В нашем списке все выражения используются довольно часто. Однако бывает и так, что люди просто не используют многие из этих выражений для поиска. Так зачем их собирать? Ответ прост: чтобы ничего не пропустить. На следующих этапах, когда мы будем рассматривать частоту, мы просто удалим те, у которых нулевая или очень низкая частота.
Что такое семантическое ядро?
Семантическое ядро (СЯ) — это отсортированный набор слов, морфологических форм и фраз, которые наиболее точно описывают вид деятельности, товары или услуги, которые предлагает сайт. Это слова, которые вы будете использовать для продвижения своего сайта.
На основе разработанного сем.ядра будет сформирована окончательная структура сайта: В зависимости от выбранных ключевых слов станет ясно, какие новые страницы следует добавить на сайт, а какие можно удалить.
После сбора и очистки семантики необходимо разделить ключевые слова на страницы. Для этого необходимо собрать топы каждой фразы, а затем найти одинаковые URL-адреса. Какой порог группировки вы установили — столько повторяющихся URL, что ключевые фразы попадают в одну группу.
Что такое семантическое ядро простыми словами
Удивительно, но семантическое ядро — это файл Excel, в котором перечислены ключевые слова, которые вы (или ваш копирайтер) будете использовать при написании статей вашего сайта.
Например, вот как выглядит мое семантическое ядро:
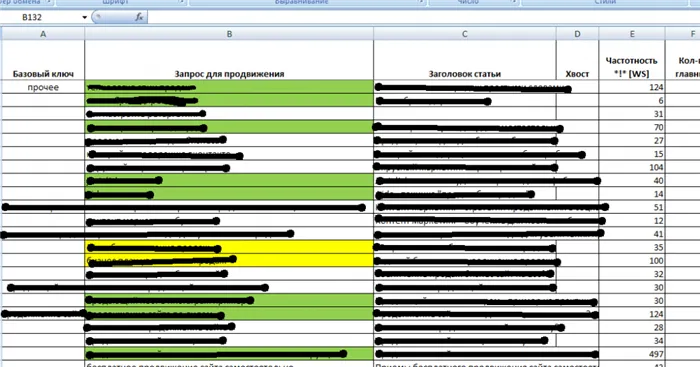
Зеленым цветом я отметил ключевые слова, для которых я уже написал статьи. Желтые — те, для которых я буду писать статьи в ближайшем будущем. Бесцветная клетка — означает, что они будут представлены немного позже.
Для каждого ключевого слова я задал частоту, конкурентоспособность и «броский» заголовок. Примерно такой же файл должен быть у вас. Теперь у меня есть SNR, состоящий из 150 ключевых слов. Это означает, что у меня впереди еще как минимум 5 месяцев «материала» (даже если я буду писать по одной статье в день).
Чуть позже мы поговорим о том, что нужно подготовить, если вы вдруг решите заказать сборник семантических ядер у специалистов. Для этого позвольте мне кратко сказать, что вы получите тот же список, но только для тысяч «ключей». Однако KN — это не количество, а качество. На этом мы и сосредоточимся.
Зачем вообще нужно семантическое ядро?
И зачем нам, собственно, нужны все эти проблемы? Вы можете просто писать качественные статьи и привлекать аудиторию, не так ли? Да, вы можете написать их, но вы не сможете их привлечь.
Главная ошибка, которую допускают 90% блоггеров, заключается в том, что они пишут только качественные статьи. Я не шучу, у них действительно интересный и полезный материал. Но поисковые системы этого не знают. Они не экстрасенсы, они просто роботы. Следовательно, ваша статья не будет занимать первое место.
В названии содержится еще одна тонкая подсказка. Например, у вас есть очень качественная статья на тему «Как вести бизнес в «мордокниге»». В нем вы очень подробно и профессионально описываете все, что касается Facebook. В том числе о том, как продвигать там сообщество. Ваша статья — лучшая, самая полезная и интересная в интернете на эту тему. Никто даже близко к тебе не подходит. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на вашем сайте не робот, а живой чекер (оценщик) из Яндекс. Он определил, что у вас самая красивая статья. И своими руками он вывел вас на первое место в поиске по запросу «Продвижение сообщества в Facebook».
Знаете ли вы, что тогда происходит? Вы все равно очень скоро выйдете оттуда. Потому что никто не кликнет на вашу статью, даже отдаленно. Люди набирают запрос «продвижение сообщества в Facebook», а ваш заголовок — «как правильно вести бизнес на мордокниге». Это оригинально, это свежо, это смешно, но…. это не соответствует запросу. Люди хотят видеть именно то, что они искали, а не ваше творчество.
Следовательно, ваша статья будет потеряна в верхней части поисковой системы. А живой рецензент, фанатичный поклонник вашего творчества, может сколько угодно умолять начальство хотя бы сохранить вас в первой десятке. Но он этого не сделает. Все первые места будут пусты, как миска с семечками, статьи, переписанные вчерашними студентами.
Но эти статьи будут иметь правильный «релевантный» заголовок — «Продвижение сообщества на Facebook с нуля» (по шагам, 5 шагов, от А до Я, бесплатно и т.д.) Это не обидно? Конечно, есть. Поэтому боритесь против несправедливости. Давайте создадим грамотное семантическое ядро, чтобы ваши статьи заняли первое место, которого они заслуживают.
Как правильно составить семантическое ядро за 5 шагов
Шаг #1 – Подбор базовых “ключей”
Сначала мы займемся увлекательным и интересным делом — сбором ключевых слов. Это очень широкие поисковые запросы, которые набирают десятки или сотни тысяч просмотров в месяц. Вы должны решить, на какие темы вы хотите писать в целом, и использовать названия этих тем в качестве ключевых слов.
И это увлекательное занятие, потому что уже на этом этапе вы можете определить, правильно ли вы выбрали тему для своего сайта или нет. Вы можете придумать 1-2 общих штриха к ключевому слову и на этом закончить.
Это значит, что через месяц-другой вы обнаружите, что вам буквально не о чем писать. А это значит, что вам срочно нужно изменить свой маркетинговый план и мыслить в другой нише.
Например, вот ключевые слова, которые я включил для своего блога, где вы сейчас находитесь:
- Копирайтинг
- Вебинары
- smm
- seo
- яндекс директ
- ссылка
- Продвижение сайтов
- ваша компания
- Интернет-маркетинг
- Продажа
- …
Я собрал три десятка таких ключевых слов. А это значит, что я никак не могу остаться без тем для статей. Если в вашей нише все то же самое, нет проблем. И пусть вас не беспокоит, если по вашей теме уже есть сотни сильных сайтов, которые рекламируются десятилетиями и плотно занимают весь топ-10 (как вы думаете).
Если в нише много конкурентов, значит, там есть деньги. И если есть много широких ключей, вы можете «захватить» хотя бы часть этого трафика. Напротив, сейчас мы научимся выбирать правильные ключевые слова, которые позволят вам быстро выйти в лидеры и обогнать всех своих конкурентов.
Где найти базовые ключевые запросы
Начните с поиска в своей голове. На листе бумаги напишите не менее 3-5 тем, по которым вы могли бы предоставить интересную и полезную информацию. Затем зайдите в Yandex Wordstat и выполните поиск статей.
Вы увидите подсказки в правой колонке — «Запросы, похожие на …».
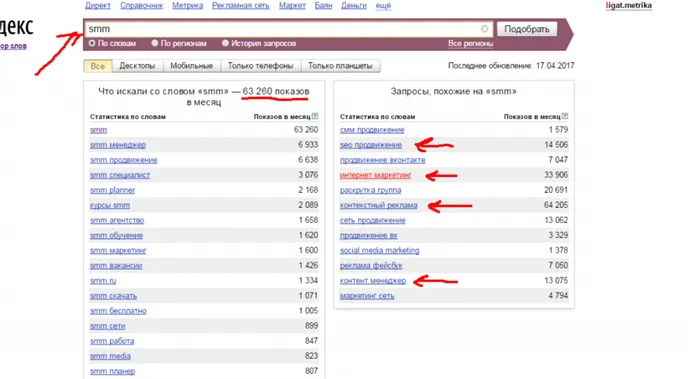
Я набрал в поисковой строке одно из своих основных ключевых слов — «smm», и Яндекс тут же выдал мне двенадцать советов, которые могут быть интересны людям, интересующимся «smm». Все, что мне нужно сделать, это скопировать эти советы в свой блокнот. Затем я проверю каждого из них таким же образом и соберу советы и для них.
После первого этапа сбора SNR у вас должен быть текстовый документ с 10-30 общими ключевыми словами, с которыми мы будем работать дальше.
Шаг #2 – Парсинг базовых ключей в SlovoEB
Если вы напишете статью для поискового запроса «вебинар» или «smm», чуда, конечно, не произойдет. Вы никогда не сможете попасть в топ по такому широкому поисковому запросу. Вам необходимо разделить главный ключ на множество более мелких вопросов по этой теме. И мы сделаем это с помощью специальной программы.
Я использую KeyCollector, но он платный. Вы можете воспользоваться бесплатным аналогом — программой СловоЕБ. Вы можете загрузить его с официального сайта.
Самое сложное в этой программе — правильно ее настроить. Здесь я покажу вам, как правильно настроить и использовать SlovoEB. Но в этой статье я сосредоточусь на выборе ключей для Яндекс Директ.
Стоит ли заказывать СЯ у специалистов?
Как правило, эксперты по семантическому ядру выполняют только шаги 1 — 3 нашей системы. Иногда, за большую дополнительную плату, делают и шаги 4-5 — (для сбора остатков и проверки конкурентоспособности запросов).
После этого вы получаете несколько тысяч ключевых слов для дальнейшей работы.
И здесь встает вопрос, писать ли статьи самому или нанять для этого копирайтеров. Если вы хотите уделять больше внимания качеству, чем количеству, вы должны делать это сами. Но в этом случае недостаточно просто дать вам список ключевых слов. Вы должны выбрать темы, в которых вы разбираетесь достаточно, чтобы написать качественную статью.
И здесь возникает вопрос — а зачем тогда, собственно, нужны эксперты по СН? Согласен, проанализировать ключевое слово и уловить точную частоту (шаги 1-3) — это несложно. Это займет буквально полчаса.
Самое сложное — выбрать RF-запросы с низкой конкуренцией. А теперь выясняется, что вам также нужны высокочастотные НК, для которых можно написать хорошую статью. Именно на это у вас уйдет 99% времени при работе над семантическим ядром. И ни один специалист не сделает это за вас. Так действительно ли стоит передавать такие услуги на аутсорсинг?
Когда услуги специалистов по СЯ полезны
Другое дело, если вы планируете нанять копирайтеров на начальном этапе. Тогда вам не нужно понимать объем запроса. Ваши копирайтеры тоже этого не поймут. Они просто возьмут несколько статей по теме и составят из них «свой» текст.
Эти статьи будут пустыми, дрянными и почти бесполезными. Но их будет много. Самостоятельно вы можете писать не более 2-3 качественных статей в неделю. А армия копирайтеров будет обеспечивать вас 2-3 дрянными текстами в день. Кроме того, они оптимизированы под поисковые запросы, а значит, привлекут больше посетителей.
В этом случае вы можете нанять экспертов SN. Пусть они расскажут вам больше, и в то же время ТК для копирайтеров будет увеличиваться. Но вы знаете, что это также будет стоить определенных денег.
Кроме того, они полностью убирают частоту. В ближайшее время я напишу подробную статью о том, как пользоваться этим сервисом (UPD 2017 — вот он! 🙂 ).
Способы составления семантического ядра
Key Collector
Чтобы написать семантику, мы можем использовать программы для создания SN. Некоторые из них делают почти всю работу за вас — их еще называют автоматическими. При использовании некоторых услуг вам придется приложить больше усилий самостоятельно.
Например, существует платная утилита под названием Key Collector. Хотя этот процесс почти полностью автоматизирован, вам необходимо знать, как настроить Key Collector. На выходе вам просто нужно немного почистить запросы, удалив самые бесполезные, например, запросы от роботов, спам и т.д. Стоимость такой программы составляет почти 2 000 рублей.
Яндекс Вордстат
Вы также можете собирать семантическую информацию с помощью сервиса Wordstat от Yandex. Он очень прост в использовании, просто введите ключевое слово, и он покажет вам поисковые запросы, в которых встречается это ключевое слово. Кроме того, Wordstat также показывает похожие поисковые запросы, что также может быть интересно при рекламе.
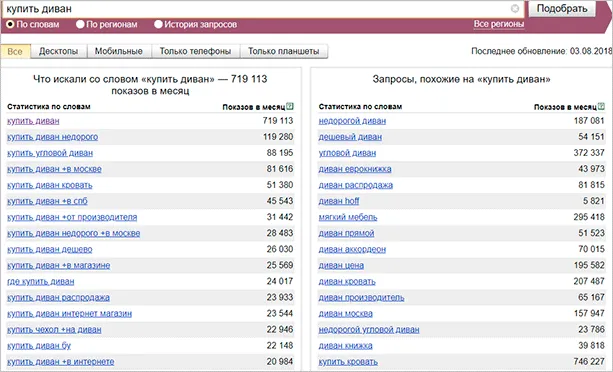
В этой статье мы будем использовать Wordstat для сбора первичных ключевых слов, которые нам понадобятся для дальнейшего составления семантического ядра. Но об этом подробнее позже, а сейчас я дам вам еще несколько способов сбора семантики.
Яндекс Вордстат + СловоЁБ
Программа с таким красочным названием является абсолютно бесплатным аналогом Key Collector. Конечно, и функциональности в нем чуть меньше, чем в коммерческом конкуренте, но для сбора семантического ядра для продвижения поиска этого вполне достаточно.
Если вы хотите узнать, чем SlovoYob отличается от Key Collector, посмотрите на эту таблицу.
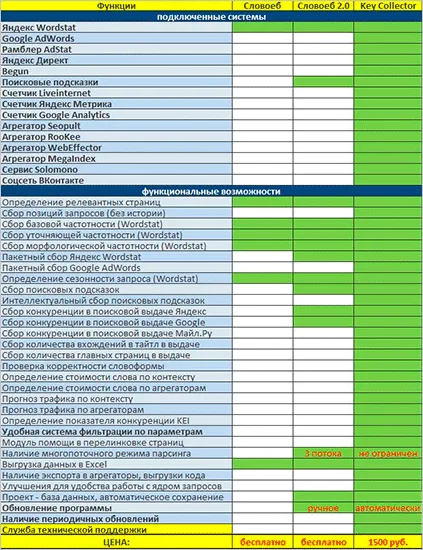
Конечно, есть несколько отличий. Но для простой основной коллекции возможностей SlovoYOB вполне достаточно.
Онлайн-сервисы
Таким образом, в дополнение к вышеперечисленным вариантам, семантика также может быть выполнена с помощью веб-сервисов. Если вы наберете поисковый запрос «коллекция веб-семантики», поисковая система выдаст вам множество различных веб-инструментов. Они могут быть как хорошими, так и плохими. Соответственно, они могут быть как платными, так и бесплатными.
С помощью различных веб-сервисов вы также можете узнать семантическое ядро ваших конкурентов. Будьте уверены, что почти все компании заняты проверкой данных своих потенциальных конкурентов.
Заказ у специалиста
Вы можете просто купить готовое решение у эксперта. Он сделает все, и на выходе вы получите полный файл со всеми запросами. Более того, уже сейчас можно создать список предметов с их техническими требованиями. Ну, и оставить все на милость копирайтеров. Но это вопрос постановки задачи, в который мы сегодня не будем углубляться.
Стоит ли составлять семантику?
Если вы открыли эту статью, то, очевидно, вас также интересует этот вопрос. Сбор семантических данных поначалу кажется очень утомительной и сложной задачей. И пользователи не всегда понимают, зачем им это вообще нужно.
Если речь идет о блоге, который должен зарабатывать деньги, то перед авторами таких проектов встает закономерный вопрос о том, откуда черпать вдохновение и на какую тему писать. Если у вас есть готовая таблица со всеми темами и ключевыми словами, вы будете точно знать, о чем писать. Таким образом, вы сможете не только сохранить темп, но и увеличить его, поскольку вам не придется думать о теме следующей статьи. Вам остается только выбрать из списка предложений и решить для себя, как написать тот или иной материал.
Кроме того, все ваши статьи (при условии, что они грамотно написаны и соответствуют частоте ключевых слов) будут хорошо отображаться в верхних результатах поиска, что обеспечит вам трафик, который будет еще больше подогревать ваш интерес и мотивировать вас делать что-то новое. Заманчиво, не правда ли? И все это благодаря одному элементу — семантике, — который не займет у вас много времени.
Для коммерческих веб-сайтов (целевых страниц, интернет-магазинов и т.д.) улавливание семантического ядра имеет большое значение. Серьезно, без этого не обойтись. Семантика нужна как для наполнения ресурса контентом и метатегами, так и для контекстной рекламы, которую вы хотите использовать для продвижения своего бизнеса.
Чтобы собрать семантику для контекста, SlovoEB будет недостаточно. Вам необходимо приобрести расширенную версию под названием Key Collector. Программа имеет большое количество различных опций, специально разработанных для работы с различными рамочными сетями (Direct, Adwords и т.д.).
В целом, Semantics определенно стоит того. Это повышает качество рекламы вашего ресурса и позволяет гораздо лучше узнать потребности пользователей в плане оформления контента.
Как видите, семантическое ядро можно составить всего за 5 шагов. Конечно, в данном руководстве представлена базовая версия, которая позволит вам изучить основы и применить простейшую семантику. Для более серьезных проектов нужен соответствующий подход. Например, при группировке ключевых слов следует разделять их не только на HF и LF или VC и NC, но и на коммерческие и некоммерческие. Или даже в группы по региональному признаку.
Все это, конечно, займет некоторое время, но если вы сами будете работать над семантикой, собирать ее и смотреть, как развиваются события на рынке поисковых систем в целом, то со временем вы это поймете. Вы будете находить все больше и больше инструментов для различных процессов, сможете на одном дыхании упоминать семантический сбор и кластеризацию. Конечно, если вы заинтересованы.
Если вы не хотите заниматься этим самостоятельно, вы всегда можете заказать сбор семантического ядра у фрилансера или студии. В Интернете полно различных агентств, готовых скопировать все данные и просто предоставить вам файл Excel. Цена может варьироваться. Кстати, если вы что-то не поняли в этой статье и не можете разобраться, как собрать семантическое ядро, должен заметить, что в курсе Василия Блинова «Как создать блог» эта тема также рассматривается. Возможно, вам стоит посетить курсы и приобрести необходимые знания.
Если делать это вручную, можно буквально сойти с ума. А чтобы не нарушать психологию, я бы посоветовал вам использовать автоматизированные сервисы для разделения всех ключевых слов на группы.
Как составить семантическое ядро
Система проста: вам нужно определить бренды и расширить их.
Индексные запросы обычно представляют собой RF-фразы, которые описывают раздел или подраздел каталога на сайте. Они часто формируют заголовок H1 страницы. Проще и эффективнее собирать показатели у конкурентов, чем у топ-10. Анализируя их SN и структуру, вы получаете основу, которую затем можно расширять и улучшать.
Если ваш интернет-магазин имеет широкий ассортимент товаров, вам следует начать SEO-оптимизацию с сегментов, приносящих наибольшую прибыль (не забывайте о сезонности).
Для раздела «ховеры» это будут индикаторы:
- Робот-уборщик,
- Мытье,
- Вертикальные пылесосы.
Затем добавьте к показателям синонимы и альтернативные названия услуг и продуктов.
- Двигатель — двигатель,
- Механизм управления — газораспределительный механизм.
Составленный список лексем еще не является семантическим ядром. Его нужно расширить облаком запросов — менее частых и более понятных фраз. Обычно они состоят из маркера и некоторых идентифицирующих слов. Их захват может быть автоматизирован.
Сервисы для составления семантического ядра
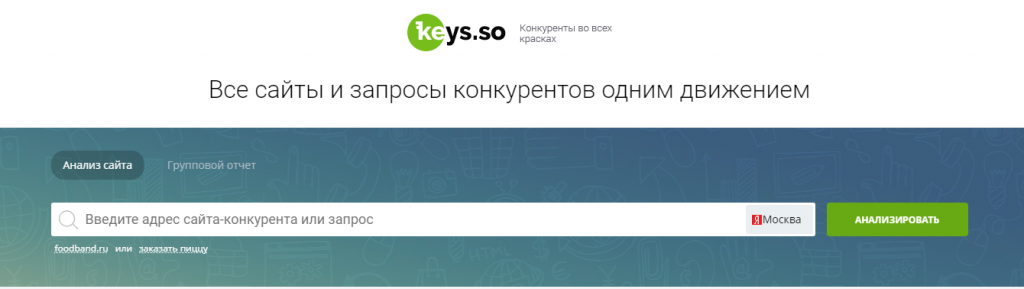
Сбор семантики и анализ семантического ядра конкурентов с помощью онлайн-сервисов
Key.so помогает вам тратить SN конкурентов и даже сравнивать различные сайты по общим и не пересекающимся ключевым словам. Стоимость от 1 500 рублей в месяц.
Bookvarix может как расширить SN с помощью ваших индексов, так и уловить семантику конкурентов. Стоимость от 695 рублей в месяц. Существует бесплатная версия с ограниченными возможностями.

Serpstat анализирует информацию о вашем сайте и сайтах ваших конкурентов с точки зрения семантики, рейтинга в поисковых системах и многих других факторов. Стоимость от $48 в месяц. Предусмотрен 7-дневный бесплатный пробный период.
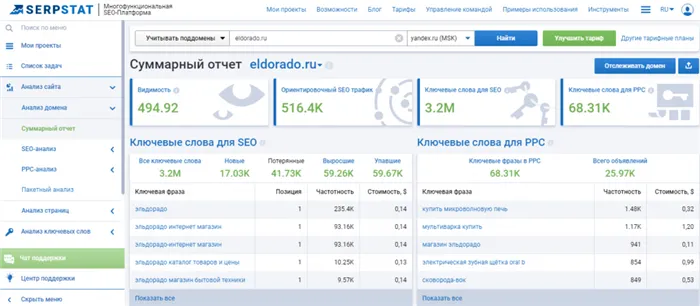
Ahrefs показывает ваш ссылочный профиль, а также вашу органическую и платную активность в поисковых системах. Стоимость от $99 в месяц. Существует 7-дневная бесплатная пробная версия.
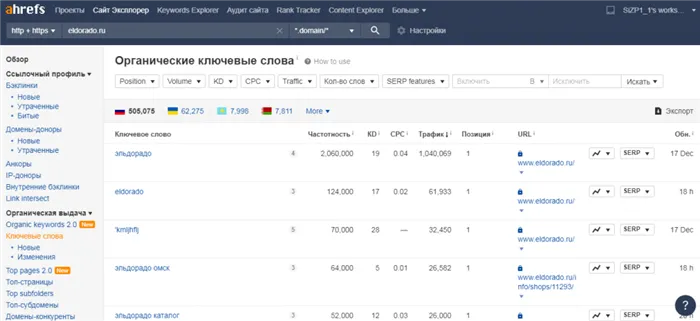
SemRush показывает сильные и слабые стороны ваших конкурентов, помогает анализировать семантику и делает предложения по более эффективному их развитию. Стоимость от $99,95 в месяц. Вы можете запросить бесплатную пробную версию.
Похожие сервисы с похожими функциями: Topvisor, JustMagic и Megaindex. Постарайтесь выбрать тот инструмент, который подходит вам больше всего.
Подбор семантического ядра — Wordstat Yandex
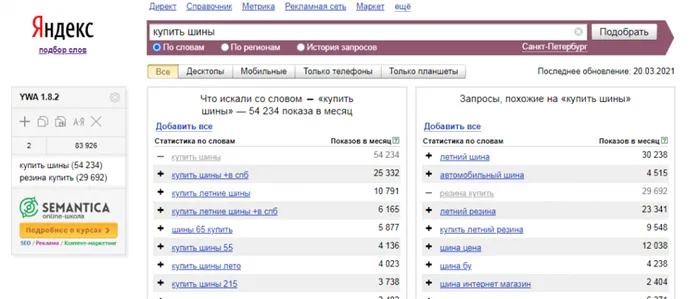
Yandex Wordstat — самый популярный способ работы с Semantic Core. Сервис предоставляет статистику по словам в каждом регионе и сезонности. Для точной оценки потребностей мы рекомендуем использовать дополнительные операторы.
Чтобы упростить сбор CJA, используйте расширения. Например, WordStater или Yandex Wordstat Assistant от Semantica с более простыми функциями.
Парсинг и кластеризация с помощью Key Collector
С помощью Key Collector вы можете автоматически собирать статистику, данные поиска из Yandex и Google. Для этого необходимо создать список наиболее важных брендов, который программа затем расширяет. Здесь также можно очистить ядро от стоп-слов и сгруппировать запросы. Key Collector имеет множество полезных функций, и если вы профессионально занимаетесь SEO-оптимизацией, то этот инструмент, несомненно, будет вам полезен.
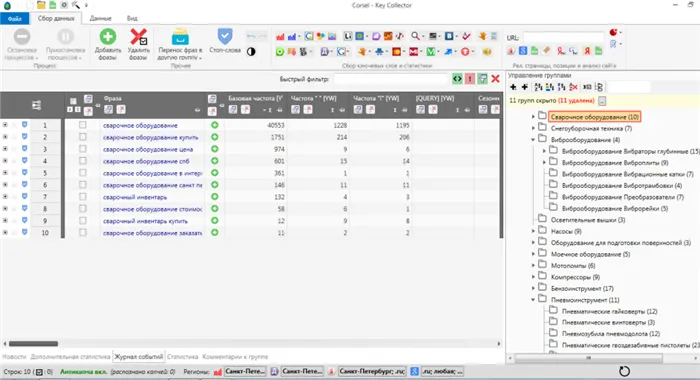
Съем частотностей с помощью Key Collector
Вы можете использовать этот сервис для сбора частоты поисковых фраз для поисковых систем Yandex, Google и Mail. Статистику Яндекса можно собирать двумя способами: через Yandex Wordstat или Yandex Direct. Мы уже говорили о первом варианте. Но второй собирает прогнозы из рекламного сервиса Яндекса и делает это гораздо быстрее. Используйте его, когда вам нужно собрать информацию для большого проекта. Для этого выберите «Собирать статистику Яндекс.Директ».
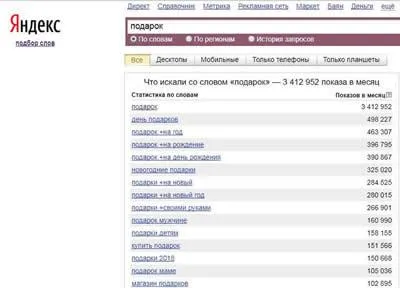
Какие ключевые слова не стоит брать
Часто первоначальный сбор данных CJ приводит к составлению длинного списка запросов. Вы можете смело удалять из него поисковые фразы:
- С грамматическими ошибками. Поисковая система сама исправляет фразу в своих результатах, когда пользователь допускает ошибку.
- С неактуальным доменом. Если речь идет о Москве, не принимайте запросы со ссылкой на Санкт-Петербург.
- С такими объявлениями, как «дешево», «со скидкой» и «предложения». Исключение: проект действительно имеет чрезвычайно низкие цены и подчеркивает это. В противном случае продвижение таких запросов негативно сказывается на поведенческих показателях.
- Не имеет отношения к представленным продуктам и услугам. Не включайте такие фразы, как «установка» или «производство», если вы продаете только продукцию.
- Использование бренда конкурента.
- Использование слова «лучший», если оно не подкреплено сертификатом (согласно Закону о рекламных стандартах).
В окончательный список ключевых фраз не включаются поисковые запросы с запросом 0. Для Москвы и Санкт-Петербурга минимальный порог может быть увеличен до 3. Однако если у вас узкая тема и это исключает многие ключевые слова, следует вернуться к минимальному порогу в 1.
Удалите список стоп-слов. Это можно автоматизировать, например, в Key Collector. Вам нужно задать список стоп-слов, и программа удалит все запросы, которые их содержат. Список зависит от тематики проекта, но помните, что есть стоп-слова, которые применимы ко всем коммерческим доменам. Пример: «своими руками», «фотография», «видео», «инструкция» и т.д.
Проверьте список на наличие тихих копий. Вы также можете сделать это в Key Collector или с помощью онлайн-сервисов: keys.so, bukvarix.com.
Если ключевых слов слишком много, можно отфильтровать их по KEI (автоматически рассчитывается в Key Collector). KEI — это индекс эффективности ключевых слов. Чем выше индекс, тем интенсивнее трафик термина, но тем сложнее попасть в топ-10.
После выбора и кластеризации семантического ядра вы должны получить два файла. Первый — это список запросов с частотой, разделенных на группы. Второй — дерево наиболее популярных запросов. Это ваш центральный элемент — поздравляю!
Семантическое ядро для Landing Page
Поскольку продвижение целевой страницы имеет свои особенности, ее ядро будет сильно отличаться от шаблона. Мы уже писали, что целевая страница должна фокусироваться на одном основном запросе и иметь небольшое дерево подзапросов. Семантическое ядро должно быть точно таким же.
То есть, прежде чем составлять ядро для целевой страницы, определите основной запрос, который полностью характеризует вашу деятельность. Помните, что это не должно быть высокочастотное, всеохватывающее и вполне подходящее конкретное ключевое слово. Например, в лендинге для продажи мебельного щита для MSK ключевые слова «щит» и «мебельный щит» не подойдут.
Определив главную ключевую фразу, найдите как можно больше похожих подзапросов. Это будет семантическое ядро вашей целевой страницы. Небольшой, но полностью описывает деятельность.
Поскольку все запросы будут очень похожи, не переусердствуйте с оптимизацией. Используйте синонимы, заменяйте местоимениями и т.д.
После создания проекта выполните основные операции. Для этого в интерфейсе программы нажмите на «Wordstat», введите ключевое слово и нажмите на «Начать сбор».
Проделав все вышеперечисленные манипуляции, мы соберем семантическое ядро вашего сайта, которое, во-первых, обеспечит нам запас тем для статей на неограниченный период времени, а во-вторых, даст нам отличный импульс для продвижения, потому что правильно составленное семантическое ядро — залог успеха вашего проекта.!
Итак, надеюсь, мне удалось ответить на вопрос, как правильно составить семантическое ядро своими руками, конечно, используя программу KeyCollector или SlovoEB.
В заключение хочу дать совет: сначала напишите хотя бы по одной статье для каждого заголовка вашего сайта, а еще лучше — напишите сразу 50-100 статей и поставьте их в очередь на публикацию (подробнее о том, как публиковать статьи на сайте, в отдельной статье). Это необходимо для того, чтобы в будущем вами не двигала необходимость написать статью в определенный день, потому что вы должны писать статьи в то время, когда вас посещает муза, а не делать это «постфактум».
Куда вставлять все эти фразы?!
Очень популярным вопросом среди начинающих является:
«Так много фраз, куда их все девать? Действительно ли необходимо описывать абсолютно все вопросы в точной записи в статье? Это слишком много спама!»
Конечно, не стоит размещать абсолютно все фразы и даже в точном виде на страницах сайта. Итак, основная цель семантического сбора — найти всевозможные словоформы и запросы, которые люди вводят в поисковые системы, чтобы получить релевантность конкретной страницы, заголовка и сайта в целом.
Как подробно использовать собранную семантику, я рассказываю в статье про SEO-оптимизацию, здесь же я лишь в общих чертах опишу, где разместить этот набор запросов.
В этом контексте мы используем только самые распространенные фразы в точном, но читабельном формате. Мы включаем их в метатеги:
Мы также стараемся использовать главную фразу в первом абзаце.
Мы отделяем низкочастотные фразы от основной ключевой фразы, чтобы получить хвосты. А хвосты равномерно распределены по всему тексту.
Таким образом, мы плавно распределяем все доступные, правильно и корректно собранные семантические ключевые слова по вашему ресурсу.
Резюме
- Назовите тему.
- На листе бумаги напишите несколько слов/фраз, связанных с темой, и опишите ее более подробно.
- Используйте KeCollector или SlovoEB для сбора семантического ядра.
- Фильтрация и удаление избыточных и недействительных запросов.
- Создайте титульный лист.
- Разделите ключевые слова на заголовки.
- Разделите заголовки на статьи.
- Структурированные подзаголовки для статей.
Я рекомендую вам прочитать мою статью о расширении семантического ядра сайта. В нем содержится много полезной информации, которая позволит вам собрать большое количество низкочастотного и среднечастотного трафика по ключевым словам ваших конкурентов.
Оцените статью, задавайте вопросы!
Ad. Продвигайте свой сайт с помощью автоматизированных методов от Rookee:
Автор блога о SEO и заработке на сайтах — Vysokoff.ru и Telegram-канала t.me/vysokoffru. Я занимаюсь продвижением информационных и коммерческих сайтов с 2013 года и являюсь экспертом по следующим темам: Маркетинг, предпринимательство, финансы и инвестиции на Yandex.Q. Автор и преподаватель курсов «Капитализация знаний» и «Комплексное поисковое продвижение сайтов» в GeekBrains.
Процесс запущен, и программа начинает поиск запросов, содержащих нужные термины. Само собой разумеется, что чем больше таких фраз, тем больше запросов будет в выдаче. Например, я ввел запрос «заработать деньги в интернете», а затем запустил процесс. Вот данные, которые предоставила мне программа.
Шаг 6. Расширяем ядро с помощью поисковых подсказок
После отображения мы начинаем расширять нашу семантику. Существует несколько способов сделать это. Первый — сбор данных о поиске через Wordstat.Yandex. То есть, правая колонка. Он показывает, какие термины ввели пользователи и что еще их интересует.
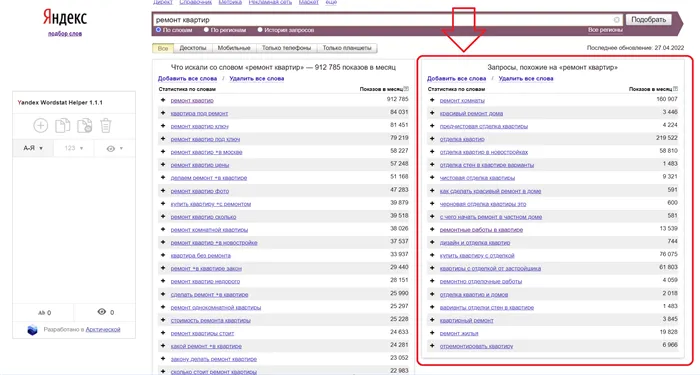
Второй метод — это анализ поисковых подсказок с помощью специальных программ.
Эти всплывающие подсказки помогут вам расширить свое ядро за счет наиболее релевантных запросов, которые часто используют пользователи.
Существует несколько популярных программ для сбора ключевых слов. Во всех случаях собранную семантику можно загрузить и добавить в электронную таблицу.
Арсенкин. бесплатно, есть возможность собирать подсказки только по 100 запросам в день и только на Яндекс. Google и Advanced Limits — это платная программа.
Основной коллектор. Платная программа, установленная на вашем компьютере. Цена зависит от количества необходимых вам лицензий. На компьютере программа стоит от 2200 рублей (если вы устанавливаете программу впервые).
Click.ru. Инструмент платный, но есть пробный период. Вы можете загрузить собственную семантическую информацию для сбора подсказок либо в виде файла Excel, либо просто вставить ее в поле. Подсказки могут быть получены от Yandex, Google и YouTube.
Шаг 7. Составляем фразы с помощью пересечения слов
Теперь вернемся к нашей таблице или карте. Для каждого из его разделов необходимо составить перекрестные ссылки, на основе которых мы в дальнейшем будем анализировать семантическое ядро. Анализ — это автоматический сбор информации с помощью специального программного обеспечения.
Чтобы создать перекрестные таблицы, мы берем наш первый столбец и начинаем умножать его с помощью макросов.
Существуют специальные комбинации ключевых слов для более быстрого размножения ключей. Такие услуги доступны, например, на:
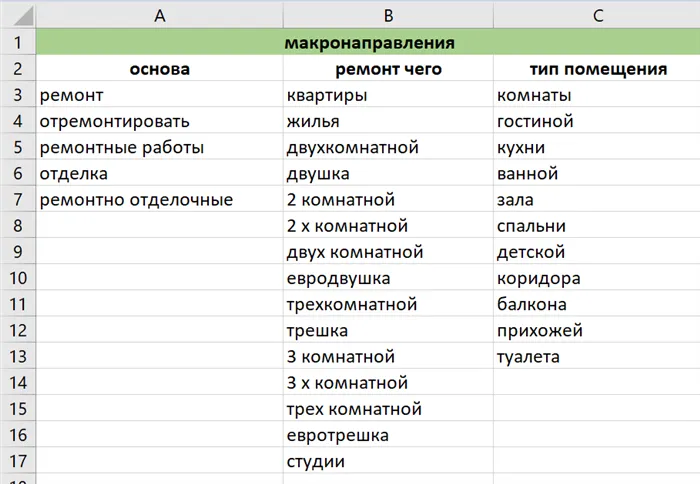
Наш стол для ясности:
В первую колонку программы мы вводим список слов из колонки «База», а во вторую — слова из колонки «Тип помещения». Почему мы сначала использовали слова из рубрики «Тип помещения», а не «Реновация чего»? Чтобы группы не путали друг с другом. Например, у нас есть две группы: Ремонт квартир и ремонт спален. Если мы сначала проанализируем фразы с «ремонт квартиры», то получим следующие вопросы: ремонт квартиры, ремонт спальни, ремонт квартиры в новостройке. Система собирает все фразы, содержащие слова «ремонт» и «квартира», среди этих собранных фраз есть и слово «спальня». Для того чтобы «спальни» были в своей группе, а остальные «квартиры» — в своей, нам нужна последовательность разбора. Лучше действовать в таком порядке. Тогда все «спальни» окажутся в одной группе, и нам не придется искать их потом в потоке фраз из других групп.
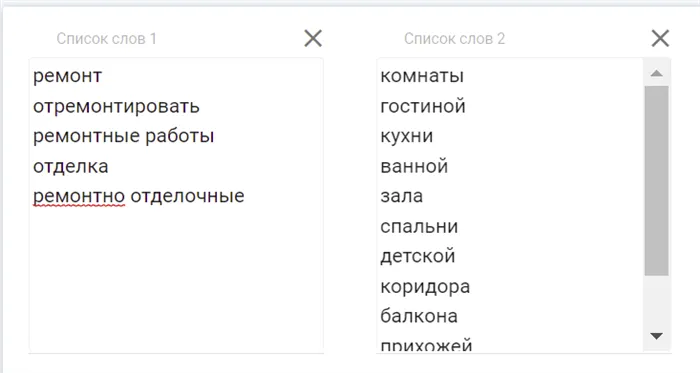
Это будет выглядеть следующим образом:
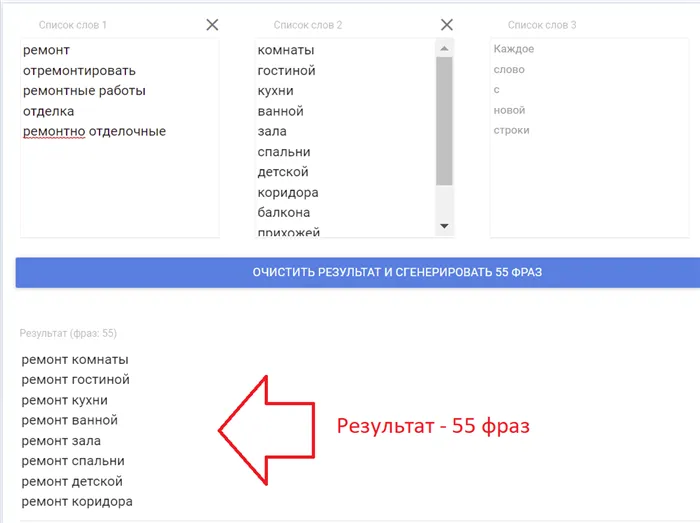
Нажмите на «Retrieve combinations» или «Generate phrases» (в зависимости от выбранной программы), и вы получите список из 55 фраз:
В нашем списке все выражения используются довольно часто. Однако бывает и так, что люди просто не используют многие из этих выражений для поиска. Так зачем их собирать? Ответ прост: чтобы ничего не пропустить. На следующих этапах, когда мы будем рассматривать частоту, мы просто удалим те, у которых нулевая или очень низкая частота.
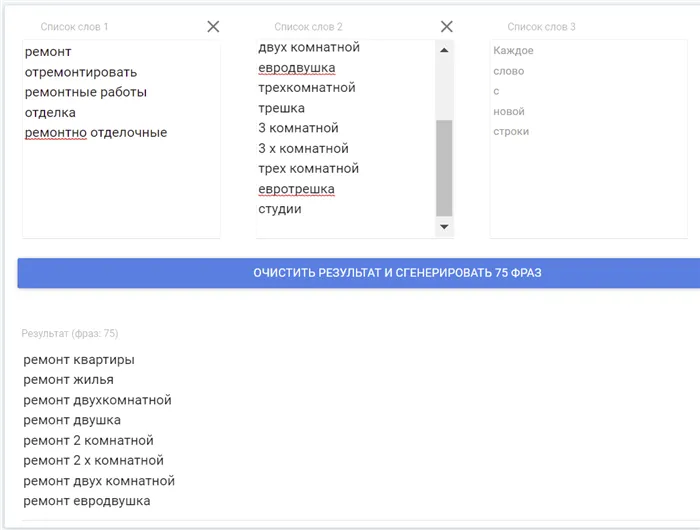
Аналогично поступаем с оставшимися колонками. Мы умножаем все фразы, которые сочетаются подобным образом.
Все полученные фразы мы копируем в Excel.
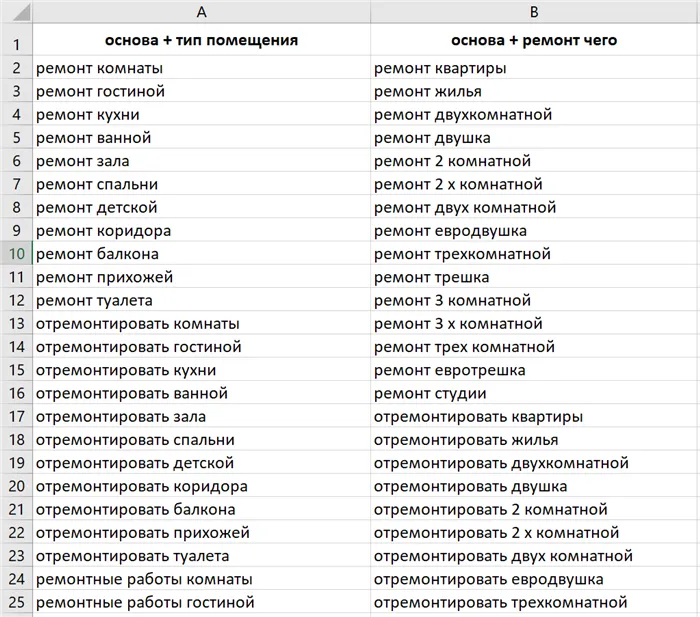
В примере мы обращаемся только к макронаправлениям. Таким же образом мы делаем кресты в микронаправлениях.
Вот и все — входные фразы, необходимые для анализа семантического ядра, готовы.
Шаг 8. Парсим фразы из Wordstat
Последним и самым мощным инструментом для создания семантического ядра является анализ фраз от Yandex.Wordstat.
Одним из самых популярных программ для анализа является Key Collector, о котором мы упоминали выше. При его настройке обязательно определите область применения, как и при анализе поисковых запросов. Важно выбрать не только город, но и местность вокруг него. Это, например, Москва и Московская область, Санкт-Петербург и Ленинградская область и т.д.
Также очень важно отправлять слова на анализ группами в соответствии с составленной нами таблицей. Например, лучше искать сначала запросы с названиями комнат, а затем более общие термины (квартира, дом и т.д.).
Если входящих ключевых слов слишком много, анализ займет слишком много времени. Для ускорения процесса Key Collector часто использует прокси-серверы. Они позволяют выполнять анализ на многих потоках одновременно, сокращая общее время сбора семантики. Прокси-серверы необходимо приобретать отдельно.
Вам также может понадобиться программа для автоматической вставки капчи. Вам нужно будет загрузить и установить его в дополнение к Key Collector.
Одним из самых больших недостатков Key Collector является отсутствие версии для macOS, но вы можете запустить его на виртуальной машине.
Однако не обязательно использовать только Key Collector. Существуют и другие программы для выбора семантических ядер:
Wordob (бесплатный аналог Key Collector, но с гораздо более ограниченными функциями),