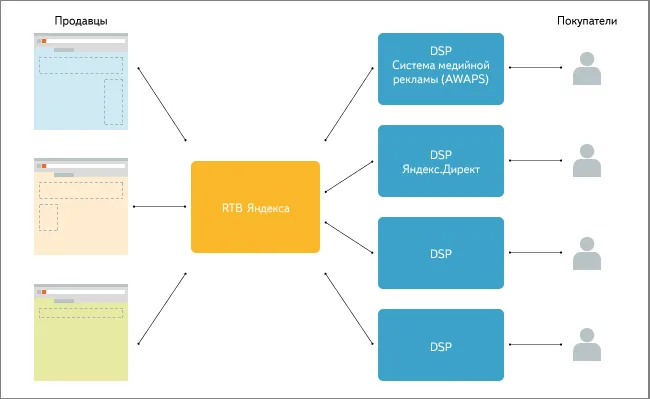
В ближайшем будущем большие данные станут важным инструментом принятия решений — от онлайн-бизнеса до целых стран и международных организаций15.
Big Data от А до Я. Часть 1: Принципы работы с большими данными, парадигма MapReduce

Привет, Хабр! Эта статья открывает серию статей о манипулировании большими данными. Зачем; Я и моя команда хотим сохранить накопленный нами опыт в виде энциклопедии. Это определенно будет кому-то полезно.
Она объясняет проблему больших данных с разных точек зрения. Основные принципы работы с данными, инструменты и примеры решения реальных задач. Особое внимание уделяется теме машинного обучения.
Поскольку нам нужно начинать от простого к сложному, в первой статье описаны принципы работы с большими данными и примеры MapReduce.
Исходя из определения больших данных, можно сформулировать основные принципы работы, используя следующие данные
1. горизонтальная масштабируемость. Поскольку данные могут быть произвольными, любая система, управляющая большими данными, должна быть масштабируемой. Объем данных удвоился. Количество оборудования в кластере удвоилось, и все продолжало функционировать.
2) Допустимость ошибок. Принцип горизонтальной масштабируемости означает, что в кластере может быть большое количество машин. Например, кластер Hadoop компании Yahoo насчитывает более 42 000 машин (см. размеры кластеров различных организаций по этой ссылке). Это означает, что некоторые из этих машин гарантированно выйдут из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и проходить их без существенных последствий.
3. местоположение данных. В больших распределенных системах данные распределены по многим машинам. Если данные, естественно, находятся на одном сервере, а обрабатываются на другом, стоимость передачи данных может превысить стоимость самой обработки. Именно поэтому одним из важнейших принципов проектирования решений для больших данных является принцип локальности данных. По возможности обрабатывайте данные на той же машине, где они хранятся.
Все современные инструменты работы с большими данными в той или иной мере следуют этим трем принципам. Чтобы следовать им, нам необходимо придумать некоторые методы, приемы и примеры для разработки инструментов интеллектуального анализа данных. Один из самых классических методов мы анализируем в сегодняшней статье.
MapReduce
О MapReduce уже писали (раз, два, три раза), но коль скоро эта серия статей направлена на систематическое изложение больших данных, она не может обойтись без MapReduce в первой статье J.
MapReduce — это модель распределенной обработки, предложенная компанией Google для обработки больших объемов данных в кластерах компьютеров. MapReduce очень хорошо иллюстрируется следующим изображением (по ссылке).
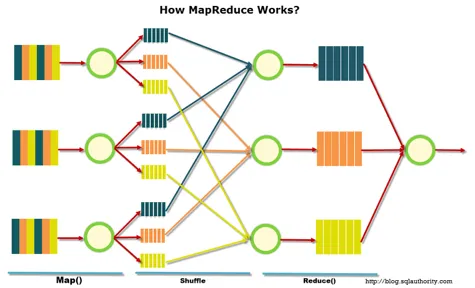
MapReduce предполагает, что данные организованы в виде нескольких записей. Обработка данных осуществляется в три этапа.
1. этап карты. На этом этапе данные предварительно обрабатываются с помощью определяемой пользователем функции map(). Функция этого этапа заключается в предварительной обработке и фильтрации данных. Эта функция очень похожа на функцию map в операционном языке программирования — определенная пользователем функция применяется к каждой входной записи.
Функция MAP () применяется к одной входной регистрации и извлекает набор пар значений. Набор — т.е. только одна запись, ничего или много пар значений — может быть извлечен. Пользователь сам решает, что входит в ключи и каковы цены, но ключи очень важны, поскольку данные с ключами в конечном итоге приведут к снижению будущей функциональности.
2. этап. Проходит незаметно для пользователя. На этом этапе на выходе «микс» функции карты — каждый микс соответствует ключу на выходе этапа карты. Кроме того, эти ведра выступают в качестве записей, которые необходимо сократить.
3. стадия сокращения. Каждой «корзине» со значением, сформированной на этапе смешивания, присваивается запись в функции redoce ().
Функция уменьшения определяется пользователем и вычисляет конечный результат отдельных «бинов». Набор всех значений, которые возвращает reduce (), является конечным результатом работы MapReduce.
Некоторые дополнительные элементы в MapReduce:.
1) Все функции карты выполняются независимо и могут выполняться параллельно на разных машинах в кластере параллельно.
2) Все функции редукции работают независимо и могут выполняться одновременно на разных машинах кластера.
(3) Shuffle представляет собой внутреннюю параллельную сортировку и может выполняться на разных машинах кластера. Пункты 1-3 позволяют реализовать принцип горизонтального расширения.
(4) Функция отображения обычно применяется на том же компьютере, где хранятся данные. Это обеспечивает передачу данных по всей сети (принцип передачи данных).
(5) MapReduce — это всегда полное сканирование данных, без индекса. Это означает, что MapReduce не полностью применим при очень быстрых ответах.
3. Предписывающий анализ — это следующий уровень по сравнению с прогнозирующим анализом. С помощью больших данных и современных технологий можно определить проблемные точки в бизнесе или другой деятельности и рассчитать, каких сценариев можно избежать в будущем.
Что такое Big Data
Большие данные — это огромный набор различных данных. Объем настолько огромен, что простой компьютер не в состоянии справиться с ним, поскольку данные изменяются в различных формах, неструктурированы и содержат ошибки. Большие данные можно быстро хранить и использовать для различных целей.
Большие данные, даже если они слишком велики, не являются обычной базой данных. Различия включают.
| Не большие данные | Большие данные |
|---|---|
| База записей о тысячах работников корпорации. Информация в такой базе имеет заранее известные характеристики и свойства, ее можно представить в виде таблицы, как в Excel. | Журнал действий сотрудников. Например, все данные, которые создает во время работы колл-центр, где работает 500 человек. |
| Информация об именах, возрасте и семейном положении всех 2,5 миллиардов пользователей Фейсбук* — это всего лишь очень большая база данных. | Переходы по ссылкам, отправленные и полученные сообщения, лайки и репосты, движения мыши или касания экранов смартфонов всех пользователей Фейсбук*. |
| Архив записей городских камер видеонаблюдения. | Данные системы видеофиксации нарушений правил дорожного движения с информацией о дорожной ситуации и номерах автомобилей нарушителей; информация о пассажирах метро, полученная с помощью системы распознавания лиц, и о том, кто из них числится в розыске. |
Объем информации в мире растет с каждой секундой, и то, что еще десять лет назад считалось бы большими данными, сегодня умещается на жестком диске домашнего компьютера.

Шестьдесят лет назад жесткий диск объемом 5 мегабайт был в два раза больше холодильника и весил около тонны. Сегодня жесткие диски всех компьютеров могут превышать полтерабайта (один терабайт равен одному миллиону мегабайт) и по размеру меньше обычной книги.
В 2021 году большие данные будут измеряться в петабайтах. Петабайт равен одному миллиону гигабайт. Трехчасовой фильм в формате 4K «весит» 60-90 гигабайт, весь YouTube — пять петабайт, или 67 000 таких фильмов. Миллион петабайт — это один зеттабайт.
Станьте специалистом по изучению данных и приручите большие данные. Узнайте, как выявлять закономерности в данных и создавать модели для решения бизнес-задач.
Сэкономьте 45% с промокодом для блога.
Как работает технология Big Data?
Большие источники данных делятся на три типа.
Все, что люди делают в Интернете, является источником огромного количества социальных данных. Каждую секунду пользователь загружает 1 000 фотографий в Instagram* и отправляет более 3 миллионов электронных писем. Личный вклад каждого человека в секунду составляет в среднем 1,7 мегабайта.
Другими примерами социальных источников больших данных являются статистика и города, данные о путешествиях, записи о смерти и рождении и медицинские карты.
Большие данные также генерируются машинами, датчиками и Интернетом вещей. Информация поступает от смартфонов, умных колонок, ламп, систем умного дома, улиц и метеорологических спутников.
Транзакционные данные получены из покупок, денежных переводов, поставок товаров и операций с банкоматами.
Как обрабатывают большие данные?
Большие таблицы данных настолько велики, что Simple Excel не может их обработать. По этой причине для их обработки используется специальное программное обеспечение.
Это называется «горизонтальной эскалацией», потому что она распределяет работу между многими компьютерами, которые обрабатывают информацию одновременно. Чем больше двигателей задействовано на рабочем месте, тем продуктивнее процесс.
Программное обеспечение основано на MapReduce, модели параллельных вычислений. Модель работает следующим образом.
- сначала данные фильтруются по условиям, которые задает исследователь, сортируются и распределяются между отдельными компьютерами (узлами);
- затем узлы параллельно рассчитывают свои блоки данных и передают результат вычислений на следующую итерацию.
MapReduce — это не конкретная программа, а алгоритм, который может быть использован для решения большинства крупномасштабных задач обработки данных.
Примеры программного обеспечения на основе Maprece:.
- Hadoop — набор программ с открытым исходным кодом для хранения файлов, планирования и совместной работы с данными. Система разработана так, чтобы при сбое на одном узле нагрузка сразу перераспределялась на другие, не прерывая вычисления.
- Apache Spark — набор библиотек, которые позволяют выполнять вычисления в оперативной памяти и многократно обращаться к результатам расчетов. Его применяют для решения широкого круга задач, от простой обработки и фильтрации данных до машинного обучения.
Специалисты по работе с крупными данными используют оба инструмента: Hadoop для создания инфраструктуры данных и Spark для обработки фактической информации о потоках.
Специалисты по анализу данных специализируются на анализе крупномасштабных данных. Они ищут закономерности, создают модели и используют их для прогнозирования будущих событий.
Например, специалисты по изучению больших данных могут использовать статистику снятия денег в банкоматах для разработки математических моделей прогнозирования наличности. Эта система сообщает инкассаторам, сколько денег они должны внести в конкретный банкомат.
Чтобы покорить эту профессию, необходимо понимание основ математического анализа и знание языков программирования, таких как Python и R, а также баз данных SQL.
Изучайте Python и SQL, познакомьтесь с механическим обучением и решите, на чем вы хотите специализироваться: машинное обучение, компьютерное зрение или обработка естественного языка. Получите скидку 5% с промокодом для блога.
Аналитик данных использует тот же набор инструментов, что и специалист по исследованию данных, но с разными целями. В его обязанности входит проведение описательного анализа, интерпретация и представление данных в удобоваримой форме. Он обрабатывает данные для получения результатов и составляет аналитические отчеты, статистику и прогнозы.
Другие специалисты также занимаются большими данными, которые не являются их основной сферой деятельности: они
- дизайнеры интерфейсов, анализирующие данные поведенческих исследований для создания пользовательских интерфейсов;
- NLP-инженеры, которые разрабатывают программы для чат-ботов и автоматизации колл-центров, анализируя естественный язык;
- маркетологи-аналитики, которые исследуют массив данных для выстраивания маркетинговой политики и персонализации рекламы;
- инженеры и программисты на предприятиях, занимающиеся обработкой данных.
Новые аналитики получают все необходимые инструменты и приобретают востребованную профессию за шесть месяцев.
Сэкономьте 45% с промокодом для блога.
Инженеры по обработке данных занимаются технической стороной дела и в первую очередь манипулируют информацией. Они организуют сбор, хранение и первичную обработку.
Инженеры по данным помогают исследователям, создавая программное обеспечение и алгоритмы для автоматизации. Без этих инструментов большие данные были бы бесполезны, поскольку их объемы невозможно обработать. Для этой профессии важны знания Python и SQL с такими фреймворками, как Spark и фреймворки.
Этот урок подходит для тех, кто имеет базовые знания Python. В течение двух месяцев вы освоите все основные этапы проектирования данных.
Скидка 45% с промокодом для блога.
Александр Кондрашкин рассказывает о других профессиях, которым нужны большие данные.
Востребованность больших данных и специалистов по ним
Спрос на большие данные растет: согласно исследованию 2020 года, даже при пессимистичном сценарии российский рынок больших данных увеличится с 45 млрд рублей до 65 млрд рублей к 2024 году, а если дела пойдут плохо, то до 200 млрд рублей.
Предприятия все больше полагаются на масштабную аналитику данных. В 2014 году дистрибьюторы ежегодно теряли от 9 до 1,8 млрд долларов США прибыли только потому, что не применяли технологии больших данных. Ее 3,5 миллиона машин оснащены датчиками, которые собирают информацию об их состоянии и износе основных комплектующих, улучшая управление затратами на техническое обслуживание.
Все, что люди делают в Интернете, является источником огромного количества социальных данных. Каждую секунду пользователь загружает 1 000 фотографий в Instagram* и отправляет более 3 миллионов электронных писем. Личный вклад каждого человека в секунду составляет в среднем 1,7 мегабайта.
История возникновения
Мы работаем с большими данными. И количество информации, которую мы получаем, растет экспоненциально. То, что еще несколько десятилетий назад казалось масштабным, сегодня катастрофично.
Большие «назначения» впервые появились в 1970-х годах. Впоследствии были созданы центры обработки информации. К 2005 году, по мере развития технологий, компании начали понимать масштабы контента пользователей интернет-услуг (например, YouTube, VK, Facebook).
В то же время были созданы первые платформы для управления большим количеством контента по мере роста объема поступающих материалов. Его звали Хадооп. Сегодня это технический стек для обработки информации. Позже стал популярен своего рода NOSQL. Это набор методов для создания систем управления BigData.
Свойства
BigData — это технология обработки тысяч терабайт материала в электронном виде. Со временем их количество резко возрастает. Сюда входят петабайты и примеры.
Большие наборы данных обладают различными свойствами. Они также называются свойствами:.
- Скорость. Рассматриваемые «даты» обрабатываются и могут быть собраны из самых разных источников. Скорость получения информации невероятно высокая. Если данной особенности нет, к Биг Data сведения из интернета и других источников не будут иметь никакого отношения. Также стоит запомнить – упомянутые «объекты» генерируются постоянно.
- Объем. Анализ данных проводится не только быстро, но и массово. Из называния рассматриваемого понятия становится ясно – соответствующие материалы несут много информации. Без своего огромного размера BigData не являлись бы таковыми.
- Многообразие. Перечисленные характеристики немыслимы без разнообразия. Биг Data несут в себе сведения, относящиеся к совершенно разным типам. Главное отличие оные – наличие структурированных сведений. Такие могут сохраняться в базах данных сразу же.
На основе этих трех характеристик можно выделить соответствующие «компоненты ИТ». В последние годы реальный спрос на большие объемы электронного контента резко возрос. Это привело к появлению ряда новых свойств.
Первый определяется каждой отдельной компанией самостоятельно. Необходимо оценить, может ли материал принести пользу бизнесу. Надежность говорит сама за себя. Речь идет о том, чтобы понять, являются ли BigData в целом честными и надежными. Более того, неточность наносит ущерб организации и ее деятельности. И неважно, идет ли речь о крупной или небольшой компании — факт в том, что BigData — это инструмент, который может быть использован любым бизнесом.
Как происходит работа
В любом конкретном бизнесе большие данные обрабатываются в соответствии с установленными поведенческими моделями. Это необходимо для формирования новых бизнес-подходов и предотвращения путаницы. Генерируется в три этапа:.
Каждый «шаг» имеет свои оттенки и идиосинкразии, которые аналитик знает, как предоставить бизнесу качественную услугу.
Интегрирование
Это начало системы. В компании внедрен целый ряд информационных технологий (искусственный интеллект, суперкомпьютеры и т.д.) и специальных систем, способных собирать большие объемы информации из всевозможных источников.
Интеграция включает инструменты для редактирования и форматирования электронных материалов. Это необходимо для дальнейшего упрощения использования «даты».
Управление
Вопросы о том, где хранятся большие данные, предопределены заранее. Их результат зависит от различных критериев. Основными из них являются предпочтения в форме и технологии обработки.
Чтобы избежать проблем в будущем, существует алгоритм создания «хранилища» для больших данных. Это включает использование местных складских помещений для реализации данного проекта. Предприятия также могут сотрудничать с частными и общедоступными облачными службами. Такой подход позволяет экономить ресурсы и экономить без ущерба.
Анализ
Эти «хранилища» полезны сразу после проведения так называемого анализа. Это последнее звено в сотрудничестве. Для выполнения каждого задания используются различные методы работы. Примерами могут служить машинное обучение и генетические алгоритмы. В результате устраняется «ненужная» информация. Для клиентов и сотрудников остается только самая важная, качественная и полезная информация.