Отказоустойчивая система автоматически обнаруживает отказавшие компоненты, затем очень быстро определяет причину отказа и перенастраивает эти компоненты.
Комплектование и тестирование отказоустойчивого компьютера на платформе AMD K8
Повышение надежности обработки и хранения данных требуется в различных областях применения компьютерных технологий — особенно в математических вычислениях, в организации хранения и передачи данных в локальных и глобальных сетях, в управлении машинами и процессами. Каждая область имеет свои требования к отказоустойчивости, которые определяют выбор соответствующих архитектурных решений.
Содержание:1. процессор и оперативная память с коррекцией ошибок 2. подсистема жестких дисков с RAID-массивом 3. системная плата 4. пример отказоустойчивого компьютера 5.
реклама
Повышение надежности обработки и хранения данных требуется в различных областях применения компьютерных технологий — особенно в математических вычислениях, в организации хранения и передачи данных в локальных и глобальных сетях, в управлении машинами и процессами. Каждая область имеет свои требования к отказоустойчивости, которые определяют выбор соответствующих архитектурных решений.
В этой статье под отказоустойчивым компьютером понимается такой, в котором не происходит повреждения данных в случае одного аппаратного сбоя и не происходит потери данных в случае одного аппаратного сбоя. Мы ограничимся вопросом целостности данных, не затрагивая тему «высокой доступности». То есть, компьютер не обязательно должен быть работоспособным в случае каждого отдельного аппаратного сбоя — но основное требование заключается в том, что все данные должны быть доступны при возобновлении работы. Требование отказоустойчивости данных распространяется и на данные, находящиеся в энергонезависимой памяти.
Такой отказоустойчивый компьютер может состоять как из специализированных «серверных» или «промышленных» компонентов, так и из более дешевых компонентов общего назначения, называемых «настольными». Мы рассмотрим последний вариант.
1. процессор и оперативная память с коррекцией ошибок
реклама
var firedYa28 = false; window.addEventListener(‘load’, () =>
Как известно, распространенные «серверные» и «настольные» процессоры используют одно и то же процессорное ядро, которое имеет встроенные функции коррекции ошибок — в частности, защиту встроенной скрытой памяти с помощью кодов четности и коррекции ошибок (ECC). Четность обнаруживает одиночные ошибки, а ECC может исправлять одиночные ошибки и обнаруживать двойные ошибки в 64-битном пакете.
Основное различие между «серверными» и «настольными» процессорами заключается в интерфейсах передачи данных. Классические «серверные» процессоры AMD Opteron 2xx и 8xx 1) могут работать в многопроцессорной системе и 2) рассчитаны на использование регистровой памяти с ECC. Объем памяти Ledger может составлять 16-64 Гбайт и более в зависимости от количества процессоров.

Модуль оперативной памяти mi
Прежде всего, следует сказать, что в этой статье мы говорим о технологиях, которые повсеместно распространены и используются абсолютно на всех серверных платформах, независимо от того, какому провайдеру они принадлежат. Помимо описанных ниже технологий, существует, конечно, множество «собственных» решений, которые разрабатываются и совершенствуются самими поставщиками серверов и представляют собой их личное ноу-хау. В этом обзоре мы не будем углубляться в технологические портфели Intel, HPE, Lenovo и других крупных вендоров, а сосредоточимся только на общих для всех них технологиях.
Аппаратные средства достижения отказоустойчивости
Технология кода коррекции ошибок (ECC) проверяет данные, поступающие из базы данных на жестких дисках в основную память, поскольку неконтролируемая замена нулей и единиц в последующей доставке данных для обработки процессором может привести к масштабным сбоям и даже повреждению самой базы данных, если данные были переданы по ошибке.
ECC-память и коррекция ошибок
В случае такого сбоя базу данных, конечно, можно восстановить, используя различные программные средства операционной системы, некоторые из которых являются встроенными. Но гораздо эффективнее и правильнее не доводить дело до такого состояния, чтобы не пришлось иметь дело с последствиями. По этой причине в основную память сервера встроен модуль ECC, который проверяет и исправляет ошибки данных. О том, как это делается, мы поговорим далее.
Подводя итог, можно сказать следующее. Каждый 8-битный фрагмент информации (единицы и нули), передаваемый с жестких дисков в оперативную память, сопровождается символом, содержащим контрольную цифру — сумму переданных единиц.
Модуль кода коррекции ошибок (ECC) сравнивает информацию о том, сколько данных должно было поступить, с суммой фактических данных. Если «баланс равен», то единицы не теряются. Если это не так, то происходит ошибка, и вместо единицы выдается ноль, или наоборот.
Очевидно, что этот линейный метод подходит только для обнаружения одной ошибки. Если есть две ошибки или четное количество ошибок (например, если в строке были перезаписаны нули и единицы), сумма перезаписанных нулей и единиц все равно дает правильное число, и система может не заметить ошибку и считать данные правильными. Чтобы избежать этого, данные представляются в табличной форме, причем единицы и нули сопоставляются друг с другом не только строка за строкой, но и столбец за столбцом, что снижает риск ошибок, которые часто остаются незамеченными.
При обнаружении ошибки ECC отделяет поврежденные данные от остальных, выдает сообщение об ошибке и начинает повторную проверку, посылая устройству повторные запросы на тот же набор данных. Na
Тем временем технология коррекции ошибок ECC стала гораздо более зрелой, поскольку все производители серверных компонентов, от накопителей до памяти и процессоров, пытались улучшить ее для повышения производительности системы и уменьшения задержки. Обработчики данных научились «запоминать» правильные последовательности битов для данных, с которыми они «общаются» на регулярной основе, что позволяет избежать ошибок в первую очередь. Этот принцип лежит в основе машинного обучения, которое занимает второе место после искусственного интеллекта.
Надежность серверного оборудования достаточно хорошо описывается статистикой отказов определенных узлов. Такая статистика очень полезна для операторов систем, поскольку позволяет:
Отказоустойчивость компонентов серверов
Ниже приведена статистическая информация по гарантийным случаям. Проще говоря, мы попытались собрать данные о том, какие аппаратные компоненты на серверах выходят из строя чаще всего.
- оценивать потенциальную эффективность сервера;
- заранее создавать наборы компонентов для быстрого восстановления в случае выхода из строя;
- видеть, какие узлы заслуживают наибольшего внимания;
- оценивать возможные риски.
Слово статистике
Как видно из диаграммы, процент отказов выше всего у жестких дисков из-за ненадежности производства и человеческого фактора: это когда жесткий диск упаковывается с условно совместимыми жесткими дисками в надежде, что они «справятся», что в итоге увеличивает статистику.
Второе и третье места в антирейтинге делят блоки питания и материнские платы, опять же не всегда из-за недостатков конструкции. Незначительные неисправности в сети питания или конфигурации (например, неправильная настройка BIOS) приводят к тому, что компоненты либо отправляются на ремонт, либо отбраковываются.
Мораль в данном случае проста: любое оборудование требует соблюдения мер безопасности и условий эксплуатации, и это не просто теория — эти требования строго определены (о требованиях к серверным комнатам мы писали в отдельной статье). Даже самое высококачественное оборудование не застраховано от человеческих ошибок. Если вы хотите, чтобы количество отказов компонентов было меньше, не стоит игнорировать инструкцию по эксплуатации.
Оценивая данные на графике, можно также сделать интересное наблюдение. Наиболее сложные и чувствительные компоненты серверных систем — процессоры — сравнительно наименее подвержены сбоям. Статистика показывает, что они являются одними из самых отказоустойчивых серверных компонентов. Если задаться вопросом, чем обусловлена эта особенность, то сразу станет ясно, что это вопрос качества.
Критерии выбора оборудования
Исторически сложилось так, что 98% рынка серверных процессоров находится в руках мега-монополистов: Intel и AMD, которые сосредоточены на надежности собственных решений. Это не то же самое, что другие поставщики
Учитываются даже самые мелкие детали, такие как конструкция стеблей и крепежных элементов. Большое внимание уделяется энергоэффективности и охлаждению, не говоря уже о стресс-тестах, используемых для выявления мельчайших дефектов уже на производстве. Ведущие бренды вышеупомянутых компаний вкладывают значительные средства в тестирование своей продукции перед выпуском ее на рынок, и эти меры предосторожности дают оправданный эффект: эти устройства готовы выдержать широкий спектр сценариев и режимов работы в любых условиях.
Трудно вывести формулу надежности таких высококлассных продуктов, как серверы, но мы знаем, как обеспечить долговечность: правильное использование аппаратных функций и качество платформ и компонентов, которые лучше всего приобретать у поставщиков, заслуживших максимальное доверие клиентов своими решениями по обеспечению доступности.
Вам трудно выбрать надежное и качественное серверное оборудование? Тогда обратитесь к опытным специалистам Marquette.Marvel. Просто закажите консультацию, чтобы получить исчерпывающую информацию.
Заключение
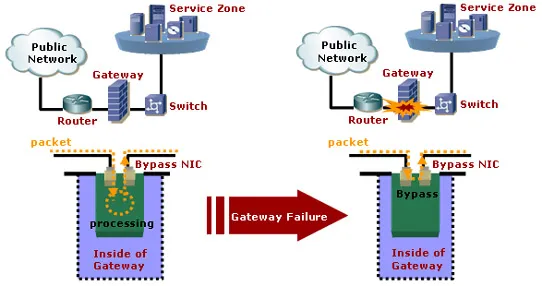
Эти карты в основном устанавливаются на серверы Common Bridge: Брандмауэры, IPS, IDS, DPI, серверы доступа, шлюзы и другие сетевые устройства, отключение которых может привести к краху всей сети. В режиме обхода вы можете обеспечить доступность сети, блокируя только ту функцию, за которую отвечало вышедшее из строя устройство. Например, если эта сетевая карта используется в системе DPI, абоненты провайдера могут по-прежнему иметь доступ к сети в случае отключения питания, но управление трафиком, фильтрация URL и другие функции DPI теряются.
Функция обхода для шлюза доступа в Интернет
Применение режима Bypass
Телекоммуникационные компании и интернет-провайдеры также активно используют функцию обхода для проведения планового обслуживания серверов с такими картами. В этом случае вам не придется перенаправлять трафик в обход сетевого оборудования; вы можете просто выключить сервер и заменить компоненты.
На российском рынке широко представлены обходные адаптеры израильского производителя Silicom, который предлагает решения для 1-, 10- и 40-гигабитных сетей с оптическими и медными интерфейсами.
Производитель использует в своих платах современные чипы Intel:
Bypass-адаптеры на рынке
Silicom PE340G2BPI71 — обходная карта 40G.
Все адаптеры Silicom обладают функцией обхода в случае сбоя питания, ошибки сервера или программного обеспечения. Администратор устанавливает режим обхода для каждого порта и определяет время задержки перед переключением.
- топовый чип Intel® XL710 с поддержкой двух портов 40G, шиной PCI Express X8, поддержкой QoS, Virtual Machine Device queues (VMDq), PCI-SIG* SR-IOV и Intel® Data Direct I/O Technology;
- чип для медных сетей Intel® x540 c поддержкой двух портов 10G, шиной PCI Express X8, всех функций для виртуализации сетей, а также iSCSI, FCoE, NFS;
- чип для оптических сетей Intel® 82599ES c поддержкой двух портов 10G, Virtual Machine Device queues (VMDq), Fiber Channel over Ethernet, MACsec IEEE 802.1 AE, Intel® Data Direct I/O.

Также доступны оригинальные карты Intel NIC Bypass, карты Dell SonicWALL и карты SonicWALL других американских и восточных производителей. Однако наибольшей популярностью пользуется Silicom.
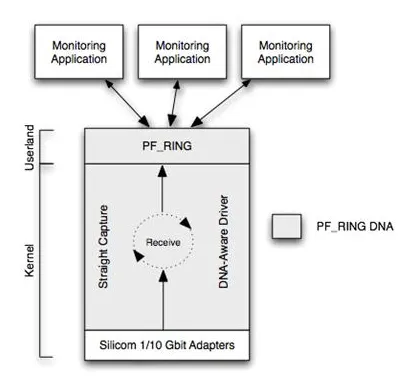
Некоторые адаптеры Silicom (на базе чипов Intel 82598/99) поддерживают уникальную сетевую функцию DNA (Direct NIC Access), которая позволяет системам DPI получать пакеты непосредственно от сетевого адаптера (без взаимодействия с ядром Linux) с минимальной нагрузкой на процессор, не проходя через ядро Linux.
Работа с ДНК на адаптерах Silicom
Платформа СКАТ DPI может быть установлена на любом сервере x86. Однако если система подключена к разделенному каналу, для обеспечения стабильной работы сети необходимо использовать сетевые адаптеры с поддержкой режима обхода. Мы рекомендуем использовать адаптеры Silicom с требуемыми характеристиками благодаря их надежности и стабильности в работе.
Для получения дополнительной информации о преимуществах SCAT DPI, эффективном развертывании в сетях операторов и миграции с других платформ обращайтесь к VAS Experts, разработчику и поставщику системы анализа трафика SCAT DPI.
Кластеризация сетевых карт или агрегация сетевых адаптеров — это отказоустойчивость на аппаратном уровне для серверов. Обычно эта проблема решается путем установки дополнительных драйверов, создания виртуального сетевого адаптера, а затем добавления физического сетевого адаптера для создания агрегации (группы).
В большинстве случаев такая агрегация действует как пара активный/пассивный, и пассивный сетевой адаптер активируется, когда активный сетевой адаптер теряет пропускную способность. Однако возможны отклонения, если поддерживается 802.3ad. Как и в случае EtherChannel, эквализация может быть уже активирована.
NIC teaming
На уровне 3 модели OSI расположены протоколы HSRP и VRRP. Это протоколы, обеспечивающие отказоустойчивость на сетевом уровне. Если шлюз по умолчанию (внутри подсети) выходит из строя, ни один узел в этой подсети не сможет получить доступ к чему-либо за пределами своего сегмента. Эти два протокола (HSRP и VRRP) предназначены для настройки дополнительного маршрутизатора (или коммутатора L3) в качестве резервного, если основной выходит из строя. Если основной шлюз недоступен, он немедленно заменяется резервным без уведомления клиентов.
Эти протоколы не только обеспечивают отказоустойчивость, но и помогают проводить обновление оборудования и программного обеспечения с минимальным воздействием на клиентов в обычное рабочее время. Наиболее известными протоколами, относящимися к этой группе, являются HSRP, VRRP и GLBP. Протокол HSRP (Hot Standby Router Protocol) существует уже давно (с 1994 года) и является собственным решением компании Cisco. VRRP (Virtual Router Redundancy Protocol) — это открытый протокол (представлен в 1999 году), текущая версия определена в RFC 5798. Хотя этот протокол позиционируется как открытый стандарт, Cisco утверждает, что аналогичный протокол был запатентован и лицензирован. И хотя патентные претензии не предъявлялись, открытость VRRP остается под вопросом. А GLBP (Gateway Load Balancing Protocol), относительно новый протокол (разработанный компанией Cisco для Cisco в 2005 году), отличается от предыдущих протоколов, как следует из названия, тем, что поддерживает балансировку нагрузки, а также отказоустойчивость.
HSRP & VRRP
Но сегодня мы подробно рассмотрим протокол HSRP, уделив особое внимание его безопасности.
HSRP может использоваться для двух или более маршрутизаторов (шлюзов), один из которых активен, другой находится в режиме ожидания, а остальные — в режиме ожидания. Следует отметить, что этот протокол не очень масштабируем. Это связано с тем, что если активный маршрутизатор бомбардируется пакетами, спрашивающими его, активен ли он еще или нет, он определенно выйдет из строя. MAC-адрес активного устройства генерируется автоматически, а виртуальный IP-адрес назначается вручную. В результате тот, который стал активным, отвечает на ARP-запросы через виртуальный IP, посылая ARP-ответ с виртуальным маком.
Если резервный маршрутизатор не видит активный маршрутизатор в течение определенного времени (в зависимости от настроек таймера), он объявляет себя активным и начинает отвечать. Для таких проверок используются пакеты Hello, отправленные на многоадресный адрес 224.0.0.2. Обратите внимание, что HSRP версий 2 и 1 технически несовместимы, так как их трафик идет на разные IP-адреса (см. врезку). Давайте оставим теорию в стороне и перейдем к делу.