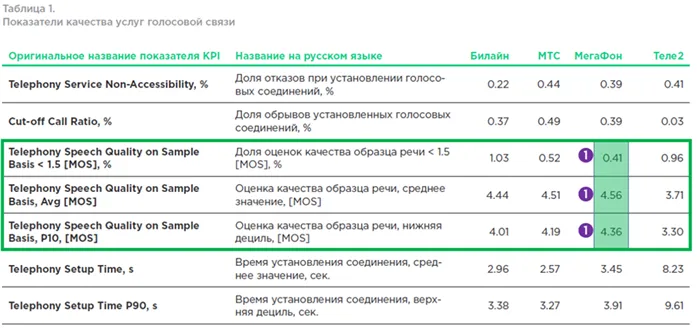
Настройки на вкладке «Выход» завершены. Теперь нажмите на пункт меню «Звук» из левого списка. Установите частоту дискретизации в соответствии с частотой вашего микрофона (по умолчанию 44,1 кГц). Если вы используете второе устройство, выберите его в соответствующем поле (если нет, оставьте настройку отключенной).
Какую частоту дискретизации выбрать в настройках компьютера
Sampling rate (или sample rate ) — частота дискретизации сигнала непрерывного времени при выборке (особенно из аналого-цифрового преобразователя). Частота дискретизации измеряется в герцах.
Этот термин также используется для обратного преобразования из цифрового формата в аналоговый, особенно когда частота дискретизации прямого и обратного преобразования различна (этот метод, также известный как «временное масштабирование», используется, например, при анализе очень низкочастотных звуков, издаваемых морскими животными).
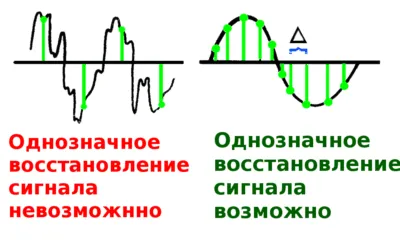
Чем выше частота дискретизации, тем шире спектр сигнала, который может быть представлен в виде дискретного сигнала. Как гласит теорема Котельникова, для однозначного восстановления исходного сигнала частота дискретизации должна быть больше, чем в два раза выше самой высокой частоты в спектре сигнала.
Некоторые из используемых частот дискретизации аудио: 1 :
- 8 000 Гц — телефон, достаточно для речи, кодек Nellymoser;
- 11 025 Гц — четверть Audio CD, достаточно для передачи речи;
- 16 000 Гц;
- 22 050 Гц — половина Audio CD, достаточно для передачи качества радио;
- 32 000 Гц;
- 44 100 Гц — используется в Audio CD. Выбрано Sony из соображений совместимости со стандартом PAL, за счёт записи 3 значений на линию картинки кадра × 588 линий на кадр × 25 кадров в секунду, и достаточности (по теореме Котельникова) для качественного покрытия всего диапазона частот, различаемых человеком на слух (20 Гц — 20 КГц);
- 48 000 Гц — DVD, DAT;
- 96 000 Гц — DVD-Audio (MLP 5.1);
- 192 000 Гц — DVD-Audio (MLP 2.0);
- 2 822 400 Гц — SACD, процесс однобитной дельта-сигма модуляции, известный как DSD — Direct Stream Digital, совместно разработан компаниями Sony и Philips;
- 5 644 800 Гц — DSD с удвоенной частотой дискретизации, однобитный Direct Stream Digital с частотой дискретизации вдвое больше, чем у SACD. Используется в некоторых профессиональных устройствах записи DSD.
Частота дискретизации
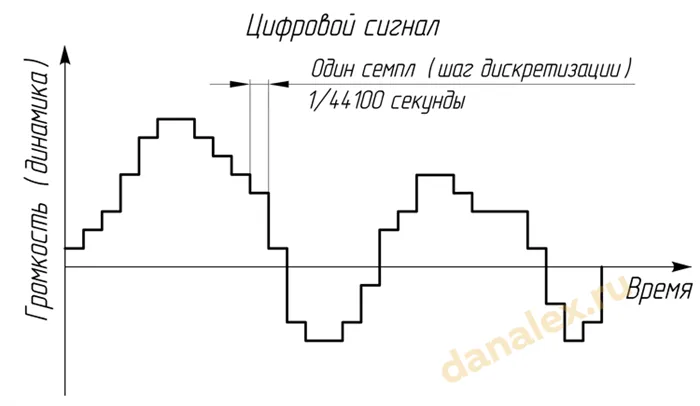
Горизонтальное деление осциллограммы дает информацию о частоте дискретизации или частоте опроса. Чем чаще АЦП обнаруживает изменения в форме сигнала, тем выше частота дискретизации. Сэмпл — это дискретная единица, наименьшая единица звука. Чем он меньше, тем выше частота дискретизации.
Например, частота дискретизации 44,1 кГц означает, что одна секунда записи содержит 44100 выборок. Мы можем обработать форму волны, используя 1/44100 секунды в качестве минимального элемента обработки. Если мы увеличим частоту дискретизации до 48 кГц, это значение уменьшится до 1/48000 секунды, что дает более точный эффект.
Частота дискретизации
Горизонтальное деление осциллограммы дает информацию о частоте дискретизации или частоте опроса. Чем чаще АЦП обнаруживает изменения в форме сигнала, тем выше частота дискретизации. Сэмпл — это дискретная единица, наименьшая единица звука. Чем он меньше, тем выше частота дискретизации.
Например, частота дискретизации 44,1 кГц означает, что одна секунда записи содержит 44100 выборок. Мы можем обработать форму волны, используя 1/44100 секунды в качестве минимального элемента обработки. Если мы увеличим частоту дискретизации до 48 кГц, это значение уменьшится до 1/48000 секунды, что дает более точный эффект.
спектрограммы:
Спектрограмма — это спектрально-временное представление звука. Горизонтальное направление спектрограммы представляет собой время, а вертикальное — частоту. (1) Спектрограммы можно использовать для отображения изменений частотного содержания нестабильного сигнала с течением времени.
Формула для спектрограммы (2) приведена ниже:
Я взял код из следующего
#, чтобы избежать высоких динамических диапазонов, вызванных сингулярностью в нуле.
log_magnitude_spectrograms = tf.log(magnitude_spectrograms + log_offset)
return log_magnitude_spectrograms
Затем создайте log_spectrogram данных образца: bed.
log_spe_bed = log_spectrogram(train.file0,train.label0).numpy()
array_bed = log_spe_bed.astype(np.float)0
fig = plt.figure(figsize=(14,8))
#plt.ylabel("Частоты в Гц")
plt.xlabel("Log_Spectrogram")
plt.imshow(np.swapaxes(array_bed,0,1).T)
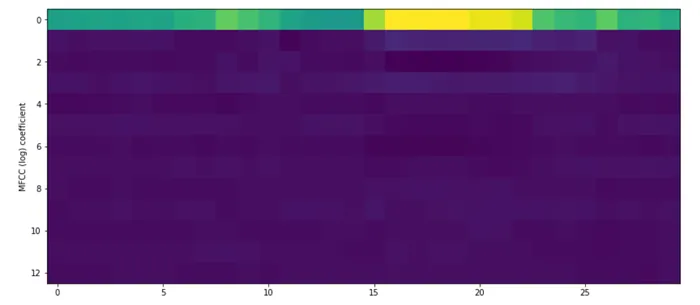
Функция MFCC (Frequency Cepstral Coefficient) — это функция, широко используемая в автоматическом распознавании речи и языка. Шкала Мел соотносит воспринимаемую частоту или высоту чистого тона с фактически измеренной частотой. Люди гораздо лучше различают небольшие изменения высоты тона на низких частотах, чем на высоких. Благодаря включению этой шкалы наши характеристики становятся более похожими на то, что слышит человек. (3)
def mfcc(file=train'file'.tolist(), label=train'label'.tolist())
sample_rate, samples = wavfile.read(str(train_audio_path) + ' \'+label+' \\\\ ' + file)
if len(samples)
samples = np.pad(samples, (0,16000-len(samples)), 'linear_ramp')
еще
образцы = образцы:16000
Коэффициент частоты Мела (MFCC):
сигналы = tf.cast(tf.reshape(samples, 1,-1 ),tf.float32)
спектрограмма = signal.stft(signals, frame_length=1024, frame_step= 512)
log_magnitude_spectrograms = tf.log(magnitude_spectrograms + log_offset)
num_spectrogram_bins = magnitude_spectrograms.shape-1.value<16000:
нижний_край_герц, верхний_край_герц, num_mel_bins = 80.0, 7600.0, 64
linear_to_mel_weight_matrix = tf.contrib.signal.linear_to_mel_weight_matrix(num_mel_bins, num_spectrogram_bins, sample_rate, lower_edge_hertz,upper_edge_hertz)
mel_spectrograms = tf.tensordot(magnitude_spectrograms, linear_to_mel_weight_matrix, 1)
return log_magnitude_spectrograms
Затем создайте log_spectrogram данных образца: bed.
log_spe_bed = log_spectrogram(train.file0,train.label0).numpy()
log_offset = 1e-6
log_mel_spectrograms = tf.log(mel_spectrograms + log_offset)
num_mfccs = 13
# Сохраняем первые MFCC 'num_mfccs'.
mfccs = tf.contrib.signal.mfccs_from_log_mel_spectrograms(log_mel_spectrograms). :num_mfccsreturn mfccs.numpy()0С помощью функции "mfcc", определенной выше, легко вычислить mfcc аудиофайла "bed" и представить его MFCC.
array_bed = log_spe_bed.astype(np.float)0
fig = plt.figure(figsize=(14,8))
plt.ylabel("Коэффициент MFCC (log)")
plt.imshow(np.swapaxes(mfcc_bed,0,1))
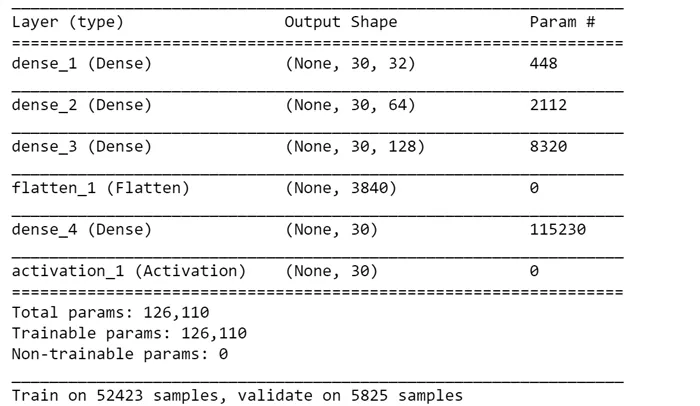
Я создал модель последовательной нейронной сети, которая является самым простым способом создания модели в Keras - она указывает Keras на последовательную укладку всех слоев. Затем я добавил четыре плотных слоя, которые полностью соединены в модели.
После построения модели я использовал адаптивную оценку моментов в качестве оптимизатора, категориальную перекрестную энтропию в качестве потери и точность в качестве метрики для синтеза модели.
# Dense(64) — это полностью подключенный слой с 64 скрытыми единицами.
# В первом слое вы должны использовать exp
if len(samples)
#Adam, алгоритм градиентной оптимизации стохастических объективных функций первого порядка, основанный на адаптивных оценках моментов нижнего порядка.
model.summary()
Моделирование данных:
#history = model.fit(x=X_train_array, y=y_train_array, epochs=5, verbose=1, validation_split=0.33, shuffle=True, class_weight=get_class_weights(pd.Series((list(set(labels)))),dtype=’category’).cat.codes.values),batch_size=batch_size))
history = model.fit(x=X_train_array, y=y_train_array, epochs=25, verbose=1, validation_split = 0.1, shuffle= True, class_weight=get_class_weights(pd.Series(Y_train,dtype=’category’).cat.codes.values),batch_size=128)
model_evaluation = model.evaluate(x=X_test_array, y=y_test_array, batch_size= None, verbose=1)
prediction = model.predict(X_test_array, batch_size = 128, verbose = 1)
april_tst = model.predict(mfcc_april_test, batch_size = 128, verbose = 1)
sess0.close()
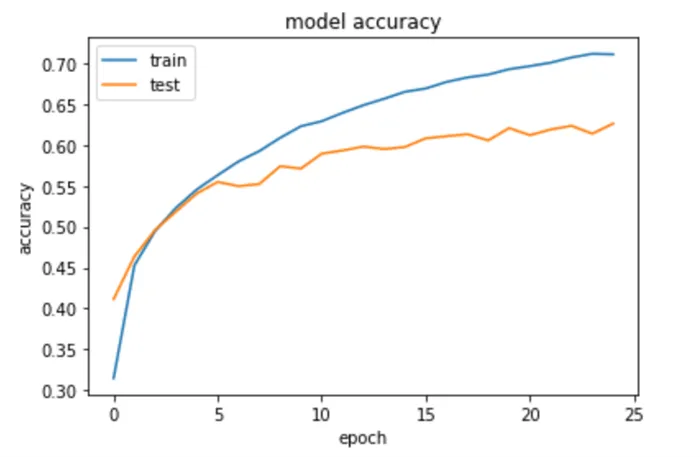
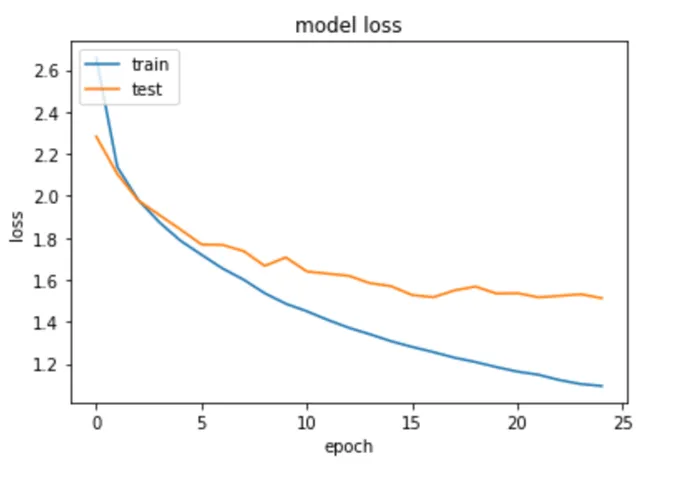
Я выбрал 25 в качестве количества сезонов, т.е. сколько раз модель будет проходить через данные. После примерно 20 эпох точность верификации модели повышается до 61% - 62%.
Как видно из двух рисунков выше, точность тестирования и обучения недостаточно близки, что означает, что эта модель может быть улучшена путем преодоления проблем переподгонки.
Товарищ Котельников заложил основы теории цифровой техники еще в 1933 году в своей работе "О пропускной способности эфира и провода в электросвязи", которую обычно формулируют следующим образом:
Любой непрерывный сигнал u(t) с конечным спектром (с максимальным значением частоты F ) может быть представлен в терминах дискретных выборок u(k D t), частота дискретизации которых должна быть выбрана так, чтобы быть по крайней мере вдвое больше максимального значения спектра сигнала: f ≥ 2F, для того, чтобы его можно было передать по линии связи и затем вернуться к исходному аналоговому сигналу.
Проще говоря, чтобы правильно воспроизвести (реконструировать) аналоговый сигнал из цифровой формы, достаточно, чтобы частота дискретизации была вдвое больше максимальной частоты сигнала.
Верхний предел человеческого слуха обычно составляет 20 кГц. Согласно теореме Котельникова, частоты дискретизации 40 кГц достаточно для правильного воспроизведения сигнала 20 кГц. Если вы посмотрите на характеристики большинства аудиофайлов, вы увидите линию:
Почему 44,1 кГц? Википедия отвечает: "Это число было выбрано Sony для обеспечения совместимости со стандартом передачи PAL, который требует записи 3 значений на строку кадра x 588 строк на кадр x 25 кадров в секунду, а также для обеспечения (согласно теореме Котельникова) достаточной надежности для покрытия всего диапазона акустических частот (от 20 Гц до 20 кГц).
С частотой дискретизации 44,1 кГц, абта
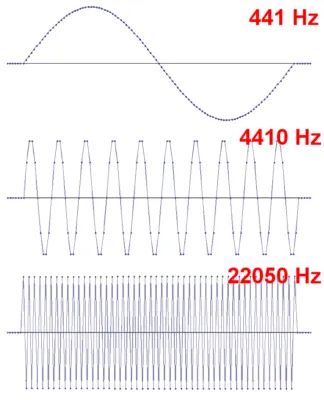
Однако при 22050, самой высокой частоте, удовлетворяющей теореме Котельникова (при частоте дискретизации 44,1 кГц), на 100 точек приходится 50 периодов колебаний.
Эти сигналы были созданы с помощью программы Audacity. Сначала у меня сложилось впечатление, что точек несколько, но разобрать масштаб просто невозможно, поэтому все так неудобно.....
Читайте также:
Простой способ создания сигналов различной формы в аудиоредакторе Audacity
Поэтому давайте увеличим масштаб и рассмотрим каждый период в отдельности:
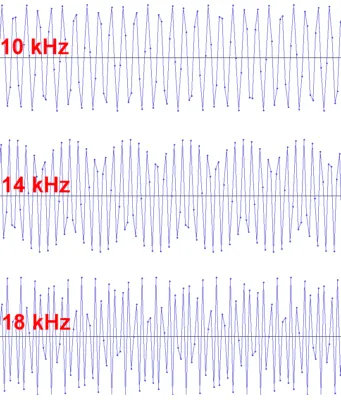
Частота 4410 Гц - это приличная синусоида, но вы ничего не можете сказать о 22050 Гц с двумя точками на период. На самом деле, это даже не синусоидальная волна, а треугольный сигнал.
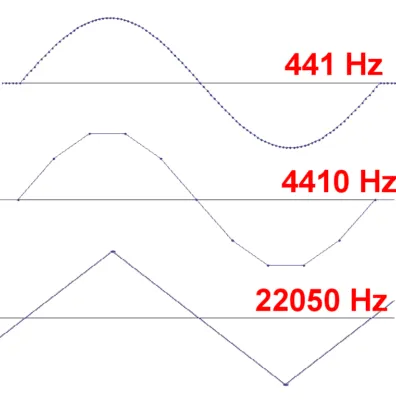
Конечно, в любом настоящем ЦАПе выход оснащен фильтром низких частот, который вырезает высокочастотную составляющую и округляет треугольник. Однако чем выше класс аудиоустройства, тем более выраженной становится угловатость.
В целях экспериментов Audcity позволяет создавать сигналы с одинаковой частотой, но разной формы: треугольная и прямоугольная форма волны создает дополнительные гармоники благодаря своей угловатости и острым краям, в то время как синусоидальная волна создает более мягкий, естественный звук.
Но даже это не самое худшее. До этого момента изучались сигналы с частотами, кратными частоте дискретизации.
Получите цифровую синусоиду с той же амплитудой и частотой 15 кГц. Красивый узор, не правда ли? Как вы видите, амплитуда меняется с частотой. Это уже модуляционное искажение. Наш текущий сигнал 15 кГц модулируется на частоте, кратной 44,1 кГц.
Вы можете возразить, что узор красив, но, вероятно, он звучит так, как должен звучать. Чтобы увидеть это своими ушами, создайте сигнал, частота которого изменяется от 20 герц до 20 кГц. И вы ясно услышите, что в определенный момент частота не повышается равномерно, а начинает колебаться туда-сюда.
А вот так выглядят синусоидальные кривые на разных частотах выше 10’000 Гц.
Какая частота дискретизации считается достаточной?
В защиту теоремы Котельникова следует отметить, что, хотя его теорема верна, поскольку в противном случае мы не смогли бы различать высокие ноты в музыке, а тарелки или маракасы звучали бы столь же неправдоподобно, она не обязательно гарантирует высокое качество записи.
Вряд ли вам понравится звук синусоиды в реальной жизни, но это был очень наглядный пример проблем качества цифровых записей.
Но это только предположение. Я не видел ни одного оборудования, которое не поддерживало бы 48 кГц или не рекомендовало бы его по каким-то причинам. Конечно, до написания игры для Playstation мне еще далековато, но это не так важно. Главное, что я обнаружил, что 48 кГц — это то, что нужно. Также помните, что старикам не очень важны ваши объективы. Акустическая улитка постепенно умирает с возрастом, начиная с верхнего конца, и диапазон теряется.
Когда сигнал от предусилителя, компрессора, выхода микшера или синтезатора поступает на A/D-конвертер, он представляет собой электромагнитное колебание. Это означает, что на вход АЦП поступает волна с флуктуирующим напряжением очень малой величины. Результатом является графическое представление волны на экране компьютера. Даже самый лучший преобразователь имеет погрешность, потому что нет промежуточных значений между нулем и единицей, а волновая кривая состоит только из вертикальных и горизонтальных сегментов, без наклонных линий. На кривую формы волны влияют высота тона, тембр, форма волны и амплитуда интенсивности звука. Качественный АЦП должен правильно передавать все эти параметры в систему записи. Поэтому звук поступает в систему дискретно, т.е. разделенным на небольшие сегменты. Точность кодирования аналогового сигнала в цифровой среде зависит от размера этих сегментов.
В нашем понимании звука есть две крайности — механический звук и музыкальный звук. Первый говорит «440 Гц!», второй — «нота Ля!». Оба варианта верны. Первый говорит «частота», второй — «шаг». Однако есть много прекрасных музыкантов, которые вообще не знают нот. В то же время, вы никогда не встречали специалиста по акустике, который не знал бы основных физических элементов в этой области.
Читайте также: Обзор Hi-Fi трио COWON: Plenue D/J/V
Вроде все нормально, так чего же тут не так?
Важно понимать, что эти два эксперта по-своему относятся к приятным звукам. Создатель музыкального произведения строит звук либо инстинктивно, либо на основе консервативных знаний в соответствии с принципами гармонии, избегая диссонансов и искажений. Дизайнер, создающий акустическую систему, прежде всего, не допускает посторонних шумов, минимизирует искажения, уделяет внимание равномерности амплитудно-частотной характеристики, динамике и многому другому.
Несколько слов о синтезе, работе и оптимизации цифровой аудиосхемы с использованием компьютера и USB. Во-первых, тема скучная и много букв, так что если вам трудно это переварить, пропустите выводы. Звуковой сигнал обычно кодируется последовательностью значений амплитуды сигнала, измеряемых через равные промежутки времени.
Не только для новичков, но и для многих аудиолюбителей со стажем является откровением узнать, что тривиальный процесс записи сопровождается очень сложными физическими явлениями. Одним из них является отбор проб. По определению, это преобразование непрерывной функции в дискретную. Это трудно понять человеку, не знакомому с наукой, особенно потому, что это связано с квантовой физикой, самой передовой физикой на сегодняшний день. Но профессиональные звукорежиссеры, работающие, например, в московской студии «Интервал», знают, что такое частота дискретизации и какая из них лучше всего подходит для определенных ситуаций. Почему? Потому что от этого явления зависит конечное качество записанной музыки. В эпоху кассет эти нюансы были опущены из-за ограниченного технического оснащения. Но в современном высокотехнологичном цифровом мире частота дискретизации имеет большое значение, когда речь идет о создании музыки и ее представлении слушателю.
Представляем вашему вниманию МегаФон и нашу серию статей о том, как меняется качество голоса в мобильных сетях по мере развития новых технологий.
Давайте начнем с небольшой истории. С момента изобретения телефона и до конца 20-го века речь в основном передавалась по проводам в виде электрических сигналов. С кабелями все было довольно просто: звук был аналоговым, то есть не оцифрованным, и его качество определялось длиной и состоянием медной проволоки. Однако, поскольку проводные системы было сложно масштабировать, оцифровка открыла эру кодирования и сжатия речи. Кодирование речи возникло в результате использования импульсно-кодовой модуляции (PCM). ECM — это процесс, преобразующий аналоговые аудиоданные в цифровой поток. Для того чтобы речь была разборчивой, достаточно, чтобы аналоговый звук находился в диапазоне 0,3-3,4 кГц, что, согласно теореме Котельникова (Найквиста-Шеннона), позволяет преобразовать его в цифровой со скоростью передачи 64 кбит/с.
Кстати, кодек PCM-64 G.711 (PCM) до сих пор широко используется в телефонных сетях. Почему?
Этот кодек имеет множество преимуществ:
Но IRM-64 также имеет некоторые недостатки:
Давайте вернемся к сетям мобильной связи и рассмотрим подробнее голосовые кодеки.
Вышеупомянутая скорость 64 кбит/с является чрезвычайно высокой для передачи данных в мобильных сетях. Поэтому использование такого потока значительно снизит пропускную способность сети. Чем выше скорость, тем сложнее довести ее до края соты (сота — наименьшая единица покрытия сотовой связи). Следовательно, радиус действия базовой станции значительно уменьшается. По этой причине сжатие применяется к радиоинтерфейсу. История развития «мобильных» кодеков заслуживает отдельной статьи, скажу лишь, что наиболее популярными кодеками в современных сетях являются AMR, WB-AMR, EVS.
— А что же будет, если взять другие частоты.
Базовый кодер в мобильной сети. Кодер преобразует речь в диапазоне 0,3-3,4 кГц в цифровой поток данных от 4,75 до 12,2 кбит/с. Он является адаптивным (скорость передачи данных кодера выбирается в зависимости от условий радиоканала). Частота дискретизации: 8 кГц. Применим для сетей GSM, UMTS и VoLTE.
Базовый кодер в мобильной радиосети. Частота дискретизации: 16 кГц.
В мобильных сетях он используется в двух конфигурациях:
В России, кстати, «МегаФон» первым внедрил кодек 23,85 кбит/с в сети UMTS в большинстве регионов России, чтобы обеспечить высокое качество голоса для абонентов без поддержки VoLTE.
Для оценки качества голоса используется такая функция, как MOS (Mean Opinion Score) — как следует из названия, это субъективная средняя оценка качества по 5-балльной шкале.
Цифровой аудиотракт: апсемплинг и апскейлинг, WASAPI, ASIO и внешний мастер клок для USB-аудио
Что это такое? Представим себе большой конференц-зал, где мы собираем большую группу людей разного пола и возраста и просим их послушать сначала первое выступление двух человек, а затем такое же выступление одного человека.
Значит, чтобы выучить МОП, операторы постоянно собирают людей для прослушивания?
Нота — высота звука и его частота — зависит от специальности
Нет, конечно, нет. Исследования человеческого восприятия звуковых искажений позволили разработать довольно точные математические модели того, как люди будут оценивать звук, если мы проведем тест на большой выборке. Наиболее распространенными алгоритмами для оценки MOS являются PESQ и POLQA. Эти алгоритмы анализируют тип искажения (что важно, поскольку некоторые искажения едва воспринимаются ухом, а другие сразу «режут» ухо), взвешивают их влияние и рассчитывают итоговый балл MOS.

Сегодня анализ качества голоса оператора выглядит следующим образом: Два тестовых телефона звонят друг другу и воспроизводят знакомый человеческий диалог. Затем специальное программное обеспечение сравнивает образец с оригиналом, определяет тип помех и использует алгоритм POLQA (или PESQ) для оценки среднего балла, который дал бы человек.
МегаФон» регулярно измеряет качество голоса в собственной сети и сетях конкурентов, чтобы оставаться впереди по качеству голоса в каждом населенном пункте.
Пишу МП3 диск, какая частота выгоднее 44,1 или 48?
Для этого мы используем как дорожные тесты с измерительными приборами, так и передовые системы CEM (Customer Experience Management), которые позволяют нам удаленно контролировать качество голоса при каждом звонке и определять, где качество «зависает».
Если это интересно, то в следующем цикле я подробно расскажу, как осуществляется мониторинг качества обслуживания в компании «МегаФон».
Голос в мобильных сетях. От чего зависит качество?
Кстати, ходят слухи, что HD Voice работает только для звонков внутри сети МегаФона, а старый добрый G.711 работает между операторами.
Что касается Москвы, то по качеству передачи голоса (MOS) Мегафон не имеет себе равных. Это подтверждают как регулярные внутренние тесты трафика, так и независимые сравнения. Например, исследование, проведенное компанией DMTel:
Надеюсь, вам было интересно!
О каких еще мобильных технологиях вы хотели бы узнать? Пишите в комментариях.
- Простое математическое кодирование, не требует высокой производительности со стороны DSP VoCoder-ов.
- Нет потери качества при кодировании/декодировании.
Валентин Кузьмин
- Кодек ограничен полосой речи в 0.3-3.4 кГц, что отсекает, приятную уху, окраску речи высокими гармониками.
- Скорость передачи данных в 64 кбит/с занимает очень много ресурсов мобильной сети (в проводных сетях такой проблемы, как правило, нет, поэтому G.711, до сих пор крайне популярен в проводной VoIP-телефонии).
- Отсутствует адаптация битейта кодека к потерям в передаче данных.
Ведущий эксперт по сквозной оптимизации в компании «МегаФон
AMR
WB-AMR (wide-band AMR)
- Поток от 6.6 до 12.65 кБит/с передаёт голос в полосе 0.1-6.4 кГц Используется в сетях GSM, UMTS, VoLTE.
- Поток от 6.6 до 23.85 кБит/с передаёт голос в полосе 0.1-7.0 кГц Является «базовым» кодеком в сетях VoLTE, опционально может применяться в сетях UMTS.
Как же операторы измеряют качество речи?

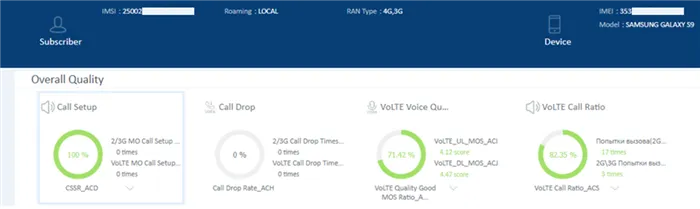
Подытожить тему качества речи хочется некоторыми исследованиями