Эта же задача часто усложняется, когда необходимо определить не только вид, но и породу животного. Помимо классификации по видам, необходимо подразделение по породам, что требует большого количества меченых изображений.
Датасет (Dataset)

Набор данных — 1. Исследуемый набор данных, который, в силу своего размера, находится одновременно на нескольких компьютерах. 2. выборка из огромного количества данных, созданная с целью демонстрации принципа или концепции машинного обучения (ML):
Наборы данных — это основа науки о данных, материал, на котором базируются все исследования. В контексте науки обычно рассматриваются два типа данных: традиционные данные и Большие данные.
Традиционные и Большие данные
Традиционные данные структурированы и хранятся в базах данных, управляемых компьютером; они представляют собой табличное представление с числовыми или текстовыми значениями. Мы вводим прилагательное «традиционный» для ясности: оно помогает подчеркнуть различия.
Большие данные, с другой стороны, более обширны, чем традиционные данные, как с точки зрения разнообразия (числа, текст, изображения, картинки, аудио, видео и т.д.), так и с точки зрения скорости извлечения и вычисления в реальном времени и объема (терабайты, пета, экзабайты и т.д.). Большие данные обычно распределяются по компьютерной сети. Таким образом, обучающие наборы данных, «игры», которые мы используем для освоения моделей и особенностей ближайших соседей машинного обучения, являются метонимией (перенос названия с одного объекта или явления на другой на основе близости).
Виды датасетов
Наука делит наборы данных на три категории:
Простая запись
Это самая простая форма, где нет явной связи между строками наблюдений и столбцами атрибутов, и каждая строка имеет одинаковый набор атрибутов. Эти записи обычно хранятся либо в файлах (.csv, .parquet), либо в реляционных базах данных:

Существует несколько подтипов простых файлов:
- Транзакционные данные: например, покупки в супермаркете. Чаще всего это двоичные признаки, указывающие, был ли предмет куплен или нет:
- Матрица разреженных данных (иногда также матрицей данных документа): особая разновидность матрицы данных, в которой признаки одного типа и асимметричны; т.е. важны только ненулевые значения:
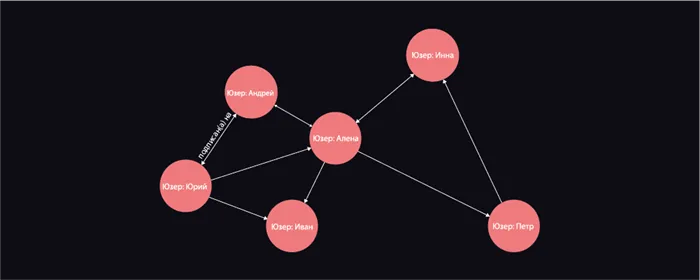
Графы
- Данные со связями между объектами : отношения между объектами фиксируются связями:

- Структурированные графы : узловые компоненты взаимосвязаны друг с другом определенным образом:
Упорядоченные записи
Некоторые данные упорядочены по времени или пространству. Их можно разделить на следующие типы:
- Последовательные данные состоят из набора отдельных объектов, таких как слова или буквы. Здесь нет временных меток; вместо этого есть позиции в упорядоченной последовательности:

- Временной ряд (Time Series) – это особый тип последовательных данных, в которых каждая запись представляет собой временной ряд, то есть серию измерений, выполненных во времени:

- Пространственные данные имеют координаты:
Что такое датасет для Data Mining и из чего он состоит
Набор данных машинного обучения обрабатывается, и информация структурируется в виде таблицы. Строки такой таблицы называются объектами, а столбцы — атрибутами. Различают 2 типа атрибутов 1 :
- независимые переменные – предикторы ;
- зависимые переменные – целевые признаки, которые вычисляются на основе одного или нескольких предикторов.
Атрибутивное описание характерно для задач классификации, когда имеется выборка — конечное множество объектов, для которых известно, к каким классам они принадлежат. Классовая принадлежность остальных объектов неизвестна. В процессе машинного обучения создается модель, способная классифицировать любой объект из исходного набора. Практическая важность задач классификации заключается в предсказании возможных исходов на основе набора входных переменных, например.
Вероятностная модель получения данных предполагает, что выборка берется случайным образом из популяции. Если все его элементы в исходной совокупности (популяции) одинаково случайны и независимо распределены, то выборка называется простой. Простая случайная выборка представляет собой математическую модель набора независимых экспериментов и часто используется для машинного обучения. В этом случае для каждого этапа машинного обучения требуется свой набор данных 3 :

- один столбец с двоичными значениями (1/0, TRUE/FALSE и пр.): двухклассовая классификация (binary classification), когда каждый объект принадлежит только одному классу;
- несколько столбцов с двоичными значениями : задача классификации с пересекающимися классами (multi-label classification), когда один объект может принадлежать нескольким классам;
- один столбец с действительными значениями : регрессионный анализ, когда прогнозируется одна величина;
- несколько столбцов с действительными значениями : задача множественной регрессии, когда прогнозируется несколько величин.
Каким бывает dataset: типы выборок
Методы, используемые для создания обучающих и оценочных образцов, зависят от класса проблемы, которую необходимо решить с помощью машинного обучения 1 :
При соблюдении этих условий размеры обучающей и оценочной выборок могут существенно различаться. Например, размер проверочного набора данных может составлять всего 10% от общей численности населения. Самое главное, что нужно помнить при построении выборок, — это то, что обучающий набор данных никогда не объединяется с наборами данных оценки (тестовым и валидационным), так как это может привести к переподгонке модели машинного обучения. В этом случае модель получает высокие оценки качества во время обучения, но не показывает таких результатов на реальных данных.
- для непосредственного обучения модели нужна обучающая выборка (training sample), по которой производится настройка (оптимизация параметров) алгоритма;
- для оценки качества модели используется тестовая (контрольная) выборка (test sample), которая, в идеальном случае, не должна зависеть от обучающей;
- для выбора наилучшей модели машинного обучения понадобится проверочная (валидационная) выборка (validation sample), которая также не должна пересекаться с обучающей.
Как сформировать выборку для Data Mining
После создания образца выполняются следующие процедуры CRISP-DM: Очистка данных и работа с признаками: создание, преобразование, нормализация и отбрасывание избыточных переменных для устранения мультиколлинеарности факторов и снижения размерности модели машинного обучения. Об этом мы расскажем в следующих статьях.
- для задач классификации данные следует разделить так, чтобы в полученных наборах численное соотношение объектов разных классов было таким же, как в исходной генеральной совокупности;
- для задач регрессионного анализа необходимо одинаковое распределение целевой переменной в полученных наборах, которые будут использоваться для обучения и контроля качества.
Вся практика подготовки данных в нашем новом курсе для аналитиков Больших Данных: Подготовка данных для Data Mining. Участвуйте!
Ресурсы

Современный специалист по DS редко испытывает недостаток в наборах обучающих данных. Например, для разработки рекомендательных систем вы можете найти набор данных, относящийся непосредственно к конкретному случаю бизнеса: онлайн-кинотеатру, онлайн-бизнесу, текстовому блогу или социальной сети. В частности, мы хотели бы порекомендовать следующие наборы данных:
Самый полный список обновляемых наборов данных можно найти в Google Search Dataset — более 100 наборов данных из многих источников и практически для любого бизнес-приложения. В целом, для разработки рекомендательной системы важен обучающий набор данных с большим количеством данных, и эта работа в основном исходит от предприятий.
Датасеты для обучения рекомендательных систем
Необходимо также решить вопрос о метриках для оценки качества выработанных рекомендаций. И помните, что стоимость сбора фактических данных для разработанной рекомендательной системы может быть достаточно высокой. Поэтому, прежде чем обучать ML-модель на подробном наборе данных с большим количеством наблюдений, подумайте о том, как природа реального
- MovieLens 25M Dataset – набор рейтинговых данных с веб-сайта MovieLens, который описывает 5-звездочные рейтинги и действия с произвольным тегированием по более 60 тысячам фильмов от 1,5 миллионов пользователем с 1995 по 2019 годы. MovieLens – это «семейство» датасэтов. Самый востребованный, разумеется, самый полный — 25M, но часто используют только часть записей, например, 1 миллион, или 100 тысяч. Все датасеты есть по этой ссылке. https://grouplens.org/datasets/movielens/
- Netflix Prize — многовариантный датасет временных рядов, который использовался в конкурсе Netflix Prize с рейтингами примерно 100 миллионов фильмов. В наборе данных более 480000 пользователей, каждый из которых промаркирован уникальным целочисленным идентификатором. С помощью этого датасета можно предсказать недостающие записи в матрице рейтинга пользователей фильма. http://academictorrents.com/details/9b13183dc4d60676b773c9e2cd6de5e5542cee9a
- Book-Crossing – датасет с рейтингами около 300 тысяч миллионов книг и обезличенными демографическими данными о более 250 тысячах их читателей. http://www2.informatik.uni-freiburg.de/~cziegler/BX/
- Amazon Review Data – многомиллионный набор обзоров, рейтингов и метаданных продуктов (описание, категория, цена, бренд, характеристики, фото), а также данные о просмотре ссылок. Общее количество обзоров в этом наборе данных более 233 тысяч миллионов. https://nijianmo.github.io/amazon/index.html
- Yahoo! Music User Ratings — коллекция Yahoo! Music о предпочтениях пользователей к разным музыкальным исполнителям. Датасет содержит более 10 миллионов оценок музыкальных исполнителей и подходит для проверки рекомендательных систем или алгоритмов колабративной фильтирации. Но, чтобы его скачать, нужно запрашивать разрешение на использование данных. https://webscope.sandbox.yahoo.com/catalog.php?datatype=r
- LastFM – датасет содержит информацию о социальных сетях, тегах и прослушивании музыкальных исполнителей от 2 тысяч пользователей онлайн-музыки Last.fm. Это коллекция из 17 632 музыкальных исполнителей, которых слушали и отметили пользователи. https://files.grouplens.org/datasets/hetrec2011/
- Social Network Influencer – датасет Peerindex, который включает стандартную задачу изучения парных предпочтений. Здесь каждая точка данных описывает двух человек и предварительно рассчитанные стандартизованные функции на основе активности в Twitter: объем взаимодействий, количество подписчиков и пр. для каждого человека. С помощью этого набора данных можно обучить ML-модель для прогнозирования веса блогера, т.е. его влияния. https://www.kaggle.com/c/predict-who-is-more-influential-in-a-social-network/data
- Million Song Dataset – набор звуковых фич и метаданных для миллиона современных музыкальных треков от Echo Nest. http://millionsongdataset.com/
- Free Music Archive ( FMA) – набор легальных аудиозаписей для задач анализа музыки — просмотр, поиск и организация коллекций. Архив содержит 917 ГиБ и 343 дня аудио под лицензией Creative Commons из 1 06 574 треков от 16 341 исполнителя и 14 854 альбомов по 161 жанру. FMA предоставляет полноразмерный высококачественный звук, предварительно вычисленные фичи, а также метаданные трека и пользователя, теги и произвольный текст, например, биографии исполнителей. https://github.com/mdeff/fma
- Steam Video Games — набор данных о действиях пользователей и их характеристиках от самого популярного хаба видеоигр, PC Gaming Steam https://www.kaggle.com/tamber/steam-video-games/data
- Ta-Feng – набор данных о покупках от ACM RecSys по 23+ тысяч товаров, от продуктов питания и канцелярских товаров до мебели. Датасет включает данные о более 800 тысячах транзакций 32+ тысяч пользователей за 4 месяца, с ноября 2000 г. по февраль 2001 г. http://www.bigdatalab.ac.cn/benchmark/bm/dd?data=Ta-Feng
- Beiren – данные о реальных покупках более миллиона человек в супермаркетах Китая за период с 2012 по 2013 год. Датасет содержит сведения о 49 290 149 транзакций по 220 828 товарам. http://www.bigdatalab.ac.cn/benchmark/bm/dd?data=Beiren
- MQ — набор датасетов для обучения ранжированию. Данные обучения состоят из списков элементов с некоторым частичным порядком, указанным между элементами в каждом списке. Этот порядок обычно создается путем выставления числовой или порядковой оценки или бинарного суждения (например, «релевантный» или «нерелевантный») для каждого пункта. http://www.bigdatalab.ac.cn/benchmark/bm/Domain?domain=Learning%20to%20Rank
- Jester — Анонимные данные о рейтингах шуток (анекдотов) из системы Jester. https://goldberg.berkeley.edu/jester-data/
- REKKO CHALLENGE – набор данных от онлайн-кинотеатра OKKO для конкурса по разработке рекомендательных систем 2019 года. Сюда входит несколько CSV-датасетов по транзакциям, пользовательским оценкам и отметкам, а также JSON-файлы с метаданными о фильмах и пользователях. https://boosters.pro/championship/rekko_challenge/data
Резюме
Как правило, модели машинного обучения строятся на ноутбуках Jupyter с кодом, который выглядит, мягко говоря, плохо — длинные листы с лапшой выражений и отрывистыми вызовами функций. Очевидно, что поддерживать такой код практически невозможно, поэтому каждый проект приходится писать практически с нуля. И вы даже не можете подумать о том, чтобы внедрить этот код в производство.
Поэтому сегодня мы представляем предварительный обзор библиотеки Python для работы с наборами данных и моделями науки о данных. С его помощью вы можете сделать свой Python-код похожим на этот:
Атрибуты датасета
В этой статье вы узнаете о самых важных классах и методах, которые помогут вам сделать ваш код простым, понятным и удобным для пользователя.
Специальные методы датасетов
Библиотека все еще находится на стадии разработки и еще не стала общедоступной. Эта статья — не полная документация, а лишь краткое описание библиотеки и примеры ее использования. Ваши отзывы помогут улучшить библиотеку и включить в нее нужные вам функции.
Основная цель набора данных — создание лотов.
Или вы можете вызвать генератор:
Партии могут собираться строго последовательно или хаотично, повторяться бесконечно или проходить ровно один цикл в ваших данных. Вы даже можете создавать партии разных размеров на каждом этапе, если это имеет смысл в вашем случае.
Помимо итерации, Dataset имеет еще одну полезную функцию — cv_split, которая разделяет набор данных на train, test и validation, каждая из которых удобно остается набором данных.