Этот процесс полностью автоматизирован, поскольку включает в себя анализ миллионов симуляций, изучение всех возможностей до тех пор, пока не будет найден паттерн (правильная форма) или пока не возникнет «озарение», которое поможет решить проблему, для которой он был разработан.
Big Data
Большие данные — что это такое? В буквальном переводе этот термин означает «большие данные». В традиционном понимании Большие данные — это совокупность огромных объемов информации, которая настолько сложна и неорганизованна, что не поддается обработке обычными средствами управления базами данных. Большие данные просто не вписываются в традиционные рамки из-за своего размера.
Этот термин также относится не к самой информации и не к одной технологии, а к комбинации современных и проверенных инструментов для обработки огромных потоков данных, которые помогают извлечь действенную информацию.
В целом, Большие данные можно определить как способность управлять огромным количеством разрозненных данных с нужной скоростью и в нужные сроки, чтобы обеспечить их обработку и анализ в режиме реального времени.
Просто о больших данных
Каждый раз, когда кто-то открывает приложение на смартфоне, посещает веб-сайт, подписывается на определенный ресурс в Интернете или даже вводит запрос в поисковую систему, собирается огромное количество данных.
Пользователи обычно больше внимания уделяют результатам своей деятельности в Интернете. Их не особенно интересует, что происходит «за кулисами». Пример: человек открывает браузер и набирает в поиске «Big Data», а затем нажимает на ссылку, чтобы прочитать наш глоссарий. Один только этот запрос помогает сгенерировать определенный объем Больших Данных. Если представить, сколько времени люди проводят в Интернете, посещая различные сайты, скачивая изображения и т.д., становится понятно, о каких огромных объемах информации может идти речь.
Характеристики больших данных
Существуют определенные термины, связанные с Большими Данными, которые необходимы для их описания и понимания их природы. Их называют характеристиками Больших Данных.
Согласно традиционной точке зрения, Большие данные имеют 3 основные характеристики. В английском языке они обозначаются как 3 В:
- Объем, Объем: сколько данных. Компаниям, работающим с большими данными, необходимо постоянно масштабировать свои решения для хранения данных, поскольку им постоянно требуются большие объемы памяти.
- Скорость: как быстро обрабатываются данные. Поскольку большие данные генерируются каждую секунду, компаниям необходимо реагировать в режиме реального времени, чтобы управлять этими потоками данных.
- Разнообразие, разнообразие: какие типы данных обрабатываются и в каком объеме. Большие данные бывают разных форм. Он может быть структурированным или неструктурированным, а также в различных форматах, таких как текст, видео, изображения и т.д.
Хотя удобно сводить Большие данные к трем «V», современный подход считает это упрощенной схемой, которая может ввести в заблуждение. Что является обязательной функцией, а что нет? Например, компания может управлять относительно небольшим объемом разнообразных данных или огромным объемом очень простых данных. В обоих случаях один из признаков — либо объем, либо сорт — не одинаков. Однако мы все еще говорим о Больших Данных.
Чтобы дополнить постоянно развивающиеся технологии в этой области, аналитики ввели дополнительные 2V, которые также относятся к атрибутам Больших Данных и используются для их описания.
- Ценность, ценность : имеют ли данные ценность. Сам по себе сбор и хранение Больших Данных не имеет практической пользы, если их не анализировать и не получать результаты.
- Истина, честность : насколько правдивы данные. Большие данные, какими бы большими они ни были, также могут содержать ложную информацию. Неопределенность данных — это то, что необходимо учитывать при работе с Большими Данными.
Последняя характеристика требует некоторого уточнения. Должны существовать заранее определенные критерии, по которым собранные Большие данные могут быть проверены на достоверность. Важно, чтобы конкретный проект был правильно оценен — собранные данные необходимо проверить на точность и соответствие контексту.
Как и в реальной жизни, истина для каждого своя. Например, маловероятно, что «истинные» критерии оценки стоимости бизнеса совпадают с параметрами оценки стоимости конкретного клиента — например, компании «Экспресс-кредиты». В первом случае учитываются финансовые результаты компании и сравнение с другими аналогичными компаниями, а во втором — кредитная история физического лица, наличие просроченной задолженности и уровень официального дохода. В обоих случаях вам нужны подсказки о том, какой объем информации необходим, какие особенности информации нужно выделить и какие критерии нужно проанализировать в режиме реального времени, чтобы получить нужный бизнес-результат.
Этот термин также относится не к самой информации и не к одной технологии, а к комбинации современных и проверенных инструментов для обработки огромных потоков данных, которые помогают извлечь действенную информацию.
Итак, что значит Big Data — 2017?
Все началось с резкого увеличения объема данных, которые мы генерируем с начала цифровой эпохи. Это стало возможным во многом благодаря увеличению количества и мощности компьютеров, распространению Интернета и развитию технологий, позволяющих получать информацию из реального, физического мира, в котором мы все живем, и превращать ее в цифровые данные.
Мы генерируем данные, когда подключаемся к Интернету, когда пользуемся компьютерами, когда общаемся с друзьями в социальных сетях, когда загружаем мобильные приложения или музыку, когда что-то покупаем.
Можно сказать, что мы оставляем множество цифровых следов во всем, что делаем, если наши действия связаны с цифровыми транзакциями. То есть почти всегда и везде.
Более того, объем данных, генерируемых самими машинами, стремительно растет. Данные генерируются и передаются, когда наши интеллектуальные устройства общаются друг с другом. Производственные объекты по всему миру оснащены устройствами, которые собирают и передают данные днем и ночью.
В ближайшем будущем наши дороги будут населены самоуправляемыми автомобилями, которые сами определяют свои маршруты на основе четырехмерных карт, данные которых генерируются в режиме реального времени.
Что может Big Data?
Бесконечно растущий поток сенсорной информации, фотографий, текстовых сообщений, аудио- и видеоданных лежит в основе Больших Данных, которые мы можем использовать так, как еще несколько лет назад было невозможно себе представить.
Сейчас помогают проекты, основанные на Больших Данных:
— Лечить болезни и предотвращать рак. Медицина с использованием больших данных анализирует огромные объемы медицинских записей и изображений, что позволяет проводить очень раннюю диагностику и облегчает разработку новых методов лечения.
— Борьба с голодом. В настоящее время сельское хозяйство переживает настоящую революцию Больших Данных, которая позволит использовать ресурсы таким образом, чтобы максимизировать урожайность, минимизировать вмешательство в экосистему и оптимизировать использование машин и оборудования.
— Откройте для себя далекие планеты. НАСА, например, анализирует огромные объемы данных для создания моделей будущих полетов к далеким мирам.
— Прогнозировать чрезвычайные ситуации различного характера и минимизировать возможный ущерб. Данные с многочисленных датчиков могут предсказать, где и когда произойдет следующее землетрясение или как поведут себя люди в чрезвычайной ситуации, увеличивая шансы на выживание.
— Предотвращение преступлений путем использования технологий для более эффективного распределения ресурсов и их размещения там, где они больше всего нужны.
И самое близкое, что есть у большинства из нас: Большие данные делают жизнь обычного человека проще и удобнее — это включает в себя, ,, планирование поездок и навигацию по мегаполису.
Выбрать лучшее время для покупки авиабилетов и решить, какой фильм или передачу посмотреть, стало намного проще благодаря Большим Данным.
Как это работает?
Большие данные основаны на принципе: чем больше вы знаете о чем-то, тем точнее вы можете предсказать, что произойдет в будущем. Сравнивая отдельные фрагменты данных и связи между ними — мы говорим об огромных объемах данных и невероятно большом количестве возможных связей между ними — можно выявить скрытые ранее закономерности. Таким образом, мы можем проникнуть в суть проблемы и в конечном итоге понять, как контролировать тот или иной процесс.
В большинстве случаев обработка больших данных подразумевает построение моделей на основе собранных данных и проведение симуляций, в которых постоянно изменяются ключевые параметры, при этом система каждый раз отслеживает, как «изменение параметров» влияет на возможный результат.
Этот процесс полностью автоматизирован, поскольку включает в себя анализ миллионов симуляций, изучение всех возможностей до тех пор, пока не будет найден паттерн (правильная форма) или пока не возникнет «озарение», которое поможет решить проблему, для которой он был разработан.
В отличие от привычного нам мира объектов и вычислений, данные поступают в неструктурированном виде, а значит, их трудно уместить в привычные нам таблицы и колонки. Огромные объемы данных передаются в виде изображений или видео: от спутниковых снимков до селфи, которые вы публикуете в Instagram или Facebook, а также в виде сообщений электронной почты и мессенджеров или телефонных звонков.
Чтобы придать смысл всем этим бесконечным и разнообразным потокам данных, Большие данные часто используют самые передовые технологии анализа, которые включают искусственный интеллект и машинное обучение (когда одна программа на компьютере обучает другие программы).
Компьютеры сами обучаются определять, что является информацией — например, распознавать изображения или речь — и могут делать это гораздо быстрее, чем люди.
Мы можем предположить, что компании, государственные учреждения и даже отдельные лица будут использовать то, что они могут узнать о нас, чтобы минимизировать риск, и по веским причинам ограничат наш доступ к ресурсам и информации.
Однако, как всегда, в России все немного замедляется. Например, определение Big Data даже не существовало в России более 5 лет назад (сейчас я говорю об обычных компаниях).
И это несмотря на то, что это один из самых быстрорастущих рынков в мире (наркотики и оружие нервно отходят на второй план), а рынок программного обеспечения для сбора и анализа Больших Данных растет на 32% в год.
Для описания рынка Больших Данных в России на ум приходит старый анекдот. Большие данные — это как секс в возрасте до 18 лет. Все говорят об этом, много говорят, но мало делают, и всем стыдно признаться, что они сами этого не делают. Об этом много говорят, но мало действуют.
Хотя известная исследовательская компания Gartner еще в 2015 году заявила, что Большие данные — это уже не растущий тренд (как и искусственный интеллект, кстати), а скорее несколько самостоятельных инструментов для анализа и разработки передовых технологий.
Наиболее активными секторами, использующими Большие Данные в России, являются банковский/страховой сектор (почему-то я начал свою статью с главы Сбербанка), телекоммуникации, розничная торговля, недвижимость и государственный сектор.
Для примера я более подробно остановлюсь на некоторых секторах экономики, в которых используются алгоритмы Больших Данных.
1. Банки
Давайте начнем с банков и информации, которую они собирают о нас и наших действиях. Для примера я выбрал пять крупнейших российских банков, которые активно инвестируют в Big Data:
- Сбербанк,
- Газпромбанк,
- СБЕРБАНК, СБЕРБАНК, ГАЗПРОМ, ГАЗПРОМБАНК, ВТБ 24,
- Сбербанк, Альфа Банк, Альфа Россия, Альфа Банк, Тинькофф Банк, Тинькофф Банк.
- Особенно приятно видеть Альфа-Банк среди российских лидеров. По крайней мере, приятно осознавать, что банк, официальным партнером которого вы являетесь, понимает необходимость внедрения новых маркетинговых инструментов в свой бизнес.
Однако я хотел бы привести примеры использования и успешного внедрения Больших Данных в банке, который я ценю за нестандартные взгляды и действия его основателя.
Я говорю о банке «Тинькофф», главной задачей которого была разработка системы для анализа Больших Данных в режиме реального времени, поскольку у него большая клиентская база.
Результат: время, затрачиваемое на внутренние процессы, сократилось как минимум в 10 раз, а в некоторых случаях — более чем в 100 раз.
О, и небольшое отвлечение. Знаете, почему я упомянул нестандартные выходки и поступки Олега Тинькова? На мой взгляд, они просто помогли ему вырасти из обычного бизнесмена, каких в России тысячи, в одного из самых известных и знаменитых предпринимателей. Посмотрите это необычное и интересное видео для доказательства:
В сфере недвижимости дела обстоят сложнее. И это именно тот пример, который я хочу привести, чтобы вы поняли, что такое большая дата в рамках обычного бизнеса. Предыстория:
2. Недвижимость
Обширная текстовая документация,
- Открытые источники (частные спутники, передающие данные о территориальных изменениях),
- Огромные объемы неконтролируемой информации в Интернете,
- Постоянные изменения в источниках и данных.
- Исходя из этого, необходимо подготовить и оценить стоимость участка земли, например, под деревней на Урале. У профессионала на это уйдет неделя.
Российской компании оценщиков & РОСЭКО, внедрившей собственное программное обеспечение для аналитики Больших Данных, потребуется не более 30 минут непрерывной работы. Сравните это с неделей и 30 минутами. Колоссальная разница.
Конечно, огромные объемы информации невозможно хранить и обрабатывать на простых жестких дисках.Инструменты создания
А программное обеспечение, которое структурирует и анализирует данные, является интеллектуальной собственностью, разрабатываемой одним разработчиком за другим. Однако есть инструменты, которые создают всю эту красоту:
Hadoop и MapReduce,
- Базы данных NoSQL,
- Инструменты класса Data Discovery.
- Честно говоря, я не смогу четко объяснить, чем они отличаются друг от друга, так как знакомство и обращение с этими вещами преподается в физико-математических институтах.
Почему же я упомянул об этом, если не могу объяснить? Помните все те фильмы, где грабители заходят в каждый банк и видят огромное количество всевозможных устройств, соединенных проводами? То же самое относится и к знаменательному дню. Вот пример модели, которая в настоящее время является лидером рынка.
Инструмент для работы с большими данными

В максимальной комплектации стоимость одной стойки достигает 27 миллионов рублей. Это, конечно же, роскошная версия. Я имею в виду, что вы должны попытаться создать Большие Данные в своем бизнесе заранее.
Устойчивость. Устойчивость данных. При большом количестве данных и переменных необходимо проверить их значимость при создании модели прогнозирования. Например, факторы, предсказывающие склонность потребителя к покупке: упоминания о продукте в социальных сетях, географическое положение, доступность продукта, время суток, профиль клиента.
Работа с большими данными включает в себя ряд этапов:
Как работает технология больших данных
Сбор информации из различных источников,
- хранение данных,
- обработка и анализ.
- Информация окружает нас повсюду. Социальные сети, поисковые системы, гаджеты, карты лояльности, данные GPS-слежения и электронные кассовые аппараты ежеминутно генерируют огромные потоки данных. Источники Больших Данных можно разделить на три типа: социальные, механические и транзакционные.
Сбор информации
Социальные — созданные людьми. Информация, загруженная или созданная пользователями Интернета: Фотографии, электронные письма, сообщения, статьи, посты в блогах. Он также включает социальную и демографическую статистику по странам и компаниям.
Транзакционный — возникает, когда происходят различные операции. Сюда входят покупки, денежные переводы, доставка товаров, операции с банкоматами, переходы по ссылкам и поисковые запросы.
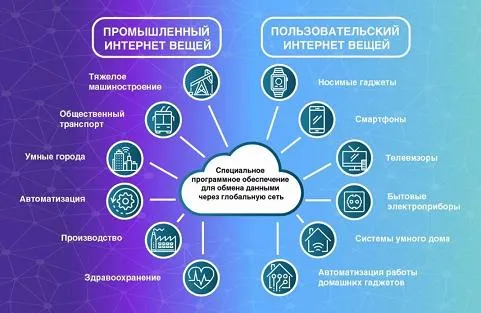
Машинное обучение — информация от датчиков и устройств. Сюда входит Интернет вещей — данные, которыми устройства обмениваются друг с другом. Например, датчики в автомобилях, погодные устройства, смартфоны, умные колонки и т.д.
Что есть в интернете вещей. Источник
Большие данные требуют больших мощностей для размещения. У компании, собирающей Большие данные, есть три варианта того, где хранить эти данные:
Хранение
На собственных серверах. Компания сама закупает, настраивает и обслуживает оборудование.
- Компания сама поддерживает и управляет данными. Компания арендует помещение у сторонней компании за определенную плату. Amazon, Microsoft или Google предлагают такую услугу. Помимо систем хранения, некоторые платформы также предлагают стандартные решения для обработки данных, например, Oracle Exadata.
- Общественные большие данные. Доступ к базе данных бесплатный, и она хранится в облаке или на частных серверах.
- Различные типы хранения имеют свои преимущества и недостатки:
1. на собственном сервере. Это может быть дешевле, но время работы, безопасность и поддержка зависят от вас. 2. в облаке. Это может быть дороже, но о времени работы, безопасности и поддержке позаботится облако.
— Данные с сейсмологических станций по всему миру. — база данных аккаунтов пользователей на Facebook — геолокационная информация всех фотографий, размещенных в настоящее время на Instagram — базы данных мобильных операторов.
Хранилища данных или озера данных обычно организуются для хранения данных. Хранилище данных работает по принципу ETL (Extract, Transform, Load) — сначала извлечение, затем преобразование, затем загрузка. Озеро данных отличается от ELT (Extract, Load, Transform) — сначала данные загружаются, а затем преобразуются.
Подходы к хранению Big Data
Существует три основных принципа хранения больших данных:
Горизонтальная масштабируемость. Система должна быть масштабируемой. По мере роста объема данных необходимо увеличивать емкость кластера путем добавления серверов.
Отказоустойчивость. Обработка требует больших вычислительных мощностей, что повышает вероятность ошибок. Большие данные необходимо обрабатывать непрерывно и в режиме реального времени.
Локализация. Кластеры реализуют принцип локальности данных — обработка и хранение происходят на одном компьютере. Такой подход минимизирует затраты на передачу информации между серверами.
Интеллектуальный анализ данных представляет собой сочетание подходов классификации, моделирования и прогнозирования.
Анализ больших данных: от web mining до визуализации аналитики
Анализ может оценивать различные типы информации, будь то текст, изображения, аудио- или видеоданные. Отдельно выделяют веб-майнинг и майнинг социальных сетей, которые работают с интернетом и социальными сетями. Язык программирования SQL используется для работы с реляционными базами данных и подходит для создания, изменения и извлечения хранимых данных.
Нейронные сети. Обученная нейронная сеть может обрабатывать большие объемы данных с большой скоростью и точностью. Чтобы использовать нейронную сеть в анализе, ее необходимо обучить.
Машинное обучение — это наука о том, как искусственный интеллект обучается работать самостоятельно и расширять свои знания и возможности. ML изучает, как создавать системы, которые совершенствуются сами по себе по мере накопления опыта. Алгоритмы машинного обучения обобщают существующие парадигмы для выполнения более сложных задач. С помощью этой технологии ИИ проводит анализ, делает прогнозы, воспроизводит и улучшает модели.
После проведения анализа данные представляются в виде аналитического отчета с предложениями по возможным решениям. Методы, используемые для преобразования больших данных в читаемый формат, называются бизнес-аналитикой. Наиболее важным инструментом BI являются приборные панели, интерпретация и визуализация аналитических данных в виде изображений и диаграмм. Приборные панели помогают сосредоточиться на KPI, построить бизнес-модели и отслеживать результаты принятых решений.
Именно эта обратная связь обеспечивает возможности для развития бизнеса, которые могут быть достигнуты с помощью Больших Данных. Ранее не обнаруженные закономерности помогают улучшить бизнес-процессы и увеличить прибыль.
Одним из способов распределенных вычислений является метод параллельной обработки MapReduce, разработанный компанией Google, который организует данные в виде наборов данных. Функции работают независимо и параллельно, поэтому сохраняется принцип горизонтального масштабирования. Обработка происходит в три этапа:
Работайте с Big Data на инфраструктуре Selectel
Инструменты для обработки больших данных
Карта. Функция определяется пользователем, карта используется для первоначальной обработки и фильтрации. Функция применяется к одной входной записи, извлекается несколько пар ключ-значение. Он применяется на том же сервере, где хранятся данные, что соответствует принципу локальности.
- Шаффл. Вывод карты разделен на «корзины». Каждый из них соответствует ключу выхода первого этапа, и классификация выполняется параллельно. Корзины служат исходными данными для третьего этапа.
- Уменьшить. Каждое «ведро» значений поступает на вход функции reduce. Он определяется пользователем и рассчитывает конечный результат для каждого «ведра». Сумма всех значений в функции reduce дает конечный результат.
- Для разработки и запуска программ, работающих на кластерах любого размера, используется ряд утилит, библиотек и фреймворк Hadoop. Программное обеспечение Apache Software Foundation с открытым исходным кодом используется для хранения данных, программирования и совместной работы. Подробнее об истории и структуре проекта Hadoop.
Apache Spark, фреймворк с открытым исходным кодом в экосистеме Hadoop, используется для вычислений в кластерах. Библиотека Apache Spark выполняет вычисления в памяти, что ускоряет выполнение многих задач и подходит для машинного обучения.
NoSQL — это тип нереляционной СУБД. Хранение и извлечение данных моделируется с помощью других средств, помимо табличных отношений. Для хранения информации не требуется предопределенная схема данных. Главное преимущество этой концепции заключается в том, что любые данные могут быть смонтированы и быстро извлечены из памяти. Термин расшифровывается как «Не только SQL».
Все базы данных принадлежат к семейству Amazon»:
Примеры подобных СУБД
DynamoDB — бессерверная управляемая база данных на основе пар ключ-значение, предназначенная для запуска высокопроизводительных приложений любого масштаба и подходящая для IoT, игровых и рекламных приложений.
- DocumentDB — база данных документов для управления каталогами, профилями пользователей и системами управления контентом, где каждый документ уникален и меняется со временем.
- Neptune — это управляемая служба базы данных графов. Он упрощает разработку приложений, работающих со сложными наборами данных. Он подходит для работы с рекомендательными сервисами, социальными сетями и системами обнаружения мошенничества.
- R. Язык используется для обработки данных, создания статистики и работы с графикой. Загружаемые модули связывают R с фреймворками GUI и позволяют разрабатывать аналитические программы с графическим интерфейсом. Графики можно экспортировать в распространенные форматы и использовать для презентаций. Статистические данные отображаются в виде графиков и диаграмм.
Самые популярные языки программирования для работы с Big Data
- Scala. Родной язык для Apache Spark, используемый для анализа данных. Проекты Spark и Kafka от Apache Software Foundation в основном написаны на языке Scala.
- Питон. Существуют готовые библиотеки для AI, ML и других методов статистических вычислений: TensorFlow, PyTorch, SKlearn, Matplotlib, Scipy, Pandas. Для обработки и хранения данных существуют API в большинстве фреймворков: Apache Kafka, Spark, Hadoop.
- Правда. Истина — это когда данные «правильные» и последовательные. То есть она надежна, ее можно анализировать и использовать для принятия бизнес-решений.
Для анализа можно использовать любой объем Больших Данных. Иногда данные сначала структурируются и отбираются для анализа. Ниже описаны основные методы анализа Больших Данных:
Методы анализа big data
Описательный анализ. Это анализ, цель которого — ответить на вопрос «Что произошло?». Примером описательного анализа является финансовый отчет, который описывает, что произошло, не объясняя, почему. Другой пример — статистика активных пользователей социальных сетей за один день.
Диагностические анализы. На этом этапе анализа вам необходимо понять: «Почему это произошло? Иногда диагностический анализ также называют факторным анализом. То есть, в ходе анализа выявляются факторы, вызвавшие изменение показателей. Например, финансовые аналитики ежегодно отчитываются о динамике инфляции и объясняют нам, почему она изменилась. Результатом диагностического анализа является определение факторов, вызвавших изменение инфляции.
Предсказательный анализ. Цель метода — ответить на вопрос «Что произойдет в будущем?». Для анализа используются методы науки о данных, основанные на различных математических концепциях. Прогностический анализ — это, по сути, расчет вероятности того, что что-то произойдет в будущем. Например, утверждение «Существует 80% вероятность того, что фондовый рынок вырастет на следующей неделе» является результатом прогностического анализа.
Предсказательный анализ. Этот метод считается самым передовым. В нем автоматизированная система дает рекомендации по действиям на основе предыдущих анализов. Метод отвечает на вопрос «Что следует делать?
Большие данные используются практически во всех сферах жизни. Вот примеры в разных областях.
Примеры использования big data
Предприятия. Все крупные компании работают с Большими Данными. В Америке более 55% компаний различных отраслей работают с технологиями. В Азии и Европе это делают 53% компаний. Компании, которые не используют Большие данные, упускают возможность. Производитель строительного оборудования Caterpillar признал, что его дилеры упускают от 9 до 18 миллиардов долларов прибыли ежегодно из-за того, что не работают с Big Data.
Банковское дело. Финансовые технологии — один из самых быстрорастущих секторов экономики. Благодаря Big Data банки могут предлагать совершенно новые услуги, которые ранее были недоступны: Выявление мошенничества, автоматизированный кредитный анализ и учет.
Маркетинг. Маркетинг всегда был движущей силой для Больших Данных: решения принимаются на основе данных. Например, он используется для анализа посетителей сайта, определения предпочтений клиентов, понимания того, успешна ли .
Медицина. Современные методы анализа данных, включая компьютерное зрение, прокладывают путь для одной из самых перспективных областей сегодняшнего дня. Анализ человеческой деятельности может изменить нашу жизнь, как когда-то изменили ее социальные сети.
Автомобильные технологии. Автопилоты, роботы-доставщики, автоматизированные производственные машины — это вещи, которые существуют уже сегодня. Без Больших Данных это было бы невозможно.
Розничная торговля. Наряду с финтехом и маркетингом, в розничной торговле всегда было много данных о транзакциях. Она может быть использована для улучшения пользовательского опыта в магазинах и в Интернете. Например, размещение товаров на полках на основе истории продаж и карты, показывающей, как покупатели перемещаются по магазину.
Набор персонала. Автоматизированное чтение резюме, выявление талантов среди десятков тысяч резюме, чат-боты для базовой проверки сотрудников — это лишь малая часть приложений Big Data для рекрутинга.
Государственные учреждения. Они могут использовать Большие данные для управления городами. Большие данные могут быть использованы для создания умных городов с интеллектуальной системой, которая поддерживает жизнь горожан на протяжении всей их жизни.
СМИ. Большие данные напрямую влияют на объем доходов в этом секторе. Зная, какие заголовки наиболее вероятны для определенной группы пользователей, какие новости или развлечения представляют интерес, и анализируя поведение пользователей, можно зарабатывать больше денег. Например, потоковые онлайн-сервисы, такие как Netflix, используют Big Data даже для производства сериалов, а не только для онлайн-рекламы.
Логистика. Большие данные помогают найти оптимальный маршрут на большие расстояния и оптимизировать доставку. Есть компании, которые используют дополненную реальность в учете запасов.
Существует множество профессий, которые зависят от работы с Большими Данными.
Кто работает с большими данными
Инженер по обработке данных. Для работы с Большими данными необходимо собрать данные, организовать их хранение, подготовить и обработать. Все это обеспечивает инженер, который разрабатывает процессы для работы с Большими Данными.
Инженер по обработке данных — это программист, имеющий опыт работы с различными базами данных и сверхмощными системами обработки данных.
Специалист по анализу данных. Это эксперт в области анализа данных, математической статистики и вероятности. Его основная работа заключается в построении математических моделей для прогнозирования, оптимизации и других задач. Специалист по исследованию данных меньше вовлечен в бизнес-процессы компании, поскольку он/она сосредотачивается на решении технических и математических проблем.
Аналитик данных. Он является экспертом в области анализа данных и бизнес-процессов компании, в которой работает. Аналитик данных знает, какие задачи и проблемы стоят перед компанией и какие данные доступны для анализа. Они являются связующим звеном между компанией и миром больших данных.