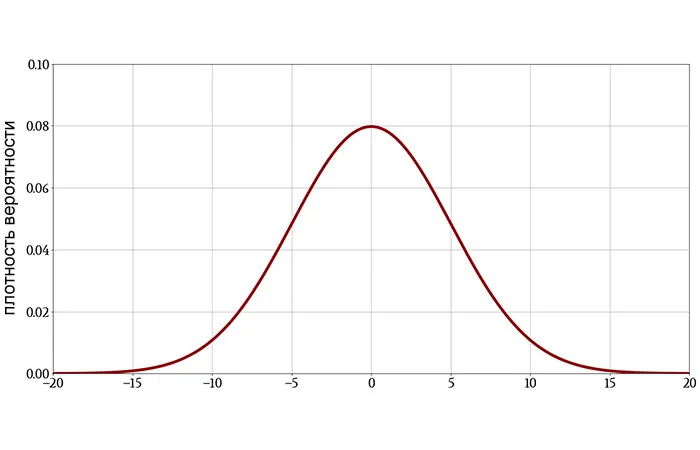
Связь между отдельными атрибутами xdв свою собственную нейронную сеть fd(xd), мы можем найти все конечные узлы исчерпывающим образом,
Нейросети: какие бывают, как их обучают и 10 онлайн нейросетей
Нейронная сеть — это компьютерный алгоритм, который имитирует поведение человеческого мозга при обработке данных. Когда нейронная сеть сталкивается с неизвестным объектом, она обучается подобно человеку, делает выводы и использует полученную информацию в дальнейшем.
Мы объясним на примерах, как работают нейронные сети, узнаем, почему они полезны и как они связаны с Deep Learning. В конце вы найдете подборку сервисов, которые вы можете использовать, чтобы самостоятельно опробовать нейронные сети. Вы увидите, как искусственный интеллект создает текст, рисует картинки и даже сочиняет музыку.
У вас нет времени прочитать статью? Найдите его на своем канале Telegram и сохраните в избранном на будущее.
Содержание статьи
Обычный подход к программированию заключается в том, что люди пишут алгоритмы для компьютеров, т.е. говорят им, что именно нужно делать. В случае с нейронными сетями мы не говорим им, как решить проблему — они учатся делать это сами на основе различных данных.
Со временем нейронная сеть распознает закономерности и генерирует на их основе новые решения. В то же время ИИ не может изобрести ничего уникального — он действует только в контексте усвоенной им информации.
Примером нейронной сети являются голосовые помощники Siri, Алиса, Маруся и другие. Со временем они начинают распознавать голос, понимать предпочтения и предлагать более подходящий контент.
Принцип нейронных сетей был изобретен в середине 20 века, но у человечества не было достаточно информации для обучения моделей. Нейронные сети стали активно использоваться только с 2010-х годов, когда стали доступны Большие Данные. С тех пор нейронные сети многому научились: они могут писать тексты, рисовать, читать вслух, создавать видео и даже музыку.
В сентябре 2022 года, например, появился журнал «РБК Стиль» с обложками, разработанными нейронной сетью. ИИ проанализировал работы с выставки современного искусства в Cosmoscow и создал изображение.

Обложка журнала «РБК Стиль» №5, 2022 год, автор — искусственный интеллект.
При обучении нейронная сеть может давать странные результаты. В 2019 году, например, робот-ассистент «Тинькофф Банка» грубо ответил пользователю. Девушка пожаловалась на проблемы со входом в приложение с помощью отпечатка пальца, поэтому ИИ посоветовал ей отрезать пальцы. Это произошло потому, что нейронная сеть обучалась на основе корпуса речи — большого количества данных из различных источников. Некоторые из текстов в корпусе были литературными, другие — нет. Чтобы избежать подобных ситуаций, тексты необходимо выбирать из большого количества текстов.
Как работает нейросеть?
Давайте рассмотрим пример работы нейронной сети. Предположим, нейронную сеть попросили отличить фотографию собаки от фотографии кошки, загрузив несколько фотографий этих животных. Нейронная сеть изучает каждое изображение и сообщает о своих результатах в виде двух чисел: одно показывает, насколько алгоритм уверен в том, что на изображении изображена собака, а другое — что это кошка. Если ответ неверный, следует отметить ошибку — алгоритм пересчитает и все запомнит.
- входной, куда приходят данные;
- один или несколько скрытых, где производятся вычисления;
- выходной, где данные выходят наружу.
Нейронная сеть не может давать уникальные результаты, потому что она действует только на основе предыдущего опыта. Например, если в нашу нейронную сеть загрузить фотографию попугая, она ничего не поймет и определит ее как кошку или собаку. Для того чтобы нейронная сеть могла распознавать попугаев, ее необходимо обучить по тому же алгоритму.
Модели дерева решений. Модели деревьев решений широко используются в контролируемом обучении, например, в задачах классификации. Они рекурсивно отображают входное пространство и присваивают метку/значение конечному узлу. Известными моделями деревьев являются C4. 5 (Quinlan, 1993 23) и CART (Breiman et al., 1984 5). Основным преимуществом древовидных моделей является то, что их легко интерпретировать, поскольку прогнозы даются на основе набора правил. Ряд различных деревьев, таких как Random Forest (Breiman, 2001 6) и XGBoost (Chen & Guestrin, 2016 8), также обычно используются для улучшения производительности за счет интерпретируемости. Такие древовидные модели часто конкурируют или даже превосходят нейронные сети в задачах прогнозирования с использованием табличных данных.
Интерпретируемые модели. Поскольку прогнозы на основе машинного обучения используются повсеместно и влияют на многие аспекты нашей повседневной жизни, фокус исследований смещается с производительности моделей (например, эффективности и точности) на другие факторы, такие как интерпретируемость (Weller, 2017 26; Doshi-Velez, 2017 11). Это особенно необходимо в приложениях, где существуют этические (Bostrom & Yudkowsky, 2014 4) или актуарные проблемы, и предсказания модели должны быть объяснимы, чтобы проверить достоверность или оправдать решения о процессе мышления. В настоящее время существует несколько попыток сделать модели объяснимыми. Некоторые из них не зависят от модели (Ribeiro et al., 2016 24), в то время как большинство ссылаются на конкретный тип модели, например, классификаторы на основе правил (Dash et al., 2015 10; Malioutov et al., 2017 19), модели ближайших соседей (Kim et al., 2016 15) и нейронные сети (Kim et al., 2017 16).
Несмотря на схожее название, наша работа принципиально отличается от работы Балестриеро (2017 2), который разработал своего рода «перевернутое» дерево решений, реализованное нейронной сетью. На сайте
Похожие работы
Альтернативные приводы дерева решений. Обычные ДТ исследуются путем рекурсивной «жадной» декомпозиции признаков (Quinlan, 1993; Breiman et al., 1984 23). Это эффективно и имеет некоторые преимущества при выборе признаков, но такой «жадный» поиск может оказаться неоптимальным (Norouzi et al., 2015 20). В некоторых недавних работах изучались альтернативные подходы к обучению деревьев решений, направленные на достижение более высокой производительности при менее сложной оптимизации, такие как прогнозирование латентных структурированных переменных (Norouzi et al., 2015 20) или обучение разделителей RNN с использованием обучения с подкреплением (Xiong et al., 2017 28). В отличие от них, наш DNDT намного проще, чем вышеупомянутый, но все же потенциально может находить лучшие решения, чем традиционные индукторы DT, благодаря одновременному поиску структуры дерева и параметров с помощью SGD. Наконец, следует отметить, что обычные DT-индукторы для простоты используют только двоичные распады, в то время как модель DNDT может работать с произвольными распадами мощности, что иногда приводит к более интерпретируемым деревьям.
3.1 Работа мягкого контейнера
Ключевым модулем, который мы реализуем здесь, является функция мягкого контейнера (Dougherty et al., 1995), или объединение наборов точечных объектов в динамические полигоны (бины), которые мы будем использовать для принятия решений о разбиении в DNDT. В общем случае функция разбиения принимает на вход реальную шкалу x и извлекает индекс ячейки, которой она принадлежит. Жесткое деление клеток является недифференцируемым, поэтому мы предлагаем дифференцируемый подход к этой функции.
Предположим, у нас есть непрерывная переменная x, которую мы хотим разделить на N + 1 интервалов. Это приводит к необходимости определения n точек отсечения, которые в данном контексте являются переменными обучения. Обозначим точки отсечения β1, β2,…, βn как монотонно возрастающие, т.е. β1
Методология
Теперь постройте однослойную нейронную сеть с функцией активации softmax.
Здесь w — константа, а не обучаемая переменная, и ее значение задано как w = 1? 2; : : : : ; n + 1. b строится следующим образом,
0 — коэффициент напряжения. Когда τ → 0, выход стремится к текущему вектору.<β2<· · ·<βn. Во время обучения порядок β может быть перетасован после обновления, поэтому мы должны сначала сортировать их в каждом прямом проходе. Однако это не повлияет на дифференцируемость, потому что сортировка просто меняет местами позиции β .
Мы можем проверить это, рассмотрев три последовательных логита.
Если мы примем за
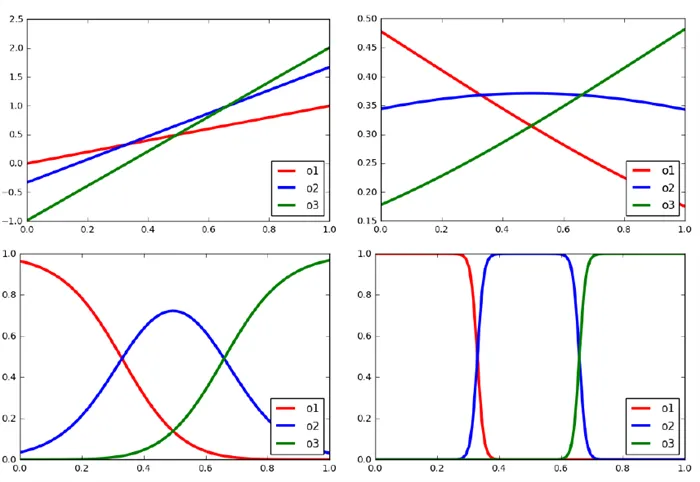
τ>x должно попадать в интервал
Таким образом, нейронная сеть уравнения 1 производит почти равномерное «горячее» кодирование x, особенно при низких интенсивностях. При желании мы можем использовать прием «отжига по склону» (Chung et al., 2017 9), когда напряжение обучения постепенно уменьшается, чтобы в итоге получить более детерминированную модель.
Если предпочтение отдается текущему «горячему» (закодированному в данный момент) вектору, можно применить прямой (ST) Gumbel softmax (Jang et al., 2017): для
DNDT концептуально проста и легко реализуется с помощью ≈20 строк кода в TensorFlow или PyTorch. Поскольку DNDT реализована в виде нейронной сети, она поддерживает ускорение на GPU и обучение на мини-пакетах данных, которые не помещаются в памяти, благодаря современным фреймворкам глубокого обучения.
4.2 Наборы данных и конкуренты
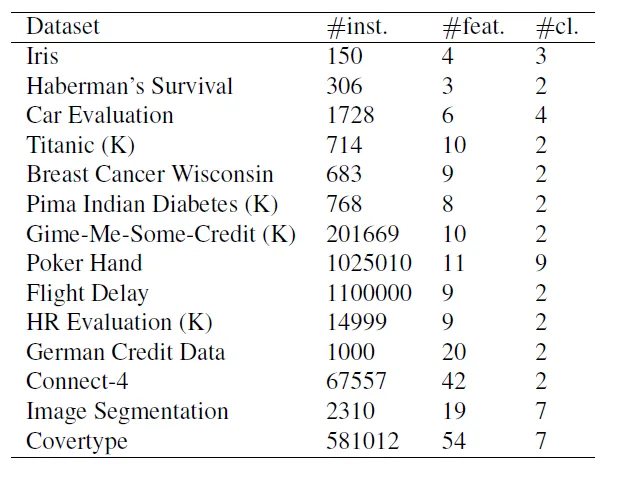
Мы сравнили ДНДТ с нейронными сетями (реализованными в TensorFlow (Abadi et al., 2015) 1) и деревом решений (из Scikit-learn (Pedregosa et al., 2011 22)) на 14 наборах данных, собранных Kaggle и UCI (подробности о наборах данных см. в таблице 1).
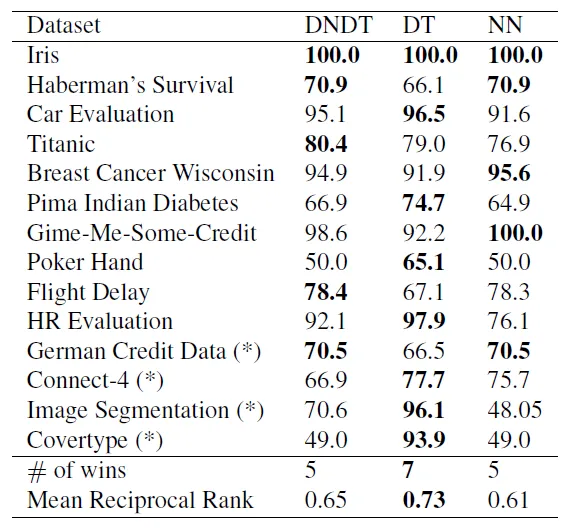
Для базового дерева решений (ДР) мы определили два основных критерия для гиперпараметров: критерий «Джини» и «лучший» разделитель. Для нейронной сети (НС) мы используем архитектуру с двумя скрытыми слоями по 50 нейронов в каждом для всех наборов данных. DNDT также имеет гиперпараметр — количество точек отсечения для каждого объекта (фактор ветвления), который мы установили равным 1 для всех объектов и наборов данных. Подробный анализ влияния этого гиперпараметра приведен в разделе 4.4. Для наборов данных с более чем 12 признаками мы используем набор DNDT, где каждое дерево случайным образом выбирает 10 признаков, и в общей сложности мы имеем 10 уровней. Окончательный прогноз выносится большинством голосов.14.3 Точность2Мы оцениваем производительность моделей DNDT, дерева решений и нейронной сети для каждого из наборов данных, перечисленных в таблице 1. Точность тестового набора показана в таблице 2.3В целом, DT является наиболее эффективной моделью. Хорошая производительность DT неудивительна, поскольку эти наборы данных в основном состоят из матриц, а размерность объектов относительно низкая.
Эксперименты
Традиционно говоря, нейронные сети не имеют явного преимущества при работе с таким типом данных. Однако ДНДТ несколько лучше, чем «обычная» нейронная сеть, поскольку ее построение ближе к дереву решений. Конечно, это лишь предварительный результат, поскольку все эти модели имеют настраиваемые гиперпараметры. Тем не менее, интересно, что ни одна модель не имеет доминирующего преимущества. Это напоминает теорему о «бесплатном обеде» (Wolpert, 199627).
4.4 Анализ активных точек отсечения
В DNDT количество точек отсечения на объект является параметром сложности модели. Мы не коррелируем значения точек отсечения, что означает, что некоторые из них неактивны, т.е. они либо меньше минимального значения x
или больше максимального значения x
В этом разделе мы исследуем, сколько точек отсечения фактически используется после обучения ДНДТ. Точка отсечения активна, если по обе стороны от нее находится хотя бы один экземпляр из набора данных. Для четырех наборов данных — Car Evaluation, Pima, Iris и Haberman — мы определяем количество
Аннотация: Обобщен опыт построения и исследования конкретных систем принятия решений и построена методология их построения. Методология сопровождается рекомендациями по упрощению систем принятия решений и сведению логических нейронных сетей к однослойным сетям. Это облегчает проверку за счет достижения полноты и согласованности, снижения требований к вычислительной мощности и возможности использования программных и аппаратных средств общего назначения. Таким образом, ассоциативное мышление, формирующее нейронную сеть, становится четким и всеобъемлющим, что характерно для военных.
Я выбрал свой путь
И я иду один, без шума,
Давайте объединим некоторые из вышеперечисленных рекомендаций.
1. можно понять природу развития нетренированного мозга, который должен наполняться знаниями на протяжении всей жизни. Другая — разработка средств хранения и соотнесения знаний.
Почему такой круговой аргумент: сначала выбрать нейронную сеть, затем наполнить ее знаниями — обучить ее? Является ли это просто вопросом максимизации научного сходства наших исследований?dБеря на себя решение конкретной задачи распознавания, управления или принятия решений, мы пытаемся решить эту проблему ИИ самым простым способом. Ведь на основе логического описания проблемы мы можем сразу же создать уже обученную нейронную сеть! Мы видели, что такая нейронная сеть допускает любое развитие.d.
Прискорбно, когда исследователь, даже прослушав курс, не принимает предложенные результаты. Он следует «классическому» пути, о котором говорилось выше, и удивляется, услышав комментарий:
Методика построения системы принятия решений на основе логической нейронной сети
— Видите, в результате обучения методом «распространения ошибок» вы получили те же веса синапсов, которые могли бы получить, непосредственно построив обученную логическую нейронную сеть на основе логического описания системы принятия решений! Но это очень просто.
2. задача «живого» нейрона, зависящего от «мясных» технологий, сложна. Известно, что для того, чтобы произошла стимуляция, должно произойти до 240 химических реакций! Но нас интересует только логика их работы, и моделировать эти реакции на логическом уровне не имеет смысла. Информационные технологии логических нейронных сетей используют простые функции активации, некоторые типы которых уже обсуждались. Однако при моделировании нейрона он может быть представлен либо как аппаратное обеспечение — как часть нейрокомпьютера — либо как программный процесс. В целом, это следует понимать следующим образом: Нейрон (элемент, напоминающий нейронную сеть) может быть смоделирован как нейрон
Логические нейронные сети, основанные на логическом описании системы управления или принятия решений в терминах алгебры утверждений о принадлежности входных данных — значений, объектов, диапазонов изменения — подходят для ассоциативных рассуждений. Если СПР функционально четко определена и может быть описана в терминах математической логики, то имеет смысл построить обучаемую нейронную сеть на основе этого описания. Простота такой конструкции помогает гарантировать, что обученная нейронная сеть может быть легко разработана или перестроена при изменении СПР. В то же время, подход к обучению или переобучению нейронной сети с определенной структурой для конкретного приложения является целесообразным. Алгоритмы для такого обучения представлены в 6, 7.
Структура обученной логической нейронной сети полностью совпадает со структурой логической системы управления и принятия решений.
Создание полного и последовательного логического описания является первым шагом в применении техники построения логической нейронной сети для SPR.
Уже было показано, что SDN описывается с точки зрения алгебры высказываний (математической логики) системой логических выражений следующего вида.
( 13.1)
где, — логические функции объявленных переменных выражений, значение которых определяет принимаемое решение.
Для непротиворечивости и полноты SPR необходимо и достаточно, чтобы каждая декларативная функция в (13.1) принимала значение TRUE и чтобы в системе (13.1) не существовало такого набора декларативных переменных на основе факторного пространства событий, для которых все логические функции имеют значение TRUE.
Напомним, что в логическом описании СПР используются операции конъюнкции и дизъюнкции, но не операция отрицания. Это объясняется тем, что в интересах корректности и полноты представления темы исследования в СДА каждый задействованный фактор должен быть учтен в рамках комплексной событийной модели. Необходимо рассмотреть все возможные значения или состояния этого фактора. Каждый фактор A представлен набором состояний (событий, значений, диапазона значений).
Это множество должно быть смоделировано таким образом, чтобы выполнялось условие нормализации, где .
При разработке системы наказания водителей, которые ездят с превышением скорости, представляется разумным охватить весь возможный диапазон ожидаемых скоростей:
Такое описание учитываемого фактора, в данном случае скорости, оставляет без ответа вопрос: «Что делать, когда скорость попадает в непредсказуемый диапазон колебаний?».
В рассматриваемом методе правильного и полного рассмотрения всех возможных эрей
Правила эквивалентных преобразований логических выражений известны. (В теории математической логики такое преобразование связано с образованием дизъюнктивных или идеально дизъюнктивных регулярных форм). Однако уже упомянутая особенность дистрибутивного свойства гарантирует возможность гарантировать уникальность вхождения каждой переменной, используемой в отдельном логическом выражении, с помощью последовательных скобок.
Необходимость в таком преобразовании возникает из-за замены операций конъюнкции и дизъюнкции их приблизительным «заменителем» — функцией активации. На практике такая функция основана на суммировании (взвешенных) сигналов на входе нейрона. Тогда повторное появление, т.е. суммирование, одних и тех же сигналов становится неприемлемым.
| Однако такая трансформация не всегда бывает успешной. Далее применяется техника умножения решений, основанная на том, что логическое выражение делится на подвыражения, связанные операцией дизъюнкции (это и есть дизъюнктивная каноническая форма). |
В результате преобразований каждое выражение логического описания обычно представляет собой скобочную нотацию с более чем одним уровнем вставки.
Однако указанное выше свойство функции активации, сводящее две логические операции к одной — арифметической, приводит к значительному упрощению нейронной сети, то есть к ее сведению к одному уровню.
Ранее было показано, что такое сокращение всегда возможно с помощью техники умножения решений. Однако это приводит к «расщеплению» сети, к умножению путей, ведущих к одним и тем же решениям, к перегрузке сети определенной фиксированной структурой на этапе ее обучения.
В то же время, многие реальные процессы, в силу своей конструкции (экономические системы, системы управления, технологические системы и т.д.), подходят не только для однослойных логических нейронных сетей, но даже для совершенных сетей. В их описании левая часть любого логического выражения является объединением «представителей» всех обязательно исчерпывающих наборов событий, которые вместе образуют пространство агентов.
Целесообразно проанализировать возможность построения однослойной нейронной сети на этом же этапе методологии, до выполнения преобразований распределения.
 Дистрибутивные преобразования логического описания и возможности упрощения
Дистрибутивные преобразования логического описания и возможности упрощения
Для лучшего понимания текущей ситуации на рынке труда
Сборник из более чем 50 ресурсов из сектора информационных технологий
Только лучшие Telegram-каналы, YouTube-каналы, подкасты, форумы и многое другое, чтобы узнать больше об ИТ.
50+ лучших сервисов и приложений от Geekbrains.
Безопасное и надежное программное обеспечение для работы в наши дни
Однако на нейронные сети нельзя полностью полагаться. Они могут использоваться в качестве эффективного дополнения к другим методам, но не являются единственным способом достижения цели. На это есть несколько причин:
Это объясняет, почему нейронные сети не могут быть использованы для выполнения последовательных действий. Например, чтобы решить обычное математическое уравнение, необходимо выполнить несколько операций, причем каждая последующая операция вытекает из предыдущей. Для ANN это невыполнимая задача.
Область применения ИНС — решение аналитических задач, сравнимых с теми, с которыми постоянно сталкивается человеческий мозг. В большинстве случаев нейронные сети помогают быстро достичь результатов в следующих областях:
Вышеперечисленные области не ограничиваются применением нейронных сетей, существуют и другие существующие и перспективные способы их использования для решения различных задач:
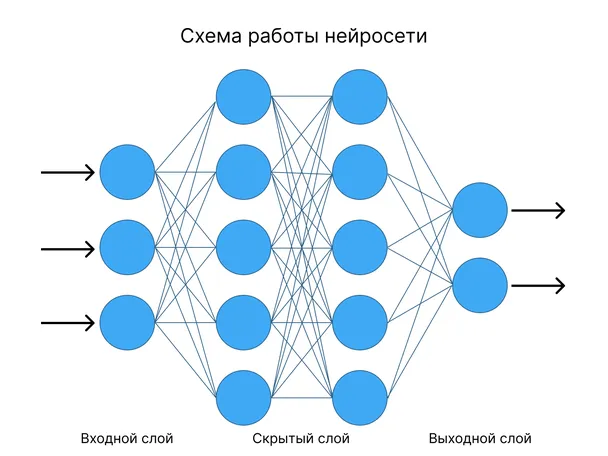
Каждая ИНС состоит из первого слоя нейронов, входного слоя, который принимает сигналы и передает их другим нейронам. Эта особенность объединяет все сети, и в зависимости от их дальнейшей структуры и принципа, по которому различные слои нейронной сети взаимодействуют друг с другом, можно выделить различные типы.
Эта структура характеризуется тем, что сигнал движется строго от входного слоя к последнему слою. ИНС этого типа хорошо зарекомендовали себя в таких задачах, как распознавание, прогнозирование и кластеризация.
Плюсы и минусы нейронных сетей
Рассмотрим принцип работы этого типа нейронной сети на примере. Как наш мозг узнает, что на картинке изображена собака? Он использует набор функций, которые хранятся в нашей памяти. Если объект на фотографии или изображении соответствует списку признаков, характерных для собак (четыре лапы, соответствующий размер, хвост, шерсть и т.д.), мозг подтверждает, что это то животное, которое мы видим. Собака может быть зеленой или обезвоженной, но это не мешает нам видеть в ней собаку.
- Способность игнорировать постороннюю информацию. Представьте, что вы с другом находитесь в вагоне метро и ведете увлекательную беседу. Вокруг вас множество фоновых звуков: шум поезда, объявления по радио, разговоры других людей, плач ребенка и так далее. Вы слышите все это, но при этом сосредоточены только на словах собеседника. Нейросети после обучения ведут себя аналогично: отметают лишнюю информацию, не имеющую отношения к поставленной задаче.
- Возможность сохранять работоспособность в случае утраты отдельных элементов. Предположим, что человек потерял палец в результате несчастного случая. Оставшиеся пальцы позволяют ему продолжать полноценную жизнь, поскольку функции удаленного фрагмента тела перераспределились между оставшимися. Идентичная ситуация складывается с нейросетью: повреждение некоторых компонентов не мешает ей выдавать верный результат.
- Высокая скорость работы. Благодаря тому, что ИНС состоит из тысяч микропроцессоров, взаимодействующих между собой, задачи решаются намного быстрее, чем стандартными способами.
Нейронная сеть работает по тому же принципу. Группы нейронов анализируют изображение и выбирают, какими характеристиками должен обладать тот или иной объект. В случае с собакой основным признаком может быть строение тела, а затем ANN определяет другие признаки — форму головы, шерсть, хвост и т.д. Выход сети определяет, можно ли считать животное на изображении собакой или нет.
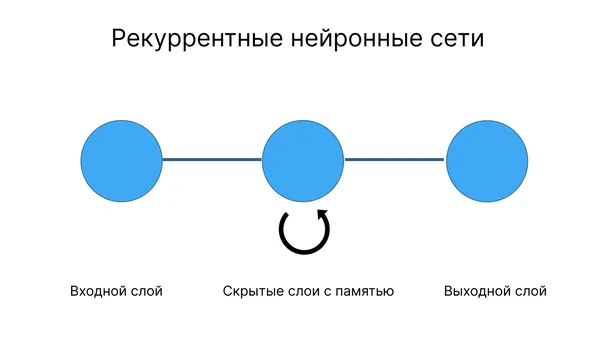
Перспективные сети не способны запоминать результаты предыдущего анализа. Информация направлена только вперед, и ее работа похожа на сложные алгоритмы.
После обучения такая нейронная сеть определяет, какие признаки должны присутствовать у собаки, но каждый раз выполняет анализ с самого начала.

Рекуррентные нейронные сети характеризуются наличием памяти: Они способны провести аналогию между текущим состоянием и предыдущим. Такая ИНС сравнивает предложенное изображение собаки с изображением, которое она «видела» в прошлом.
Однако, чтобы лучше понять специфику этого типа нейронной сети, давайте рассмотрим ее работу на другом примере. Такие ИНС помогают решать задачи, отличные от распознавания; чаще всего они используются для генерации последовательностей.
Проблема с автоматическими переводчиками, например, заключается в низком качестве результата. Программа сопоставляет значение слова в исходном языке с соответствующим вариантом в другом языке и определяет синтаксическую функцию лексической единицы, но окончательный перевод может быть бессмысленным.
Как за 3 часа узнать о компьютерной науке больше, чем 90% новичков, и заработать ₽ 200 000?
Приглашаем вас присоединиться к нашей бесплатной интенсивной онлайн-программе «Путь в ИТ»! Всего за несколько часов эксперты GeekBrains поймут, как работает ИТ-индустрия, как в нее войти и развиваться.
Интенсивный курс «Путь в ИТ» поможет вам в этом:
Архитектура, на которой основаны нейронные сети, играет особую роль в развитии ИИ. По мнению Антона Колонина, ведущего эксперта Новосибирского государственного университета, основателя проекта персонального ИИ Aigents, архитектора децентрализованной платформы ИИ SingularityNET и эксперта Российского совета по международным делам, область ИИ находится на подъеме и показывает все более впечатляющие результаты благодаря внедрению нового типа архитектуры нейронных сетей — трансформеров.
- Предлагаемый ИНС ответ не будет абсолютно точным, только примерным. Следовательно, нельзя полностью полагаться на результаты работы нейросети, поскольку всегда есть вероятность недостоверного решения.
- Каждый искусственный нейрон действует независимо от соседних, он не соотносит свое поведение с другими микропроцессорами. Специфика ИНС заключается в том, что нет гарантии абсолютной правдивости результата.
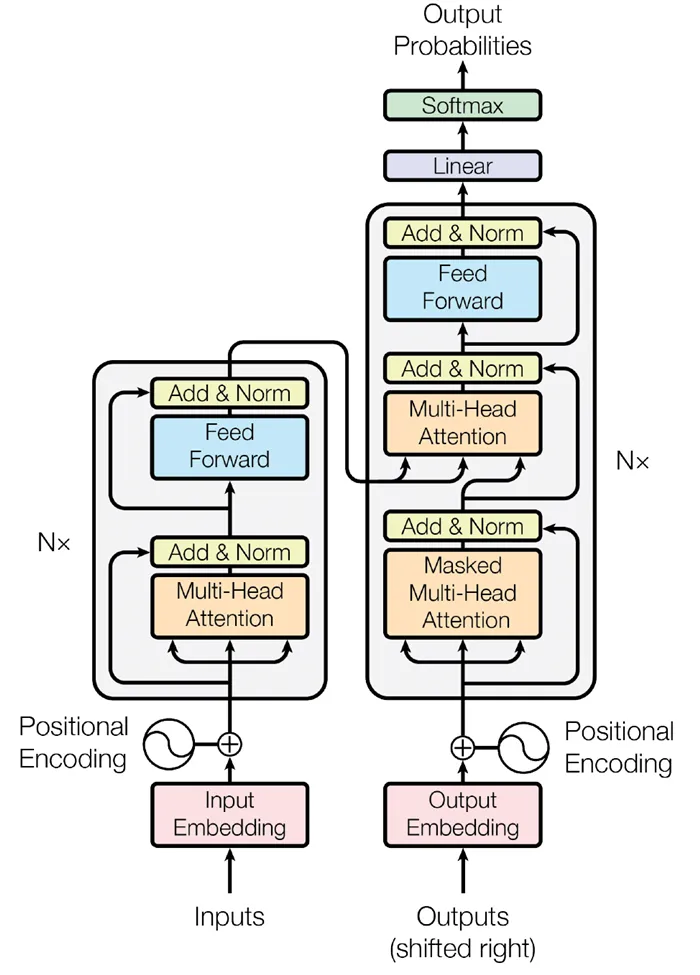
Трансформеры — это тип нейронных сетей, которые нацелены на решение последовательностей путем обработки зависимостей. Поэтому трансформеры не обрабатывают последовательности по порядку, а могут сразу сосредоточиться на нужных данных благодаря «механизму внимания». Этот же механизм позволяет трансформатору выбирать подходящий ответ на основе контекста входной информации, например, синонимов. Это позволяет увеличить скорость обучения такой нейронной сети.
Задачи и области применения нейронных сетей
Основными компонентами трансформаторов являются кодер и декодер. Первый преобразует входящую информацию (например, текст) в вектор (ряд чисел). Второй декодирует вектор в новую последовательность (например, ответ на вопрос), но из слов на другом языке.
- Классификация. ИНС определяет, соответствует ли анализируемый объект заданным параметрам, и относит его к той или иной группе. Возможности нейронных сетей используют банки для предварительной оценки платежеспособности претендента на заем.
- Прогнозирование. На основе изучения входных данных ИНС предсказывает, как поведут себя в ближайшее время на фондовом рынке акции конкретной компании – вырастут или упадут в цене.
- Распознавание. На данный момент эта функция применяется чаще остальных. Поиск по фото в Яндексе или Google, возможность отметить лица друзей на фото в социальных сетях и другие современные возможности обеспечены именно умением ИНС выделять объект среди множества подобных.
Колонин отмечает, что достижения в обучении нейронных сетей требуют включения миллиардов параметров. Это позволяет строить очень сложные сети на основе трансформаторных архитектур. В качестве примеров эксперт приводит алгоритмы обработки естественного языка BERT от Google (обученные на всех текстах Википедии и книжного корпуса) и GPT-3 от OpenAI (обученный на 175 миллиардах параметров). Параллельно с увеличением количества параметров происходит мультимодальное обучение систем на разнородных данных, например, не только на текстах, но и на текстах с изображениями. В качестве примера эксперт приводит картину американца Джейсона Аллена, которая была создана с помощью алгоритма Midjourney и победила в ежегодном конкурсе художников в
- Машинное обучение является одной из разновидностей искусственного интеллекта. Google, Яндекс, Бинг, Байду активно применяют machine learning для повышения релевантность результатов запросам пользователей. Алгоритмы самообучаются, опираясь на миллионы однотипных фраз, вводимых в поисковую строку.
- Для нормального функционирования роботов необходимо разрабатывать множество алгоритмов, и здесь не обойтись без нейросетей.
- Возможности ИНС используются архитекторами компьютерных сетей, чтобы справиться с проблемой параллельных вычислений.
- В математике нейронные сети позволяют быстрее решать сложные задачи.
Виды нейросетей
Трансформируемые нейронные сети быстро вошли в область обработки естественного языка. В России, например, Яндекс использует их в своих сервисах. Затем выяснилось, что эти модели могут решать и другие задачи, например, классифицировать части слов в тексте, определять «настроение» текста и т.д., говорит эксперт. В настоящее время область применения трансформеров расширяется за счет приложений в генерации изображений (алгоритмы DALL-E, midjourney) или биотехнологии (система AlphaFold для предсказания белковых структур).

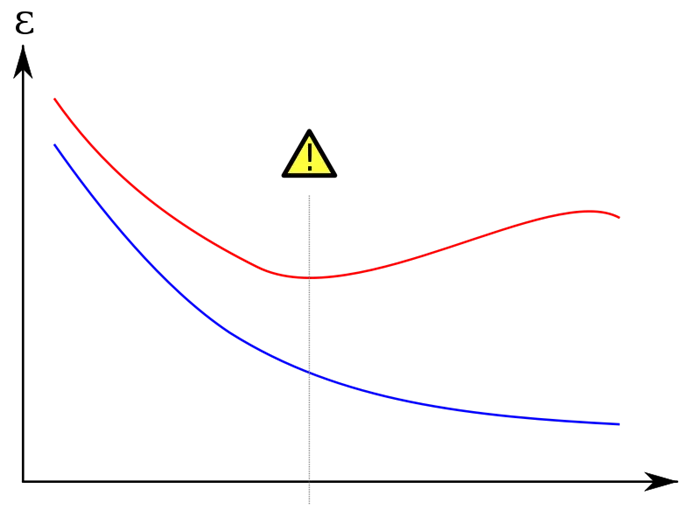
Красная кривая показывает уровень ошибок в сгенерированном наборе данных, который выше, чем в исходном наборе данных (синяя кривая) (Фото: medium.com)
Евгений Павловский, ведущий научный сотрудник лаборатории анализа потоковых данных и машинного обучения Новосибирского государственного университета, считает, что одним из способов упростить процесс «обучения» нейронной сети является применение полусамостоятельного обучения. По его словам, в этом методе данные не нужно маркировать, и алгоритм обучается сам, определяя структуру текстов и изображений. GPT-3 был подготовлен с использованием такого метода. «Существует метод маскировки, когда мы удаляем слово, а алгоритм пытается предсказать его по соседним словам. На основе этого строится модель прогнозирования. Алгоритм сам оценивает, создал ли он хорошую модель или нет. Если вы дадите ему читаемый текст, он не только выучит текст, но и поймет понятие грамотности и сможет правильно расставлять знаки препинания», — говорит эксперт.
Например, ученые из Массачусетского технологического института, Корнельского университета и Университета Макгилла продемонстрировали систему искусственного интеллекта, способную самостоятельно изучать правила и закономерности человеческого языка. Система способна объяснить, почему слово изменило свою форму в зависимости от пола, времени или падежа. Исследователи обучили модель, используя задания из лингвистических учебников по 58 различным языкам.
Алгоритмы, распознающие изображения или тексты, считаются высокоспециализированными. Однако самой большой проблемой для исследователей является создание искусственного общего интеллекта (AGI).
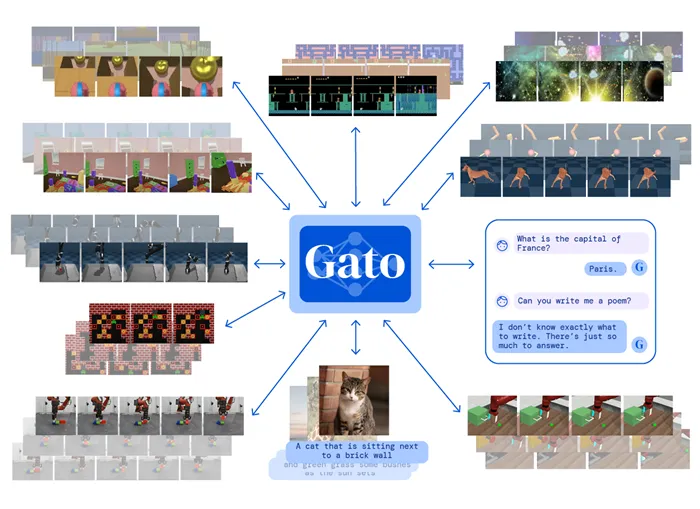
Некоторые исследовательские группы разрабатывают модели глубокого обучения, которые могут работать на текущей архитектуре, но в многозадачном режиме. Например, исследователи из команды Google Brain и Университета Торонто сообщили о MultiModel — архитектуре нейронной сети, построенной на успешном опыте визуальных, лингвистических и слуховых сетей, которая может распознавать изображения и речь и переводить с одного языка на другой.

Антон Колонин, который занимается исследованиями в области ИИ уже 25 лет, отмечает, что до сих пор нет единого мнения о том, каким должен быть общий ИИ. «Некоторые люди считают, что система должна быть такой же интеллектуальной, как человек. Другие считают, что это технология, которая адаптируется к любым условиям: Если его поместить в человеческую среду, он станет похож на человека, если его поместить в кошачью среду, как кошку, в астероидное кольцо, он научится перетаскивать его на Землю и добывать полезные ископаемые. Другие считают, что AGI — это просто технология, которая может быстро создавать прикладные интеллектуальные решения любых проблем», — говорит он.
Некоторые ученые считают, что сначала нужно выяснить, как работает человеческий интеллект, чтобы воспроизвести его в AGI. Другие исследователи считают, что нет необходимости разбираться в деталях разумного поведения и мышления. Мы можем понять основные принципы и воспроизвести их в компьютерных моделях без обращения к нейрофизиологии, объясняет Колонин.
Однако уже существует несколько гипотез о том, как может быть создан AGI. Первый — это создание больших нейронных сетей и их комбинирование различными способами. Вторая заключается в том, что чистые нейронные сети — это тупик, и что необходимы математические методы, основанные на вероятностной логике. Сторонники третьей гипотезы считают, что необходимо объединить современные методы обучения глубоких нейронных сетей и формальные математические методы.

Нейросети-трансформеры


Проблемы обучения нейросетей
- слишком большой объем данных. Чем более мощную нейросеть требуется обучить, тем больше параметров необходимо настроить, а каждый из них включает в себя огромные массивы информации. Например, программе распознавания речи потребуются терабайты данных для изучения одного языка. Правда, группа исследователей из Microsoft и Гарвардского университета уже пытается решить эту проблему. Исследователи разработали архитектуру нейросети, при обучении которой можно сократить количество параметров до константы, даже если сеть состоит из триллионов узлов. Исследование демонстрирует, что простая архитектура нейросети может обучаться так же хорошо, как любой алгоритм для выборки ограниченного размера;
- сложность переобучения. Если в видимых наборах данных есть ошибка, то сложная модель будет генерировать ее уже в собственных данных;
- оптимизация гиперпараметров — параметров, значение которых определяется до начала процесса обучения. Изменение значения таких параметров на небольшую величину может привести к значительному изменению производительности модели;
- потребность в высокопроизводительном оборудовании. Чтобы повысить эффективность и сократить затраты времени, специалисты по обработке и анализу данных переходят на высокопроизводительные графические процессоры, но они дорого стоят и потребляют много энергии;
- проблема «черного ящика». Исследователи знают параметры модели, но не всегда понимают, как нейросети приходят к тому или иному решению. Из-за этого они могут выдавать ложные утверждения и даже использоваться во вред, как это было в экспериментах с GPT-3;
- отсутствие гибкости и многозадачности. Модели глубокого обучения могут обеспечить чрезвычайно эффективное и точное решение конкретной проблемы, но пока архитектуры узкоспециализированы для конкретных областей применения.
Универсальный искусственный интеллект