В статье упоминается фраза Хэла Вэриана, главного экономиста Google: «В ближайшие 10 лет самая сексуальная работа — это статистика. Люди думают, что я шучу, но кто бы мог подумать, что компьютерные инженеры станут самой сексуальной профессией 90-х?».
Большой гид по Data Science для начинающих: термины, применение, образование и вход в профессию
Наши друзья в Цехе выложили пошаговую инструкцию для начинающих в области науки о данных от Елены Герасимовой, директора по науке о данных и аналитике в Netology. Делимся с вами.
Data Science — это деятельность, связанная с анализом данных и поиском лучших решений из них. Раньше такие задачи выполняли специалисты по математике и статистике. Тогда на помощь пришел искусственный интеллект, позволивший включить в методы анализа оптимизацию и информатику. Этот новый подход оказался гораздо более эффективным.
Как строится процесс? Все начинается со сбора больших наборов структурированных и неструктурированных данных и преобразования их в удобочитаемый формат. Кроме того, используются визуализация, работа со статистикой и аналитические методы: машинное и глубокое обучение, вероятностный анализ и прогнозные модели, нейронные сети и их применение для решения реальных задач.
Пять главных терминов, которые нужно запомнить
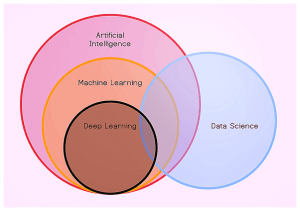
Искусственный интеллект, машинное обучение, глубокое обучение и наука о данных — основные и самые популярные термины. Они близки, но не эквивалентны друг другу. Сначала важно понять, чем они отличаются.
Искусственный интеллект — это область, посвященная созданию интеллектуальных систем, которые функционируют и действуют как люди. Его происхождение связано с появлением машин Алана Тьюринга в 1936 году. Несмотря на долгую историю развития, искусственный интеллект до сих пор не в состоянии полностью заменить человека в большинстве областей. И ИИ, конкурирующий с людьми в шахматах и шифровании данных, — это две стороны одной медали.
Машинное обучение — это создание инструмента для извлечения знаний из данных. ML-модели обучаются на данных самостоятельно или поэтапно: обучение с мастером на подготовленных человеком данных и без мастера, работа со спонтанными и зашумленными данными.
Глубокое обучение — это создание многослойных нейронных сетей в областях, где требуется более продвинутый или быстрый анализ, и традиционное машинное обучение не справляется. «Глубина» обеспечивается различными скрытыми слоями нейронов в сети, которые выполняют математические вычисления.
Большие данные: работа с большим объемом данных, часто неструктурированных. Детали сферы – это инструменты и системы, способные выдерживать высокие нагрузки.
Наука о данных: в основе этой области лежит осмысление наборов данных, визуализация, сбор информации и принятие решений на основе этих данных. Специалисты по данным используют некоторые методы машинного обучения и больших данных: облачные вычисления, инструменты для создания виртуальной среды разработки и многое другое.
И это только самый краткий и поверхностный список применений науки о данных. Количество различных кейсов с использованием «науки о данных» с каждым годом увеличивается в геометрической прогрессии.
Чем занимается Data Scientist?
Специалист по данным применяет методы науки о данных для обработки больших объемов информации. Создавайте и тестируйте математические модели поведения данных. Это помогает найти в них закономерности или предсказать будущие значения. Например, на основе прошлого спроса на продукты специалист по данным может помочь компании спрогнозировать продажи в следующем году. Модели строятся с использованием алгоритмов машинного обучения, а базы данных работают через SQL.
Специалисты по данным работают везде, где есть большой объем информации: чаще всего это крупные компании, стартапы, научные организации. Поскольку методы работы с данными универсальны, для специалистов открыта любая область: от ритейла и банковского дела до метеорологии и химии. В науке они помогают делать важные открытия: проводят сложные исследования, например, строят и обучают нейронные сети для молекулярной биологии, изучают гамма-излучение или анализируют ДНК.
В крупных компаниях специалист по данным — это человек, который нужен всем отделам:
- это поможет маркетологам анализировать данные карт лояльности и понимать, какие группы клиентов рекламировать;
- для логистики изучит данные с GPS-трекеров и оптимизирует маршрут перевозки;
- Поможет отделу кадров спрогнозировать, кто из сотрудников скоро уволится, анализируя их активность в течение рабочего дня;
- с продавцами прогнозирует спрос на товары с учетом сезонности;
- поможет юристам распознавать написанное на документах с помощью технологий оптического распознавания текста;
- в производстве он прогнозирует оборудование на основе данных датчиков.
В стартапах они помогают разрабатывать технологии, которые выводят продукт на новый уровень: TikTok использует машинное обучение, чтобы рекомендовать контент, а MSQRD, который купил Facebook, использует технологии распознавания лиц и искусственного интеллекта.
Пример задачи:
Если специалисту по данным необходимо предсказать спрос на новую коллекцию кроссовок, то:
- подготавливает данные о продажах кроссовок за последние годы;
- выбрать модель машинного обучения, которая лучше всего соответствует этому прогнозу;
- выбрать метрики, которые позволят оценить качество модели;
- написать код модели;
- применяет алгоритм машинного обучения к данным о прошлых продажах;
- получает прогнозные значения и предоставляет их менеджерам для принятия решения об объеме производства кроссовок.
Что ему нужно знать?
Специалист по данным должен хорошо разбираться в математике: линейной алгебре, теории вероятностей, статистике, математическом анализе. Математические модели позволяют находить закономерности в данных и предсказывать их значения в будущем. А чтобы применить эти модели на практике, нужно программировать на Python, уметь работать с SQL, а также библиотеки (набор готовых к использованию функций, объектов и подпрограмм) и фреймворки (программное обеспечение, объединяющее готовые к использованию использовать компоненты крупного программного проекта) для машинного обучения (например, NumPy и Scikit-learn). Для более сложных задач специалистам по данным нужен C или C++.
Результаты анализа данных должны быть визуализированы, например, с помощью библиотек Seaborn, Plotly или Matplotlib.

Примером визуализации данных с помощью Seaborn является количество женщин и мужчин, переживших крушение Титаника, по возрасту. Фонтан
Искусственный интеллект фокусируется на создании технологий, которые действуют и реагируют подобно человеческому разуму. В большинстве областей ИИ пока не может полностью заменить человека.
Терминология
Для того чтобы разобраться в выбранном направлении, необходимо прежде всего уточнить некоторые термины. Они чрезвычайно важны для будущего аналитика больших данных. В результате работы вы везде найдете себя:
- Искусственный интеллект — это способ, с помощью которого машины учат «думать» и принимать определенные решения. Используется в персонализации, а также двойниках и имитации человеческой мысли. Некий метод автоматизации принятия решений.
- Машинное обучение — это процесс создания инструментов для извлечения знаний из данных. К ним относятся: распознавание изображений, рекомендательные системы, алгоритмы прогнозирования, перевод графики в текст, синтез текстовых данных.
- Глубокое обучение — это создание нейронных сетей многослойного типа в областях, где требуется более быстрый и продвинутый анализ. В этом случае традиционное машинное обучение не справляется с поставленными задачами. Используется в «масках» утилит, синтезе звука, голоса или изображения.
- BigData — это большое количество информации различного типа. Набор крупных планов невероятного масштаба неструктурированных материалов, которые постоянно и непредсказуемо поступают из источников.
- Data Science — это придание смысла и понимания электронным материалам, их обработка, способ найти что-то полезное в общей неструктурированной массе. Этот процесс часто включает облачные вычисления, а также инструменты для создания виртуальных сред разработки.
Стоит обратить внимание на то, что при рассмотрении выбранного направления пригодятся языки программирования, а также знания в области информационных технологий и IT. Детали адреса — это системы и инструменты, способные выдержать огромную нагрузку (повышенную.
Состав аналитики данных
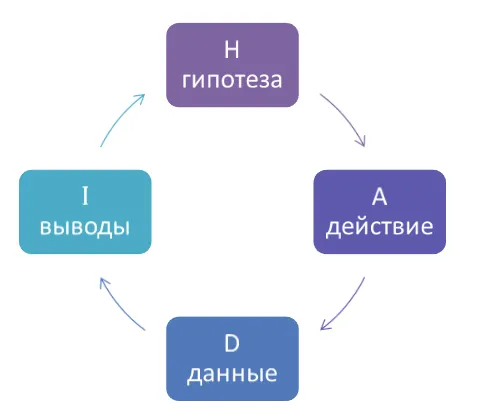
Для того, чтобы полноценно работать в «информатике», нужно выполнить определенные действия. Процесс анализа включает в себя:
- Сбор информации. На этом этапе осуществляется поиск каналов, с которых будут поступать материалы.
- Экзамен.
- Анализ. Специалист должен изучить информацию, а также подтвердить имеющиеся гипотезы.
- Отображать. Специалисту необходимо представить результаты так, чтобы они были предельно просты для человеческого понимания. Для реализации задачи обычно используются графики и диаграммы.
Последний шаг – действие. То есть принятие решений на основе проанализированных материалов. Одним из примеров является корректировка маркетинговых стратегий по мере увеличения доходов.
Люди, решившие стать экспертами в своих областях, сегодня высоко ценятся. Но не совсем понятно, кто они и чем занимаются эти «ученые». Эта статья раскроет секрет науки о данных.
Что нужно уметь?
Программировать на Python
Знание основ программирования будет большим преимуществом. Но это достаточно большая и сложная область, и чтобы немного облегчить изучение, можно сосредоточиться на одном языке. Python идеально подходит для начинающих: он имеет относительно простой синтаксис, многофункционален и часто используется для манипулирования данными.
Связанные книги:
- Python для сложных задач. Наука о данных и машинное обучение, Дж. Вандер Плас: Руководство по статистическим и аналитическим методам обработки данных;
- «Python and Data Science» Уэса МакКинни: руководство по использованию Python в науке о данных;
- Книга Эла Свейгарта «Автоматизация рутинных задач с помощью Python» представляет собой хорошую практическую основу для начинающих.
- Learning Python by M. Lutz — это учебник с практическим подходом, который подходит как для начинающих, так и для опытных разработчиков.
После того, как вы изучите основы Python, вы можете ознакомиться с библиотеками Data Science.
Машинное обучение и глубокое обучение:
Обработка естественного языка:
Собирать данные
Интеллектуальный анализ данных — важный аналитический процесс, предназначенный для изучения данных. Он позволяет находить скрытые закономерности и получать ранее неизвестную полезную информацию, необходимую для принятия любого решения. Сюда же относится визуализация данных: представление информации в понятном графическом виде.
Связанные книги:
- «Технологии анализа данных: Data Mining, Visual Mining, Text Mining, OLAP» Степаненко В.В., Холод И.И.: описание методов обработки данных с примерами;
- Обработка данных. Извлечение информации из Facebook, Twitter, LinkedIn, Instagram, GitHub», М. Рассел. М. Классен — книга, обучающая практическим методам анализа данных на примере популярных социальных сетей.
Хорошая стратегия — получить опыт работы с данными в онлайн-университете, а затем решать более сложные практические задачи на стажировке в компании.
Что дальше?
Изучив основы и пройдя всевозможные курсы по науке о данных, попробуйте свои силы в открытых проектах или конкурсах, а затем приступайте к поиску работы.
Как вы уже поняли, изучение Data Science с нуля — это не просто теория. Для практического опыта хорошо подходит Kaggle, веб-сайт, на котором постоянно проводятся конкурсы по анализу данных, в которых участвует каждый. Также существует множество открытых наборов данных: вы можете их анализировать и публиковать свои результаты. Также изучите работу других участников на Kaggle и учитесь на их опыте.
Чтобы подтвердить свою квалификацию, зарабатывайте баллы за участие в соревнованиях Kaggle и публикуйте свои проекты на GitHub. Главное не переставать учиться и получать удовольствие от того, что делаешь.
Специалисты, интересующиеся аналитикой и машинным обучением, имеют возможность получить знания, необходимые для профессионального роста. Для этого существует так называемая стажировка. Называется САС.
Как работают дата-сайентисты
Для работы с данными дата-сайентисты используют широкий набор инструментов: пакеты статистического моделирования, различные базы данных, специальное программное обеспечение. Но, самое главное, они используют технологии искусственного интеллекта и создают модели машинного обучения (нейронные сети), которые помогают компаниям анализировать информацию, делать выводы и прогнозировать будущее.
Каждую из этих нейронных сетей нужно спланировать, построить, протестировать, внедрить и только потом приступать к обучению. «Сейчас, по нашим оценкам, в процессе работы над ИИ-решениями только 30% времени специалистов уходит на обучение моделей. Все остальное — подготовка к этой и другим рутинам», — говорит Давид Рафаловский, технический директор Группы Сбербанк, исполнительный вице-президент, руководитель блока «Технологии.

Anaconda, компания, разрабатывающая продукты для работы с данными, приводит еще более печальную статистику. Их опросы показывают, что в среднем почти половину времени (45%) специалисты тратят на подготовку данных, то есть на их загрузку и очистку. Еще треть уходит на визуализацию данных и выбор модели. Только 12% и 11% рабочего времени тратится на обучение и развертывание соответственно.
Дата-сайентисты в облаках
Специальные облачные платформы помогают облегчить и ускорить работу по сбору данных, построению и развертыванию моделей. Именно облачные платформы для машинного обучения стали самым актуальным трендом в Data Science. Поскольку речь идет об огромных объемах информации, сложных моделях машинного обучения, готовых и доступных инструментах для работы с распределенными командами, специалистам по данным нужны были гибкие, масштабируемые и доступные ресурсы.
Именно для специалистов по данным облачные провайдеры создали платформы, ориентированные на подготовку и запуск моделей машинного обучения и работу с ними в большей степени. До сих пор таких решений немного, и одно из них создано полностью в России. В конце 2020 года Sbercloud представил ML Space — облачную платформу полного цикла для разработки и внедрения ИИ-сервисов. Платформа содержит набор инструментов и ресурсов для построения, обучения и развертывания моделей машинного обучения, от быстрого подключения к источникам данных до автоматического развертывания обученных моделей на динамически масштабируемых облачных ресурсах SberCloud.

Теперь ML Space — единственный в мире облачный сервис, позволяющий проводить распределенное обучение на более чем 1000 графических процессорах. Такую возможность предоставляет собственный облачный суперкомпьютер SberCloud Christofari. Запущенный в 2019 году, Christofari сейчас является самым мощным вычислительным кластером России и занимает 40-е место в мировом рейтинге суперкомпьютеров TOP500
Платформу уже используют команды разработчиков экосистемы Сбера. Именно с его помощью было запущено семейство виртуальных помощников «Салют». Более 70 различных моделей ASR (автоматического распознавания речи) и большое количество моделей преобразования текста в речь были обучены для их создания с использованием Christofari и ML Space. Теперь ML Space доступен для любых коммерческих пользователей, образовательных и научных организаций.
«ML Space — это настоящий технологический прорыв в области искусственного интеллекта. По ряду ключевых параметров ML Space уже превосходит лучшие решения в мире. Я считаю, что на сегодняшний день ML Space — одна из лучших облачных платформ для машинного обучения в мире. Он предоставляет опытным специалистам по данным новые удобные инструменты, возможность распределенной работы, автоматизацию создания, обучения и развертывания моделей ИИ. Компаниям и организациям, не имеющим сильного опыта в области машинного обучения, ML Space впервые дает возможность использовать ИИ в своих продуктах, приложениях и рабочих процессах», — говорит Отари Меликишвили, руководитель отдела разработки облачных ИИ-продуктов SberCloud.
Облако помогает рынку все больше осваивать платформы данных, предлагая неограниченную вычислительную мощность, подтверждают аналитики Mordor Intelligence.
По мнению экспертов Anaconda, компании и самим специалистам потребуется время, чтобы созреть в широком использовании инструментов DS и получить результаты. Но прогресс уже налицо. «Мы ожидаем, что в течение следующих двух-трех лет наука о данных продолжит двигаться вперед и станет стратегической бизнес-функцией во многих отраслях», — прогнозирует компания.