошее сетевое соединение с объектом инфраструктуры (чем выше пропускная способность, тем быстрее данные будут поступать на резервный объект).
Способы организации DR
Аварийное восстановление — это понятие, которое можно применять по-разному.
Сделать самостоятельно на своей инфраструктуре (on-premises)
Невозможно избежать капитальных затрат (всю инфраструктуру пришлось бы удвоить) и инактивации приобретенного оборудования. Аварийное восстановление в организации также является сложной задачей, требующей высокой квалификации. Таким образом, помимо CAPEX, существует потребность в квалифицированных DevOps, NetOps и архитекторах инфраструктуры.
Построить Disaster Recovery на арендованных физических серверах
Это может быть сделано путем полной репликации инфраструктуры с использованием концепции георепликации (размещение в другом географическом месте). Однако такой реализации не хватает гибкости — настройка DR, а также изменения в инфраструктуре потребуют больше времени. Также нет гибкости в стоимости резервной инфраструктуры — как минимум месячная арендная плата.
Развернуть Disaster Recovery в облако
В настоящее время это оптимальный и наиболее распространенный сценарий в деловой практике. Облачную инфраструктуру легче настраивать и масштабировать. Если компания использует Terraform или другие инструменты IaC, резервный сайт может быть создан за считанные минуты.
Еще одним очевидным преимуществом является модель оплаты по факту — оплата за потребленные ресурсы — которую поддерживают облака. Если компании не требуется круглосуточная активная репликация инфраструктуры, она может сэкономить ресурсы.
Disaster Recovery as a service
В качестве альтернативы созданию облачного сайта резервного копирования можно использовать стандартную DR-систему.
Аварийное восстановление в облако
Указывает на максимальное время простоя, которое может выдержать организация. Чем меньше этот процент, тем менее заметным для конечного пользователя будет переход на резервный сайт. Предположим, что RTO установлен на 15 минут. В этом случае обслуживание начнется в нормальном режиме не позднее этого времени. В идеале — раньше.
Характеристики Disaster Recovery
Чем короче RTO, тем дороже это обходится компании. Это связано с тем, что при внедрении используются более технологичные (и более дорогие) решения, а инфраструктура резервного копирования должна поддерживаться в активном состоянии.
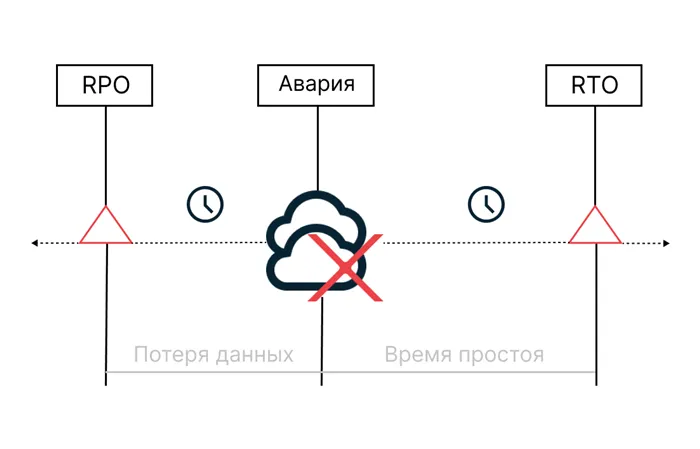
RTO
Он определяет максимальный объем данных, который компания может потерять в случае аварии или сбоя. Чем ниже процент, тем чаще компания осуществляет резервное копирование. Так, если RPO составляет 1 минуту, это означает, что резервная копия создается каждую минуту.
Все это также влияет на стоимость решения. По этой причине не существует «золотого стандарта» для RPO и RTO — каждая компания устанавливает эти показатели индивидуально. Обычно это консенсус между тем, что компания теряет из-за простоя, и тем, что она потратит для достижения нужных показателей RPO и RTO.
RPO
Есть компании — например, крупные банки — чьи потенциальные репутационные и финансовые издержки в случае сбоя всегда будут покрывать затраты на организацию аварийного восстановления на самом высоком уровне. А есть компании, которым выгоднее «не высовываться», чем пересматривать свою инфраструктуру.
Определение RTO и RPO является частью плана аварийного восстановления ИТ (DRP), который в идеале должна иметь каждая компания, независимо от ее размера и особенностей бизнеса. Мы напишем об этом более подробно.
Знакомьтесь: Винчин, разработчик программного обеспечения для виртуальных сред. Компания Vinchin была основана в 2015 году. Основное внимание уделяется защите данных в облаке и в виртуальных инфраструктурах. Компания Vinchin предлагает решения для резервного копирования, прямого и удаленного аварийного восстановления для частных, публичных и гибридных облачных сред. Он обеспечивает защиту и резервное копирование для VMware, Hyper-V, XenServer, XCP-ng и других платформ виртуализации.
В последнее время Винчин начал фокусироваться на рынке СНГ и, в частности, на российском рынке. Компания адаптировала свои продукты к российским системам виртуализации. В частности, реализована поддержка российской платформы управления серверами виртуализации zVirt.
↑ О компании Vinchin
В последнее время в ИТ-среде эффективность сотрудников значительно возросла. Благодаря виртуальной ИТ-среде компании могут получить и другие преимущества, такие как гибкое распределение ресурсов и снижение затрат на оборудование.
Программное обеспечение Veeam реализует защиту от ransomware на уровне хранилища, но затрагивает вопросы интеграции с Linux и хранилищем S3.
↑ Защита виртуальных сред
После установки этого решения для аварийного восстановления в ИТ-среде ИТ-администратор должен включить Hardened Repository для защиты файлов резервных копий от внешних и внутренних угроз. И сделайте файлы резервных копий неизменяемыми.
Это решение обеспечивает три уровня защиты от ransomware. Уровень производительности, на котором создается файловое хранилище резервных копий с усиленной защитой, а также уровни емкости и архивирования, на которых используются механизмы безопасности объектного хранилища S3.
Процедуры настройки репозитория с жесткой защитой аналогичны процедурам для репозитория Linux, но есть определенные предпосылки: Хранилище жесткой защиты требует 64-разрядных операционных систем Linux, а файловая система должна поддерживать расширенные функции и chattr.
↑ Традиционное решение для защиты от программ-вымогателей
После правильной настройки файлы резервных копий в жестком хранилище останутся неизменными.
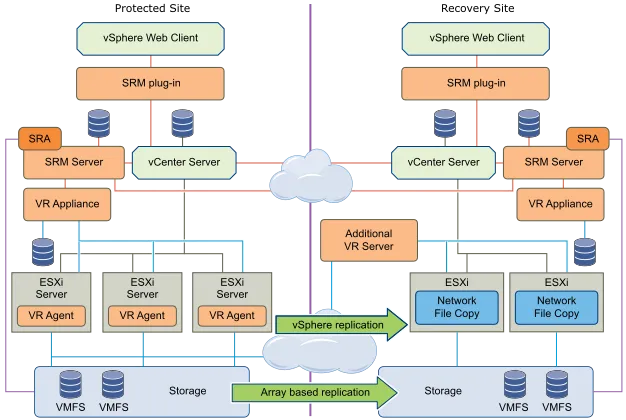
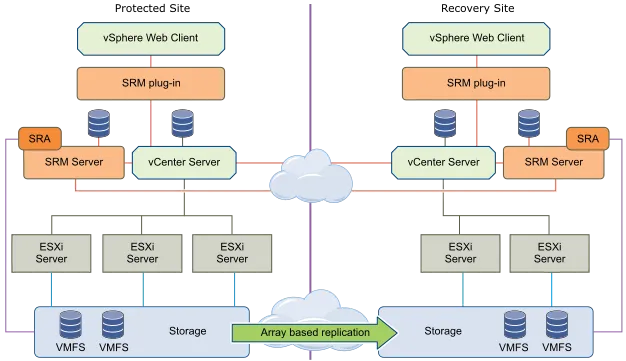
Этот подход включает репликацию данных между сайтами на уровне массива (SRM) с помощью встроенных механизмов репликации. SRM интегрируется в массивы с помощью адаптеров репликации хранилищ (SRA) — программных компонентов, разработанных поставщиками массивов. Для поддержки репликации на основе массивов на SRM-сервере каждого сайта должны быть установлены SRA для каждого подключенного массива.
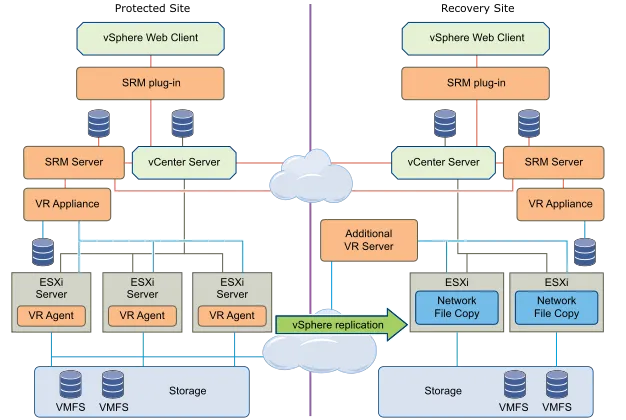
SRM может использовать vSphere Replication (встроенная и бесплатная технология в пакете VMware vSphere) для репликации данных на уровне виртуальных машин между сайтами. Функция vSphere Replication не зависит от типа и модели хранилища, не требует интеграции массивов (SRA provisioning) и поддерживает любые vSphere-совместимые хранилища.
С помощью vSphere Replication можно создать цепочку моментальных снимков для реплицированных ВМ в месте резервного копирования — несколько копий защищенных машин в разные моменты времени. Это позволяет выбрать оптимальное состояние ВМ для восстановления из нескольких копий моментальных снимков.
SRM поддерживает смешанный режим работы, когда оба механизма репликации, репликация на основе массива и репликация vSphere, используются вместе. Этот режим требует установки и настройки этих технологий на обеих площадках. Настройка различных механизмов репликации для одних и тех же виртуальных машин не поддерживается. Однако SRM позволяет включать задачи восстановления с разными механизмами репликации, но для разных ВМ в один план.
SRM с репликацией на уровне массива (Array-based replication)
SRM с использованием vSphere Replication
Смешанный режим репликации