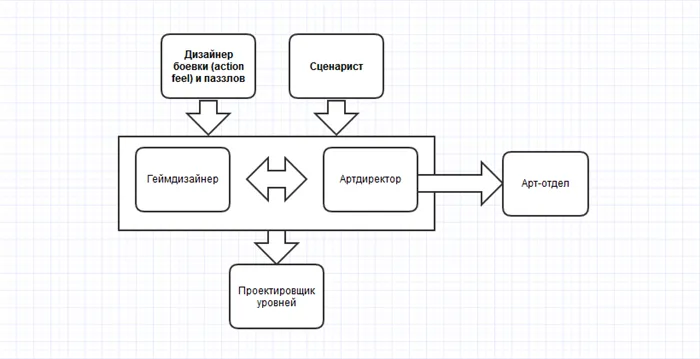
Другим интересным проектом представляется OpenCog, который объединяет большое количество различных компонентов для разных задач (отдельные эмоции, NLP, база знаний, принятие решений).
Как сделать искусственный интеллект на компьютер. Как создать искусственный интеллект
Мы достигли того момента, когда ИИ создает собственную нейронную сеть. Хотя многие считают, что это одно и то же. Но на самом деле все не так просто, и сейчас мы попытаемся разобраться, что это такое и кто что может создать.
Инженеры Google Brain запустили AutoML этой весной. Этот ИИ способен создавать свой собственный уникальный ИИ без вмешательства человека. Как недавно было продемонстрировано, AutoML впервые смог создать NASNet, систему компьютерного зрения. Эта технология намного превосходит все предыдущие аналоги человеческой. Он основан на искусственном интеллекте и может стать идеальным инструментом, например, для разработки автономных автомобилей. Есть также применение в робототехнике — роботы могут выйти на совершенно новый уровень.
При разработке AutoML используется уникальная система усиленного обучения. Это менеджер нейронных сетей, который автономно разрабатывает совершенно новые нейронные сети для конкретных задач. В упомянутом случае AutoML ставит своей целью разработку системы, распознающей объекты на видео с максимально возможной точностью в режиме реального времени.
ИИ сам смог обучить новую нейронную сеть, отслеживать ошибки и корректировать работу. Процесс обучения повторялся многократно (тысячи раз), пока система не была готова к использованию. Удивительно, но ей удалось превзойти все имеющиеся на сегодняшний день сопоставимые нейронные сети, но разработанные и обученные людьми.
Тем временем AutoML оценивает производительность NASNet и использует эту информацию для улучшения сети нижнего уровня, и этот процесс повторяется тысячи раз. Когда инженеры протестировали NASNet с наборами изображений ImageNet и COCO, он превзошел все существующие системы компьютерного зрения.
Google официально заявила, что NASNet обнаруживает с точностью 82,7 %. Это на 1,2% лучше, чем предыдущий рекорд, установленный исследователями из Momenta и Оксфордского университета ранее этой осенью. NASNet на 4% эффективнее своих конкурентов, со средней точностью 43,1%.
Существует также упрощенная версия NASNet, предназначенная для мобильных платформ. Он опережает своих конкурентов чуть более чем на три процента. В ближайшем будущем его можно будет использовать для производства автономных автомобилей, для которых компьютерное зрение играет важную роль. С другой стороны, AutoML продолжает создавать новые нейронные сети, чтобы достичь еще больших высот.
Это, конечно, вызывает этические проблемы, связанные с ИИ: Что если AutoML будет разрабатывать системы с такой скоростью, что общество просто не сможет за ними угнаться? Однако многие крупные компании прилагают усилия для решения проблем безопасности ИИ. Например, Amazon, Facebook, Apple и ряд других компаний являются членами Партнерства за ИИ на благо людей и общества. Институт инженеров по электротехнике и электронике (IEE) предложил этические стандарты для ИИ, а компания DeepMind, например, объявила о создании группы для решения этических и моральных вопросов, связанных с применением ИИ.
Однако многие крупные компании пытаются решить вопросы безопасности ИИ, что, конечно же, вызывает этические проблемы, связанные с ИИ: Что если AutoML будет развивать системы такими темпами, что общество просто не сможет за ним угнаться? Институт инженеров электротехники и электроники (IEE), с другой стороны, предложил этические стандарты для ИИ, а компания DeepMind, например, объявила о создании группы для решения этических и моральных вопросов, связанных с применением ИИ. Например, Amazon, Facebook, Apple и многие другие компании являются членами Партнерства за ИИ на благо людей и общества.
Цифровая телепатия: как искусственный интеллект учится читать мысли человека
Чтобы произвести впечатление на весь мир, вам не нужно строить огромную лабораторию с тоннами жужжащих приборов. ИИ живет, растет и развивается в системном блоке компьютера, нейронной сети, у которой есть только одна цель — научиться копировать каждый голос. Для этого не нужно ничего.
Владимир Свешников, генеральный директор компании: «Несколько часов голосовых проб, то есть аудио, и к аудио подключается текст. Текст фиксирован, задача состоит в том, чтобы сочинить голос. Нейронная сеть запоминает его, как ребенок».
Программное обеспечение собирает характерные особенности речи таким образом, что невооруженным ухом невозможно отличить ее от оригинала. Как мы можем доверять телефонам, когда эта машина учится говорить не по заранее написанным инструкциям, как сейчас, а читая наши мысли в реальном времени и заменяя наш голос?
Существуют риски для экономики, поскольку выпуск фальшивой записи может привести к обвалу акций компании. Ученые в области ИИ должны взять на себя ответственность за свои разработки, а общество должно подумать о контроле над ними. Это может показаться фантастическим бредом, но вскоре «умные» программы действительно будут управляться одной лишь силой мысли. Великий мечтатель и любитель самых смелых разработок Элон Маск представил крошечный имплантат мозга.
Элон Маск, изобретатель и основатель компании SpaceX: «Это может показаться странным, но мы пытаемся достичь некоего симбиоза между человеческим и искусственным интеллектом. Мы планируем внедрить первый чип для людей уже в следующем году, так что нам предстоит еще долгий путь.
Число сторонников идеи чипа растет в геометрической прогрессии, чип на голове может стать таким же привычным аксессуаром, как смартфон. И тогда технология действительно объединит искусственный интеллект с человеческим разумом. Именно об этом мечтает Маск, чтобы в будущем любую информацию можно было загружать прямо в мозг, как в компьютер, языки можно было бы изучать за часы или даже минуты, и даже мысли можно было бы передавать друг другу.
Известный телепат Лиор Сушар развлекает публику во время вечернего шоу. Многие, наверное, скажут: шарлатан. Но прежде чем говорить о том, могут ли машины читать мысли, нужно понять, что такое телепатия. Был проведен эксперимент НТВ в прямом эфире с участием зрителей. Их просили отвечать на вопросы как можно быстрее. Сначала они должны были решить примеры в уме, а затем быстро придумать орган и цвет. Большинство гостей в студии думали, что «красный молоток». Никто не приходил им на ум. Это не телепатия, а психология: люди отвлекались на расчеты, рассеивали свое внимание и выбирали первое, что приходило в голову. По статистике, самый распространенный цвет — красный, и именно его все помнят с детства. Фокусник Лиор Сушар, чьи трюки гораздо сложнее, признается, что его «магия» также основана на чистой науке.
Читайте также: Как сделать светофор в детском саду. Видео: «Дорога в детский сад», групповой видеоролик о правилах дорожного движения. Видео: Пчела, сделанная из пластиковой бутылки
Лиор Сушар, иллюзионист: «Я использую свои пять чувств, чтобы создать шестое чувство. Существует так много техник, от психологии до языка тела.
Искусственный интеллект считывает мысли людей аналогичным образом. Доказательством тому служит технология, используемая в реабилитационном центре, которая помогает людям писать силой мысли без использования рук. Нужно расслабиться и сосредоточиться на определенной букве, цифре или символе. Компьютер понимает, что пользователь хочет набрать. Сегодня это окно в мир для тех, кто потерял способность двигаться. Если технология может быть усовершенствована, это может принести пользу всем.
Создать искусственный интеллект
Искусственный интеллект (ИИ) — это наука и технология создания интеллектуальных машин, особенно интеллектуальных компьютерных программ; способность интеллекта выполнять творческие функции, традиционно считавшиеся прерогативой человека. Сейчас известно, что цифровые схемы в миллионы раз быстрее биохимических, и идет непрерывная разработка/проектирование/усовершенствование существующих искусственных форм интеллекта, но их применимость очень ограничена. Нет интегрированного мозгового центра, способного к автономному обучению и принятию решений в широком спектре деятельности, от простого «фетч, фетч, фетч» до разработки сложнейших квантовых механизмов. Со временем темпы развития будут увеличиваться.
Живя в 21 веке, мы являемся свидетелями стремительного прогресса не только в развитии информационных технологий, но и в разработке систем, включая искусственный интеллект, которые в будущем будут контролировать большую часть человеческой деятельности и участия:
1. финансовый сектор:
1.1 Алгоритмическая торговля — предполагает использование сложных систем искусственного интеллекта для принятия торговых решений со скоростью, с которой не может сравниться человеческий организм. Это позволяет выполнять миллионы транзакций в день без вмешательства человека. Автоматизированные торговые системы обычно используются крупными институциональными инвесторами.
1.2 Исследование рынка и поиск данных — несколько крупных финансовых учреждений инвестировали в разработку искусственного интеллекта для использования в своих инвестиционных процессах. Aladdin, разработка BlackRock в области искусственного интеллекта, используется как внутри компании, так и для клиентов компании, помогая принимать инвестиционные решения. Среди многочисленных функций этой системы — обработка естественного языка для чтения текстов, таких как новости, отчеты брокеров и ленты социальных сетей. Затем система оценивает настроения в отношении этих компаний и присваивает им балл. Такие банки, как UBS и Deutsche Bank, используют систему искусственного интеллекта под названием Sqreem (Sequential Quantum Reduction and Extraction Model), которая может обрабатывать данные для построения профилей потребителей и сопоставления их с продуктами, которые они, скорее всего, захотят приобрести. Goldman Sachs использует Kensho, платформу рыночной аналитики, которая сочетает статистические вычисления с Большими Данными и обработкой естественного языка. Системы машинного обучения используют веб-данные и оценивают корреляции между глобальными событиями и их влиянием на цены финансовых активов. Информация, которую система искусственного интеллекта извлекает из прямых трансляций новостей, используется для принятия инвестиционных решений.
1.3 Андеррайтинг — Upstart анализирует огромные объемы данных о потребителях и использует алгоритмы машинного обучения для построения моделей кредитного риска, которые предсказывают вероятность дефолта. Их технология лицензирована для банков, чтобы они могли использовать ее для оценки своих процессов.
Компания ZestFinance разработала платформу Zest Automated Machine Learning (ZAML) специально для андеррайтинга кредитов. Платформа использует машинное обучение для анализа десятков тысяч традиционных и нетрадиционных переменных (от операций покупки до того, как клиент заполняет форму), используемых в кредитной индустрии для оценки заемщиков. Эта платформа особенно полезна для присвоения кредитных баллов клиентам с короткой кредитной историей, например, представителям миллениалов.
Программное обеспечение собирает характерные особенности речи таким образом, что невооруженным ухом невозможно отличить ее от оригинала. Как мы можем доверять телефонам, когда эта машина учится говорить не по заранее написанным инструкциям, как сейчас, а читая наши мысли в реальном времени и заменяя наш голос?
Как запустить свой эффективный ИИ-стартап?

Вы хотите создать свой собственный стартап с использованием технологии искусственного интеллекта (ИИ). Какие процессы следует рассмотреть, как подготовить и обработать данные для обучения нейронной сети и на что обратить внимание при наборе и управлении командой? В этой статье мы постараемся ответить на все эти вопросы в доступной форме, основываясь на отрывке из книги «Embracing the Power of AI — https://www.globant.com/our-books» (далее книга). Авторы: Хавьер Минхондо, Хуан Хосе Лопес Мерфи, Хальдо Спонтон, Мартин Мигойя и Гиберт Энглебиенн.
Важно понимать как потребности бизнеса, так и источники входных данных. Есть случаи, когда хорошее решение появляется без использования искусственного интеллекта, например, hubex.ru, приложение для управления заявками на обслуживание.
На чем следует сосредоточиться, чтобы принять правильное решение: на потребностях пользователей или на используемой технологии? В книге описывается, что успешный продукт ИИ призван помочь людям непосредственно получать или обрабатывать информацию для принятия правильных решений.
Определение цели и постановка задачи
Первый и самый важный вопрос для команды разработчиков — какую проблему должен решить ИИ, и по сути это будет бизнес-потребность. Итогом выполнения этого задания является ожидаемый конечный результат, который необходимо проверить для обеспечения максимальной точности.
Следующим шагом является определение источников данных — насколько они надежны, как они могут быть интегрированы в разрабатываемую систему, и как команда разработчиков может использовать их для достижения бизнес-целей. Проще говоря, при работе с данными их необходимо обрабатывать максимально эффективно, независимо от сложных преобразований и низкой скорости обработки, чтобы получить нужный результат. Важно не качество первичных данных, а правильная подготовка обучающей выборки. Если принцип выборки обучающих данных выбран правильно, задача может быть расширена за счет более обширного набора данных. Подводя итог, можно сказать, что существует список вопросов: — Какие источники данных доступны; — Как выглядят данные; — Достаточно ли у нас данных; — Откуда берутся данные и как они собираются и обрабатываются? Кроме того, есть ряд других вопросов, которые также следует задавать в будущем, потому что если их не задавать, это может значительно усложнить разработку проекта. Дополнительные вопросы: — Репрезентативна ли выборка данных, которую мы используем для обучения модели; — Есть ли подводные камни, которые мы не учли? — Содержит ли образец персональные данные и допустимо ли их использование? Следующим шагом перед созданием реального алгоритма является обработка данных (подготовка, кластеризация) и нормализация. Этот шаг необходим для подготовки образца к правильной интерпретации математической моделью искусственного интеллекта. Например, числовой выборкой можно манипулировать путем экспоненциализации или умножения переменных на константу, так что линейные модели моделируют нелинейные отношения для выявления общих закономерностей. Иногда преобразование Фурье требуется для правильной интерпретации частотной характеристики при обработке звука или для использования алгоритма SIFT для сопоставления изображений. Должно быть ясно, что нормализация и кондиционирование данных имеют решающее значение для традиционного машинного обучения. Этот процесс оказывает большое влияние на выбор архитектуры используемой нейронной сети, особенно в так называемом глубоком обучении, где необходимо правильно определить количество скрытых слоев в нейронной сети и количество искусственных нейронов в ней. Одним из главных преимуществ многослойных нейронных сетей является то, что они имитируют работу сложных математических отношений.
Разработка модели ИИ, программирование и обучение нейронной сети
Теперь, когда у нас есть четкая бизнес-цель, правильный исходный набор данных для выборки и сама выборка, мы можем приступить к разработке моделей нейронных сетей и планированию дальнейшего обучения нейронных сетей. Новый этап включает в себя выбор алгоритма обучения, реализацию алгоритма обучения, визуализацию и оценку качества обучения. Обучение нейронной сети можно сравнить с тем, как если бы собаке миллион раз дали команду. Как бы банально это ни звучало, процесс обучения довольно прост. У вас есть обучающая выборка с выходными данными и конечными результатами. Вы подаете входные данные в нейронную сеть, а выходной сигнал является результатом обработки нейронной сетью. Затем вы сравниваете полученный результат с результатом вашего образца и указываете степень сходства. Процесс может показаться простым, но его эффективное и корректное выполнение на больших выборках данных — это еще не все. Необходимо выбрать правильный алгоритм обучения нейронной сети, иначе искусственный интеллект может научиться неправильно интерпретировать входящий поток данных, что приведет к нежелательным ошибкам. Один из таких случаев произошел в Google, когда фотография афроамериканской семьи была загружена в программу распознавания лиц, и программа идентифицировала изображение как семью обезьян. Связано ли действие искусственного интеллекта в данном случае с расизмом? В целом, показано, что конечное поведение сгенерированного ИИ зависит от исходного набора данных, процедур обработки и нормализации, используемого алгоритма обучения и критерия валидации результатов обучения. На этом этапе сочетание различных подходов позволяет обучить нейронную сеть соответствующим образом, чтобы взаимодействие с разработанной математической моделью было максимально эффективным. Одно из самых важных решений на этом этапе — какой процент обучающей выборки полностью используется для обучения нейронной сети, а какой процент впоследствии передается нейронной сети для дальнейшего тестирования.
Тестовая выборка также должна быть репрезентативной, как и набор обучающих данных. В прошлом было принято использовать исходную обучающую выборку в соотношении 80 к 20, из которой большая часть данных используется для обучения нейронной сети. Некоторые современные подходы к глубокому обучению предлагают использовать до 99% данных для обучения и 1% для тестирования. Теперь нам нужно определиться с составом команды и ролью каждого участника. Команда разработчиков должна взять на себя задачу обучения нейронной сети, в частности, разработку и тестирование алгоритмов машинного обучения. Одна часть команды будет обучать алгоритм, а другая часть команды будет тестировать алгоритм и проверять, насколько хорошо ИИ решает поставленную задачу. Распространенной ошибкой, с которой сталкиваются многие команды разработчиков, является использование одного и того же набора данных для обучения и тестирования нейронной сети. Обычно это приводит к тому, что ИИ показывает очень хорошие результаты в тестах, поскольку тестовые данные уже были представлены на этапе обучения. Команда разработчиков, попавшая в эту ловушку, будет склонна утверждать, что нейронная сеть выдает правильный результат в результате машинного обучения. Наконец, команда разработчиков должна оценить эффективность нейросетевой модели с точки зрения чувствительности и стоимости. Ни одна модель не является совершенной, но не все ошибки по своей сути одинаковы. Модель может давать так называемые ложноположительные или ложноотрицательные результаты. Как и в медицине, важно взвесить, какой диагноз наиболее безопасен для пациента. Конечно, ложноположительный результат лучше, потому что он дает пациенту некоторую уверенность в принятии решения. Например, в задаче выявления террористов в аэропорту. Бдительность не повредит, но не стоит заходить так далеко, чтобы обучить ИИ определять всех без исключения в аэропорту как потенциальных террористов. В случае с розничными магазинами чрезмерное прогнозирование может увеличить стоимость оборотного капитала, а недостаточное прогнозирование может увеличить затраты и резко снизить продажи покупателям. Решение о том, как правильно обучить нейронную сеть для конкретной задачи, всегда является компромиссом. Как ответить на вопрос, сколько тренировочных циклов необходимо? Является ли задачей ИИ просто запомнить таблицу данных и извлечь ее, или приоритетной задачей будет распознавание некой закономерности для данных в этой таблице? Баланс между чрезмерным обучением (запоминанием) и обобщением нейронных сетей — еще одна сложная наука. Базовая схема такого подхода к решению проблем классификации показана на рисунке ниже. На протяжении всего процесса обучения основная проблема часто остается каким-то образом скрытой, вне поля зрения. Например, как можно измерить успех, затраты или предпочтения? Соответствует ли мера потребностям бизнеса? Полезен ли он с технической точки зрения? Часто на эти вопросы нужно отвечать напрямую. Все наборы исходных данных имеют свои недостатки и подводные камни, и не все они математически полезны для обучения! Когда команда разработчиков уверена, что у них есть правильное решение проблемы, они могут работать над превращением результатов нейронной сети в идеи и меры,
делать прогнозы или просто использовать их в результате обработки данных. Схематичное представление обобщенной концепции показано ниже.
ИИ должен уметь работать в многозадачном режиме
Именно такого подхода в настоящее время придерживается OpenAI, и модель GPT-3, возможно, является одной из самых впечатляющих разработок в этой области.
Другой ключевой проблемой, стоящей на пути разработки действительно глубоких моделей машинного обучения, является тот факт, что все существующие системы ИИ очень тупые. По словам Райи Хадселл, исследователя DeepMind в Google, эти системы уже можно научить распознавать и воспроизводить кошек, и они могут выполнять эти задачи очень хорошо. Но «в настоящее время в мире не существует полноценных нейронных сетей и методов, позволяющих обучить их распознавать картинки, играть в Space Invaders и думать о музыке». Нейронные сети, в свою очередь, являются важнейшей основой для построения систем глубокого машинного обучения.
И проблема гораздо серьезнее, чем кажется на первый взгляд. Когда в феврале прошлого года компания DeepMind объявила о разработке системы, способной играть в 49 игр Atari, это действительно можно было считать большим успехом. Однако оказалось, что как только система закончила играть в одну игру, ее пришлось переучивать на другую. Хэдселл отмечает, что мы не можем научить систему играть во все игры одновременно, так как правила каждой игры будут смешиваться и в конечном итоге помешают выполнению текущей задачи. Нам приходится каждый раз обучать машину с самого начала, при этом система каждый раз «забывает», как играть в предыдущую игру.
«Чтобы создать общий ИИ, нам нужно что-то, что научит машину выполнять несколько задач одновременно. Сейчас мы даже не можем научить их играть», — говорит Хадселл.
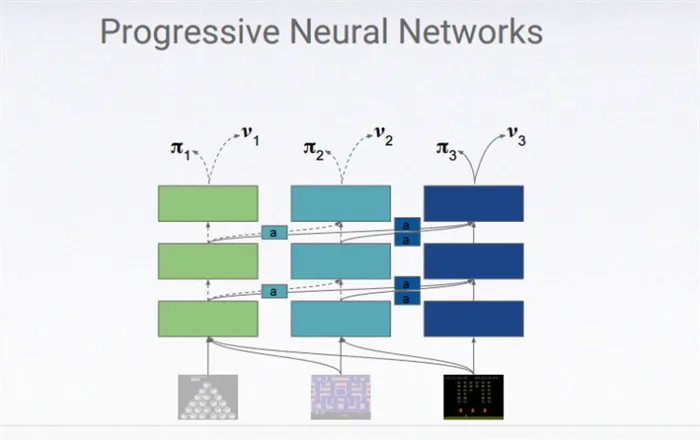
Решение может заключаться в так называемых прогрессивных нейронных сетях, которые объединяют независимые системы глубокого обучения в единое целое для более эффективной обработки информации. В опубликованной научной работе, посвященной этому вопросу, Хадселл и ее исследовательская группа описали, как их прогрессивная нейронная сеть смогла адаптироваться к игре в понг, где условия каждый раз немного отличались (в одном случае менялись цвета, в другом — элементы управления), намного быстрее, чем «обычная» нейронная сеть, которой приходилось каждый раз переучиваться заново.
Основной принцип работы прогрессивной нейронной сети
Когда мы получим настоящий искусственный интеллект
Метод оказался перспективным и недавно был использован для настройки роботизированных манипуляторов, что позволило сократить время обучения с недели до одного дня. К сожалению, даже этот метод имеет свои ограничения. Хэдселл отмечает, что процесс обучения в прогрессивных нейронных сетях не может ограничиваться простым добавлением новых задач в память. Если вы будете продолжать компилировать такие системы, рано или поздно у вас получится «модель, которая слишком сложна, чтобы за ней следить». В данном случае речь идет о другом уровне. Уровень, на котором различные задачи в основном выполняются одинаково. Разработка ИИ, который может проектировать стулья, и разработка ИИ с человеческим интеллектом, который может писать стихи и решать дифференциальные уравнения, — это не одно и то же.
Еще одним серьезным препятствием является понимание того, как ИИ приходит к своим выводам при решении проблем. Нейронные сети, как правило, невосприимчивы к наблюдателю. Мы знаем, как они устроены и как через них проходит информация, но решения, которые они принимают, как правило, не объясняются.
Отличным примером этой проблемы является эксперимент, проведенный в Вирджинском технологическом институте. Исследователи разработали систему мониторинга нейронной сети, которая записывает, с каких пикселей цифрового изображения компьютер начинает свой анализ. Исследователи показали нейронной сети изображения спальни и задали ей вопрос: «Что висит в окнах?». Вместо того чтобы смотреть непосредственно на окна, машина начала анализировать изображения, начиная с пола. Он наткнулся на кровать, и машина ответила: «На окнах есть занавески». Ответ был правильным, но только потому, что система была «обучена» работать с ограниченным объемом данных. Нейронная сеть пришла к выводу, что если на картинке изображена спальня, то на окнах должны быть занавески. Поэтому, когда он наткнулся на деталь, которая обычно присутствует в каждой спальне (в данном случае кровать), он не стал анализировать изображение дальше. Может быть, он даже не видел кровати, а только занавески. Логично, но очень поверхностно и надуманно. В конце концов, во многих спальнях нет штор!
Технология наблюдения — это лишь один из инструментов, который может помочь нам понять, что заставляет машину принимать то или иное решение, но есть и более подходящие способы добавить больше логики и глубокого анализа в системы машинного обучения. Мюррей Шанахан, профессор когнитивной робототехники в Имперском колледже Лондона, считает, что лучшим решением является возвращение к старой доброй парадигме искусственного интеллекта — символическому искусственному интеллекту или GOFAI (Good Old-Fashioned Artificial Intelligence). Эта парадигма основана на том, что любая задача может быть разбита на основные логические элементы, где каждое слово — это просто сложная серия простых символов. Объединяя эти символы — в действия, события, объекты и т.д. — мышление может быть синтезировано. Не забывайте, что такие разработки велись в то время, когда компьютеры все еще были огромными, размером с комнату, коробками, работающими на магнитных лентах (работа началась в середине 1950-х годов и продолжалась до конца 1980-х годов).
Если вас интересуют новости науки и техники, подписывайтесь на нас в Google News и Яндекс.Дзен, чтобы не пропустить ни одной новости!
Предложение Шанахана представляет собой сочетание символических описаний GOFAI и технологий глубокого обучения. Подход Шанахана заключается не в том, чтобы скармливать этим системам новую информацию и ожидать, что они выведут из этой информации определенные модели поведения и решения проблем, а в том, чтобы дать этим системам отправные точки для понимания мира. Это решило бы не только проблему прозрачности ИИ, но и проблему переносимого обучения, описанную Хэдселлом.
«Можно определенно сказать, что Breakout и Pong очень похожи, потому что в них используются «платформы» и «шарики», но с точки зрения человеческого восприятия и логики это две совершенно разные игры. И провести параллели между ними практически невозможно. Это все равно, что пытаться соотнести структуру отдельного человека со структурой всей Солнечной системы.
Как создать искусственный интеллект? История первая. Что такое интеллект?
Этот подход фокусируется на тех методах и алгоритмах, которые помогают ему выполнять свою работу. Поэтому алгоритмы поиска пути и принятия решений рассматриваются здесь гораздо более подробно.
В этой серии статей мы познакомим вас с новыми подходами в области ИИ, моделирования личности и обработки Больших Данных, которые недоступны большинству экспертов в области ИИ и широкой публике. Ценность этой информации заключается в том, что все они были проверены на практике, а большинство теоретических разработок были применены в прикладных проектах.
Многие из вас слышали о современных технологиях, которые сейчас ассоциируются с термином ИИ: Экспертные системы, нейронные сети, языковые алгоритмы, гибридные системы, когнитивные технологии, симуляции (чат-боты) и т.д.
Первое, что мы с вами сделаем это определим, что такое интеллект.
- Да, многие компании используют перечисленные технологии для решения задач по обработке информации своих клиентов. Некоторые из этих компаний пишут, что они разрабатывают или уже разработали решения в области ИИ. Но разве это интеллект?
- Необходимо ли закладывать языковые особенности (описывать семантику, грамматику и морфологию) в программу компьютерного интеллекта, или она может изучать языки самостоятельно, взаимодействуя с людьми?
- Если бы перед вами стояла задача научить компьютер языку, что бы вы сделали?
- Если бы вы были единственным учителем, как бы это выглядело?
- Породистый попугай, который теоретически может общаться.
- Новорожденный ребенок.
- Сначала я попросил вас представить (создать картинку) «что было бы, если бы…». Вы работали в изменившихся условиях. Возможно, вам не хватало информации и знаний, вы испытывали трудности.
Во-вторых, вы были в состоянии знать, возможно, вы нашли известную аналогию, возможно, вы нашли ее в тексте, возможно, вы просмотрели интернет или спросили совета у друга.
- Чтобы разработать алгоритм, моделирующий интеллект, сначала нужно дать ему возможность обучаться без необходимости вкладывать в него деньги.
- Чем чаще он слышит слово в разных контекстах, тем быстрее он его запомнит. Первое слово, которое он произнесет, скорее всего, будет «мама». «Мама любит тебя» «Мама моет твои руки» «Мама целует тебя» «Где мама?» Обучение происходит за счет избыточности.
- Чем больше информационных каналов задействовано, тем эффективнее обучение: ребенок слышит «мама тебя любит». Ребенок видит, как мама улыбается. Ребенок чувствует тепло, исходящее от мамы. Ребенок чувствует вкус и запах молока матери. Ребенок говорит «мама».
- Ребенок не сможет сразу произнести слово. Он будет пытаться, пытаться и пытаться. «М», «Ма», «Мама», «М» … «Мать». Обучение — это процесс исправления каждой попытки до тех пор, пока не будет достигнут результат. Метод проб и ошибок. Обратная связь с реальностью очень важна.
Какова же роль воображения?
Не учите своих детей, они все равно будут похожи на вас. Ребенок старается быть похожим на окружающих его людей. Он подражает им и учится у них. Это один из механизмов моделирования личности, который мы более подробно обсудим в следующих статьях.
Представьте, что вы едете на своем автомобиле по незнакомой дороге. Вы проезжаете знак с ограничением скорости 80 км/ч. Вы видите другой знак с ограничением скорости, но он покрыт грязью, и вы едва можете его разглядеть. Продолжая движение, вы видите еще один знак с ограничением скорости, но он покрыт грязью, и вы едва можете его разглядеть. Вы едете со скоростью 95 км/ч. Что ты делаешь? Пока вы принимаете решение, полицейский выглядывает из-за кустов, и вы видите улыбку на его лице. У вас в голове сразу возник образ номерного знака, вы поняли, почему там стоит полицейский и что вам нужно срочно тормозить. Вы снижаете скорость до 55 км/ч, улыбка на лице полицейского тут же исчезает, и вы едете дальше.
Еще один интересный пример того, как работает воображение в животном мире, — наблюдение за сороками. Сорока закапывала еду на виду у других сорокопутов. Все сороки улетели, а наша сорока вернулась в пустыню и снова спрятала еду. Что случилось? Он представил, «что будет, если другой сорокопут прилетит и увидит, где он спрятал еду». Он смоделировал ситуацию и нашел решение, как ее избежать.
Воображение — это моделирование ситуации в произвольных обстоятельствах.
Как вы убедились, интеллект — это не набор знаний, не набор заранее запрограммированных ответов или следование заранее установленным правилам.
Интеллект — это способность учиться, распознавать и адаптироваться к изменяющимся обстоятельствам и справляться с трудностями.
Не кажется ли вам, что мы упустили или забыли упомянуть некоторые важные элементы в определении интеллекта?
Да, мы упустили из виду восприятие и забыли поговорить о памяти.
Представьте, что вы смотрите в глазок и видите часть письма:
Какая это буква?
Конечно, нет, это японский иероглиф, означающий «вечность».
Вы только что столкнулись с проблемой. Скорее всего, вы нашли в своем сознании похожий образ буквы «К» и успокоились.
Ваш разум воспринимает все образами и ищет похожий образ в памяти; если его там нет, формируется якорь в уже существующих образах, и благодаря ему вы запоминаете новую информацию, приобретаете навыки или опыт.
Изображение — это субъективное видение реального мира, воспринимаемое через органы чувств (информационные каналы).
Восприятие субъективно, поскольку зависит от последовательности обучения, порядка появления образов в жизни и их влияния.
Восприятие начинается с распознавания светло-темных изображений. Когда мы открываем глаза — светло, когда закрываем — темно. Затем мы учимся распознавать все более сложные образы — «мама», «папа», мяч, стол, собака. Мы получаем эталонные данные, и все последующие изображения являются надстройкой над предыдущим.
В этом отношении обучение — это процесс установления новых отношений между воспринимаемыми образами и образами, уже имеющимися в памяти.
Память служит для хранения образов и их ассоциаций.
А воображение — это способность завершить неполную картину.
Подводя итог, можно сказать, что это еще один эксперимент из мира животных: