Как и в случае с несколькими синтезаторами, классификаторы обучаются на реальных данных и тестируются на сгенерированных данных. Таким образом, они достигли точности распознавания 87,6 %.
Какая предобработка текста нужна для генерации речи
NLP (Natural Language Processing) — это область машинного обучения, которая занимается распознаванием, генерацией и обработкой устной и письменной человеческой речи. Она находится на стыке дисциплин искусственного интеллекта и лингвистики.
Инженеры-программисты разрабатывают механизмы, позволяющие компьютерам и людям взаимодействовать с помощью естественного языка. С помощью НЛП компьютеры могут читать, интерпретировать, понимать и генерировать ответы на человеческую речь. Обычно обработка основана на уровне интеллекта машины, которая декодирует человеческие сообщения в информацию, имеющую для нее смысл.
Процесс машинного понимания с использованием алгоритмов обработки естественного языка может выглядеть следующим образом:
- Человеческая речь записывается аудиоустройством.
- Машина преобразует слова из аудиозаписи в письменный текст.
- Система NLP анализирует текст и понимает контекст разговора и цели человека.
- На основе результатов НЛП машина определяет команду, которую необходимо выполнить.
Кто использует NLP
Приложения НЛП окружают нас повсюду. К ним относятся поиск Google или Yandex, машинный перевод, чат-боты, виртуальные помощники, такие как Siri, Алиса, Сбер «Салют» и другие. НЛП используется в цифровой рекламе, безопасности и многом другом.
Технологии НЛП используются не только в науке, но и в коммерческих целях, например, для исследований и разработок в области искусственного интеллекта, а также при создании интеллектуальных систем, использующих естественный человеческий язык, от поисковых систем до музыкальных приложений.
Как устроена обработка языков
В прошлом алгоритмы выдавали набор ответов на определенные слова и фразы, и сравнение использовалось для поиска. Речь шла не о распознавании и понимании текста, а о реагировании на набранную строку символов. Такой алгоритм не сможет отличить ложку супа от школьной столовой.
НЛП — это другой подход. Алгоритмы учат не только словам и их значениям, но и структуре предложений, внутренней логике языка и пониманию контекстов. Чтобы понять, к чему относится слово «он» в предложении «мужчина был одет в костюм синего цвета», машине необходимо знать свойства терминов «мужчина» и «костюм». Чтобы научить этому компьютер, специалисты используют алгоритмы машинного обучения и методы анализа языка из основ лингвистики.
Теперь мы загружаем модель UDPipe, читаем текстовый файл и обрабатываем его с помощью нашего синтаксиса. Файл должен содержать необработанный текст (одно предложение в строке или один абзац в строке). На выходе получается последовательность лемм и типов слов, разделенных пробелами («green_NOUN tram_NOUN»).
Что такое предварительная обработка текста?
Предварительная обработка текста означает просто перевод текста в формат, предсказуемый для вашей работы, а также поддающийся анализу. Работа здесь представляет собой сочетание подхода и темы. Извлечение ключевых слов из твитов (диапазон) с использованием tfidf (подход) является примером такой работы,
Идеальная предварительная обработка одной задачи может стать худшим кошмаром для другой задачи. Итак, обратите внимание: предварительная обработка текста не может быть перенесена непосредственно из задачи в задачу.
Давайте рассмотрим очень простой пример. Предположим, вы пытаетесь найти часто используемые слова в серии сообщений. Если вы удалите слово отношения во время предварительной обработки, потому что оно было использовано в другой задаче, вы, вероятно, пропустите некоторые общие слова, потому что вы их уже удалили. Поэтому универсального рецепта не существует.
Типы методов обработки текста
Существуют различные способы предварительной обработки текста. Вот некоторые из подходов, о которых вам следует знать, и я постараюсь подчеркнуть важность каждого из них.
Скимминг ВСЕХ текстовых данных является одной из самых простых и эффективных форм предварительной обработки текста, хотя этому часто не уделяется должного внимания. Это применимо к большинству проблем анализа текста и НЛП, и может быть полезно, если ваш набор данных не очень велик, и значительно помогает в достижении ожидаемого результата.
Недавно один из читателей моего блога обучил модель встраивания слов для поиска сходств. Он обнаружил, что различные различия в капитализации исходных данных (например, «Канада» и «Canada») дают разные результаты или вообще не дают результатов. Возможно, это связано с тем, что «Канада» была смешанным случаем в наборе данных, и у нейронной сети было недостаточно данных для эффективного обучения весов для более редкой версии. Такая проблема обязательно возникнет, если ваш набор данных достаточно мал, и нижний регистр — хороший способ справиться с редкостью.
Вот пример того, как строчные буквы решают проблему разреженности, переводя одни и те же слова, написанные разными заглавными буквами, в одну и ту же строчную форму:

Другой пример, когда строчные буквы очень полезны, — это поиск. Представьте, что вы ищете документы, содержащие слово «USA». Однако никаких результатов не было показано, поскольку «USA» было указано как «UNITED STATES OF AMERICA». Кого нам теперь винить? Американский дизайнер, создавший пользовательский интерфейс, или инженер, создавший поисковый индекс?
Нижний регистр должен быть стандартным, но я также встречал случаи, когда верхний регистр был важен. Например, когда речь идет о предсказании языка программирования файла исходного кода. Система слов в Java сильно отличается от системы слов в Python. Близость этих двух показателей делает их одинаковыми, в результате чего классификатор теряет важные прогностические свойства. Строчные буквы, хотя в целом полезны, подходят не для всех задач.
Морфологический
Стемминг сводит слова (например, проблемы) к их корневым словам (например, проблемы), хотя «корневое слово» в этом случае не обязательно является настоящим корневым словом, а просто регулярной формой исходного слова.
Стемминг включает в себя грубый эвристический процесс усечения концов слов в надежде, что слова будут правильно преобразованы в их корневую форму. Например, слова «беспокойство», «тревога» и «проблема» на самом деле могут быть преобразованы в проблему, потому что их края просто отрезаны (о, как грубо!).
Существуют различные алгоритмы. Наиболее распространенным алгоритмом, который также эмпирически показал свою эффективность для английского языка, является алгоритм Портера. Вот пример использования стволовых слов в действии с помощью Porter Stemmer:

Стемминг полезен для решения разреженных проблем, а также для стандартизации лексики. В частности, я добился успеха с поисковыми запросами. Идея заключается в том, что если вы ищете «классы глубокого обучения», вы также хотите найти документы, в которых упоминается «глубокое обучение». Класс обучения И также «классы глубокого обучения», хотя последнее звучит неправильно. Но вы понимаете, к чему мы клоним. Вы хотите собрать все вариации этого слова, чтобы назвать наиболее важные документы.
Однако в большинстве моих предыдущих работ по классификации текстов определение мало способствовало повышению точности классификации, в отличие от использования более продвинутых характеристик и подходов к обогащению текста, таких как встраивание слов.
Автоматическое извлечение. Это направление также предполагает анализ информации, но здесь используется и распознавание, и синтез; задача — обработать большой объем информации и сделать ее краткий пересказ. Это необходимо в бизнесе или науке, когда нужно извлечь наиболее важные моменты из большого набора данных.
Архитектура сети
Прямая передача данных по сети VoiceLoop состоит из четырех последовательных этапов. Сначала выполняется контекстно-свободное кодирование входной фразы и синтезатора речи. Затем вычисляется контекст и обновляется буфер памяти. Последним шагом является генерация выходного сигнала. В случае ошибки буфер памяти перенаправляет выход на предыдущие шаги.
Шаг 1 — Кодирование синтезатора речи и исходного предложения
Каждый синтезатор речи представлен в виде вектора. Во время обучения эти векторы хранятся в таблице поиска (LUT), а для новых синтезаторов, обученных после создания нейронной сети, они вычисляются путем простой оптимизации.
Входное предложение преобразуется в последовательность фонем с помощью словаря произношения Университета Карнеги-Меллона (CMU). Данный словарь содержит 40 фонем, с двумя дополнительными элементами, добавленными для обозначения пауз различной длительности. Затем каждой фонеме присваивается кодировка, основанная на обученной таблице поиска. В результате получается таблица кодирования фонем.
Таким образом, первый шаг включает две плоские сети, таблицу поиска для синтезаторов речи и таблицу поиска для фонем.
Шаг 2 — Контекстный поиск
Для определения контекста применяется механизм монотонного внимания, основанный на распределении Gaussian Mixture Model (GMM). В каждый момент времени выхода сеть внимания получает на вход буфер с предыдущего шага. Сеть имеет скрытый слой и функцию активации ReLU для этого слоя.
Затем, для каждого компонента, все компоненты суммируются и вычисляются веса внимания, чтобы сформировать вектор.
Затем вектор кадра вычисляется как взвешенная сумма столбцов таблицы встраивания входной последовательности (кодирование речи). Функция потерь всей модели зависит от вектора кадров и, следовательно, от вектора внимания.
Шаг 3 — Обновление буфера
На каждом временном шаге в буфер добавляется новый вектор представления в позицию первого столбца. Последний столбец удаляется, а оставшиеся столбцы копируются путем перемещения их вправо. Здесь количество элементов в буфере равно сумме размерности языковой вставки и размерности вывода.
Новый вектор представления вычисляется с помощью полностью подключенной плоской нейронной сети со скрытым слоем и функцией активации ReLU. Сеть принимает на вход буфер с предыдущего этапа, вектор контекста и предыдущие выходные данные. Новое представление также зависит от синтезатора речи и добавляет проекцию его вкрапления в вектор контекста.
Шаг 4 — Генерация выходных данных
Выходные данные генерируются с помощью проекционной матрицы синтезатора речи и нейронной сети, использующей ту же архитектуру, что и на этапах 2 и 3.
Обучение
На выходе получается вектор признаков размерности 63, рассчитанный с помощью инструментария Merlin. Во время обучения выходной сигнал сравнивается с истиной фонетического кодера с помощью среднеквадратичной ошибки (MSE). Этот процесс происходит на каждом временном интервале и требует точного выравнивания между входной и выходной последовательностями.
Но человеческий язык не детерминирован — когда мы повторяем одно и то же предложение, мы каждый раз говорим его по-разному. Поэтому нельзя ожидать, что детерминированный алгоритм предскажет правильные значения. Даже один и тот же фонетический кодер не может повторить себя и полностью устранить потери MSE, поскольку при повторении предложения возникает изменчивость. Метод принуждения учителей решает эту проблему. Эта техника устраняет большую часть вариативности и обеспечивает точное произношение предложений.
В начале обучения сам предсказанный результат также является источником шума, который по мере развития становится все более похожим на реальные образцы голоса. Однако систематическое разграничение между этими двумя понятиями позволяет сети лучше обучаться в ситуациях, возникающих во время тестов. Во время обучения сначала выполняется прямой проход, а затем обратный проход для всех выходных последовательностей без усечения.
Производительность
Полная модель содержит 9,3 миллиона параметров и работает практически в реальном времени на одном процессоре Intel Xeon E5 и в пять раз быстрее на графическом процессоре NVIDIA M40. Следовательно, VoiceLoop может быть адаптирован к мобильному клиенту без специальной оптимизации, как в случае с существующими ненейронными TTS-решениями.
Обучение нового синтезатора речи
Характеристики речи разных людей могут значительно отличаться, и адаптация к этим факторам на основе ограниченного числа образцов голоса — непростая задача. Цель TTS — научиться подражать новому человеку на основе относительно короткого образца голоса. В идеале, новый голос должен интерпретироваться как параметр синтезатора речи, который включает вектор без необходимости переобучения сети. Для этого требуется достаточно большая выборка обучающих голосовых образцов.
Образцы речи и декодированный текст необходимы для обучения нового синтезатора. Процесс обучения выполняется с постоянными весами всех сетей и проекций. В методе стохастического градиентного спуска (SGD) для формирования новой голосовой вставки обновляется только вектор синтезатора речи. Процесс обучения такой же, как описано выше.
Генерация изменчивости
Как упоминалось ранее, естественная речь не детерминирована, и для ее имитации необходимо произносить различные фразы. В отличие от других моделей, VoiceLoop по этой причине не использует случайный элемент (переменный автоэнкодер) и производит выходные последовательности с помощью прайминга.
При прайминге начальный буфер инициализируется на основе процесса ввода, когда в качестве первичного ввода через систему пропускается другое слово или фраза. Это позволяет нам придать буферу окраску — мы получаем разные результаты, если используем в качестве входных данных фразу, которая была сказана в другом эмоциональном контексте. При таком подходе можно достичь желаемого уровня изменчивости.
Эксперименты и результаты
Для экспериментов использовалось несколько наборов данных. Наборы данных для речи одного человека были использованы для сравнения с существующими решениями, которые генерирует только один синтезатор речи. Несколько синтезаторов были обучены на образцах из набора данных VCTK. Также был создан новый набор данных, состоящий из четырех-пяти публичных выступлений разных людей на YouTube.
Эксперименты для синтезатора
Эксперименты проводились на наборах данных из ЖЖ, Нэнси и аудиокниг на английском языке в рамках Blizzard Challenge в 2011 и 2013 годах. Результаты сравнивались с реальными образцами и с методами Char2Wav и Tacotron. Оценки MOS представлены ниже. Как можно видеть, результаты лучше, чем эти два решения, но все же хуже, чем реальные решения.
Оценка MOS (среднее + SD)
| Метод | LJ | Вьюга 2011 | Blizzard 2013 |
| Tacotron Char2Wav VoiceLoop Terrestrial Truth | 2.06 ± 1.02 3.42 ± 1.14 3.69 ± 1.04 4.60 ± 0.71 | 2.15 ± 1.10 3.33 ± 1.06 3.38 ± 1.00 4.56 ± 0.67 | А/А 2,03 ± 1,16 3,40 ± 1,03 4,80 ± 0,50 |
Также была проведена автоматическая проверка совместимости двух тональных последовательностей — Mel Cepstral Distortion (MCD). MCD DTW, метод, использующий динамическое временное искривление (DTW), был использован для временного выравнивания образцов. VoiceLoop также превосходит другие методы, за исключением Tacotron, в наборе данных LJ по результатам оценки. Однако из приведенной выше таблицы видно, что Tacotron не является конкурентоспособным в этом наборе данных.
Показатель MCD (средний + SD, чем ниже, тем лучше)
| Метод | LJ | Вьюга 2011 | Blizzard 2013 |
| Tacotron Char2Wav VoiceLoop | 12.82 ± 1.41 19.41 ± 5.15 14.42 ± 1.39 | 14.60 ± 7.02 13.97 ± 4.93 8.86 ± 1.22 | А/А 18,72 ± 6,41 8,67 ± 1,26 |
Эксперименты для нескольких композиторов
Эксперименты проводились с набором данных VCTK. Записи речи 109 испытуемых были разделены на четыре подгруппы: 22 испытуемых из Северной Америки (мужчины и женщины) и 65, 85 и 101 случайно отобранных образцов, а остальные (87, 44, 24 и 8 записей, соответственно) были использованы для обзора. Все подмножества были разделены на обучающие и тестирующие выборки.
Как видно из рисунка, сгенерированные образцы голоса демонстрируют различное динамическое поведение для разных дикторов. Чтобы сравнить результаты, для создания нескольких синтезаторов речи использовалось приложение с открытым исходным кодом под названием Char2Wav. Ниже показаны значения MOS и MCD, где VoiceLoop снова работает лучше, чем Char2Wav.
Оценка MOS (среднее + SD)
| Метод | VCTK22 | VCTK65 | VCTK85 | VCTK101 |
| Char2Wav VoiceLoop Территориальная истина | 2.84 ± 1.20 3.57 ± 1.08 4.61 ± 0.75 | 2.85 ± 1.19 3.40 ± 1.00 4.59 ± 0.72 | 2.76 ± 1.19 3.10 ± 1.17 4.64 ± 0.64 | 2.66 ± 1.16 3.33 ± 1.10 4.63 ± 0.66 |
Показатель MCD (средний + SD, чем ниже, тем лучше)
Каждый синтезатор речи представлен в виде вектора. Во время обучения эти векторы хранятся в таблице поиска (LUT), а для новых синтезаторов, обученных после создания нейронной сети, они вычисляются путем простой оптимизации.
Обработка текста
Первая задача — отредактировать текст. Мы передадим текст так, как он будет произноситься в будущем. Числа будут представлены словами, а аббревиатуры — раскрыты. Подробнее об этом вы можете прочитать в статье о композиции. Это сложная задача. Итак, предположим, что у нас есть текст, который уже был обработан (в приведенном выше примере он был обработан).
Следующий вопрос заключается в том, какую нотацию использовать: графическую или фонематическую. Для монофонических и моноязычных голосов хорошо подходит алфавитная модель. Если вы хотите работать с полифонической, многоязычной моделью, я рекомендую транскрипцию (и Google).
Для русского языка существует реализация под названием russian_g2p. Он основан на правилах русского языка и хорошо справляется со своей задачей, но у него есть и некоторые недостатки. Он не выделяет все слова и не подходит для многоязычных моделей. Итак, возьмем созданный им словарь, добавим словарь для английского языка и скормим его нейронной сети (например, с помощью этих 1, 2).
Прежде чем обучать сеть, мы должны подумать о том, какие звуки из разных языков звучат похоже и для каких мы можем назначить один и тот же символ, а для каких нет. Чем больше звуков, тем труднее модели их выучить, а если их слишком мало, то у модели будет акцент. Не забудьте присвоить собственные символы ударным гласным. В английском языке вторичное ударение почти не играет роли, и я бы не стал его подчеркивать.
Кодирование спикеров
Сеть похожа на задачу идентификации пользователя по его голосу. В результате получаются разные векторы с номерами для разных пользователей. Я предлагаю использовать реализацию самого CorentinJ, основанную на этой статье. Модель представляет собой трехслойный LSTM с 768 узлами, за которым следует полностью связанный слой с 256 нейронами, обеспечивающий вектор из 256 чисел.
Опыт показывает, что сеть, обученная на английском языке, хорошо работает и на русском. Это значительно облегчает жизнь, поскольку для обучения требуется большой объем данных. Я рекомендую получить уже обученную модель и провести обучение на английском языке из VoxCeleb и LibriSpeech, а также на всех русских языках, которые вы сможете найти. Кодер не требует текстового аннотирования речевых сегментов.
Тренировка
- Запустите файл python encoder_preprocess.py для обработки данных
- Запустите программу «visdom» на отдельном терминале.
- Запустите python encoder_train.py my_run для обучения кодера.
Синтез
Давайте перейдем к синтезу. Модели, которые я знаю, не выводят звук непосредственно из текста, потому что это слишком сложно (слишком много данных). Сначала мы получаем звук в спектральной форме из текста, а затем четвертая сеть переводит его в известный голос. Итак, давайте сначала разберемся, как спектральный вид связан с голосом. Легче понять обратную задачу — как из тона получить спектрограмму.
Тон делится на сегменты по 25 мс с шагом 10 мс (настройка по умолчанию в большинстве моделей). Затем преобразование Фурье используется для расчета спектра (гармонических колебаний, сумма которых дает исходный сигнал) для каждого среза и построения графика, где вертикальная линия представляет спектр среза (по частоте), а горизонтальная линия — последовательность срезов (по времени). Этот график называется спектрограммой. Если частота кодируется не линейно (более низкие частоты имеют более высокое качество, чем более высокие), то вертикальная шкала меняется (необходимо для уменьшения данных), тогда такой график называется mel спектрограммой. Человеческий слух устроен таким образом, что мы слышим небольшое отклонение в низких частотах лучше, чем в высоких, поэтому качество звука не страдает.
Существует несколько хороших приложений для синтеза спектрограмм, например, Tacotron 2 и Deepvoice 3. Для каждой из этих моделей существуют свои реализации, например, 1, 2, 3, 4. Мы будем использовать (как и CorentinJ) модель Tacotron от Rayhane-mamah.
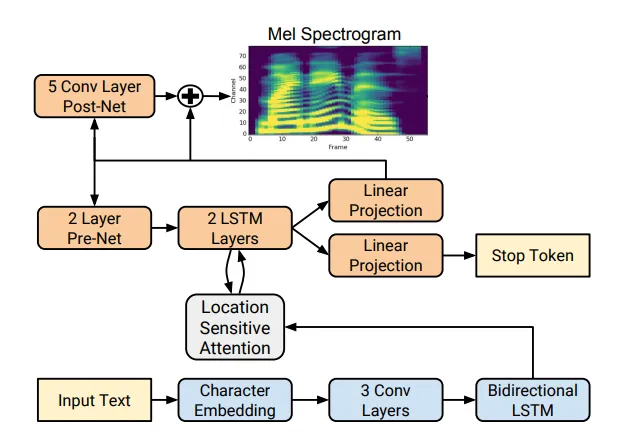
Tacotron основан на сети seq2seq с механизмом внимания. Более подробную информацию см. в статье.
Тренировка
Обязательно отредактируйте utils/symbols.py, если вы составляете не только английский, hparams.ru и preprocess.py.
Для синтеза вам нужен очень чистый, хорошо звучащий звук из разных динамиков. Иностранный язык здесь не поможет.
- Запустите файл python synthesizer_preprocess_audio.py для создания обработанных аудиоданных и спектрограмм.
- Запустите файл python synthesizer_preprocess_embeds.py для кодирования аудиоданных (получите функции языка).
- Запустите python synthesizer_train.py my_run для обучения синтезатора.
К сожалению, в отличие от терминации и лемматизации, не существует стандартного способа нормализации текстов. Обычно это зависит от поставленной задачи. Например, нормализация клинических текстов будет отличаться от нормализации SMS.
Unit selection
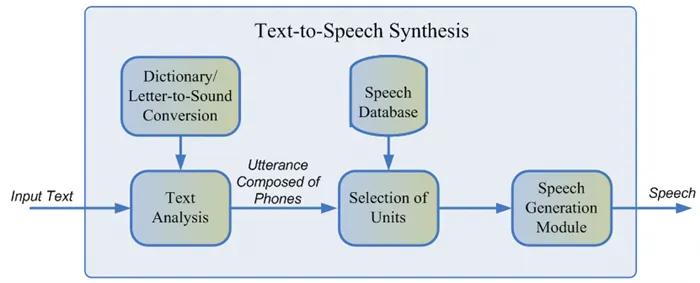
Как правило, записанная речь диктора не может охватить все возможные случаи, когда необходимо использовать синтез. Поэтому суть метода заключается в том, чтобы разбить всю базу данных аудио на небольшие части, называемые единицами, которые затем собираются с минимальной постобработкой. Единицы обычно представляют собой минимальные акустические единицы речи, такие как полутоны или дифтонги 2. Весь процесс производства состоит из двух этапов: Фронтэнд NLP, который отвечает за извлечение лингвистического представления текста, и бэкэнд, который вычисляет штрафную функцию единиц для заданных лингвистических особенностей. Фронт-энд NLP включает в себя:
- Задача нормализации текста заключается в преобразовании всех неалфавитных символов (чисел, процентов, монет и т.д.) в их словесное представление. Например, «5%» следует переводить как «пять процентов».
- Извлечение лингвистических характеристик из нормализованного текста: Представление фонем, произношения, частей речи и т.д.
Обычно фронт-энд NLP реализуется с помощью правил, определяемых вручную для данного языка, но в последнее время наблюдается растущая тенденция к использованию моделей машинного обучения 7.
Штраф, оцениваемый внутренней подсистемой, представляет собой сумму целевой стоимости или согласованности акустического представления единицы для данной фонемы и стоимости конкатенации, т.е. целесообразности соединения двух соседних единиц. Для оценки штрафных функций можно использовать правила или уже обученную параметрическую модель акустического синтеза 2. Выбор оптимальной последовательности блоков с учетом приведенных выше штрафных функций осуществляется с помощью алгоритма Витерби 1.
Приблизительные значения MOS моделей выбора единиц измерения для английского языка: 3.7-4.1 2, 4, 5.
Преимущества подхода, основанного на выборе единицы измерения:
- Естественность звучания.
- Высокая скорость производства.
- Небольшой размер моделей — позволяет использовать композицию непосредственно на мобильных устройствах.
- Синтезированная речь монотонна и безэмоциональна.
- Характеристики потовых артефактов.
- Для обучения требуется достаточно большая база аудиоданных, чтобы охватить все типы кадров.
- В принципе, он не может воспроизводить звуки, которые не встречаются в обучающей выборке.
Параметрический синтез речи
Параметрический подход основан на идее создания вероятностной модели, которая оценивает распределение акустических особенностей данного текста. Процесс генерации речи при параметрическом синтезе можно разделить на четыре этапа:
- НЛП-фронтэнд представляет собой тот же этап предварительной обработки, что и подход выбора единиц, в результате чего получается большое количество контекстно-зависимых лингвистических характеристик.
- Модель длительности, предсказывающая длительность фонем.
- Акустическая модель, которая восстанавливает распределение акустических характеристик по лингвистическим признакам. Акустические характеристики включают значения основной частоты, спектральное представление сигнала и так далее.
- Вокодер, преобразующий акустические особенности в звуковую волну.
Скрытые марковские модели 3, глубокие нейронные сети или их итеративные варианты 6 могут быть использованы для обучения акустических и слуховых моделей. Традиционный кодер речи представляет собой алгоритм, основанный на модели исходного фильтра 3, которая предполагает, что речь является результатом применения линейного фильтра шума к исходному сигналу. Общее качество речи классических параметрических методов довольно низкое из-за большого количества независимых предположений о дизайне процесса генерации звука.
Однако с появлением технологий глубокого обучения стало возможным обучать интегрированные модели, которые предсказывают акустические особенности непосредственно по буквам. Например, нейронные сети 5 Tacotron 4 и Tacotron 2 принимают на вход последовательность букв и возвращают меловую спектрограмму с помощью алгоритма seq2seq 8, заменяя таким образом шаги 1-3 классического подхода одной нейронной сетью. На схеме ниже показана архитектура сети Tacotron 2, в которой достигается довольно высокое качество звука.
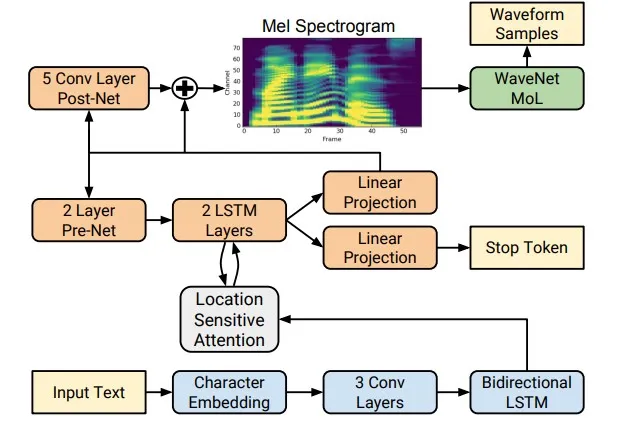
Еще одним фактором значительного улучшения качества синтезированной речи стало использование нейросетевых фонографов вместо алгоритмов цифровой обработки сигнала.
Первым фонетическим кодером такого рода была нейронная сеть WaveNet 9, которая шаг за шагом предсказывала значения амплитуды звуковой волны.
Используя большое количество конволюционных слоев с переходами для захвата большего количества соединений кадров и переходов в архитектуре сети, удалось добиться улучшения MOS примерно на 10% по сравнению с моделями выбора единиц. На следующей диаграмме показана архитектура сети WaveNet.
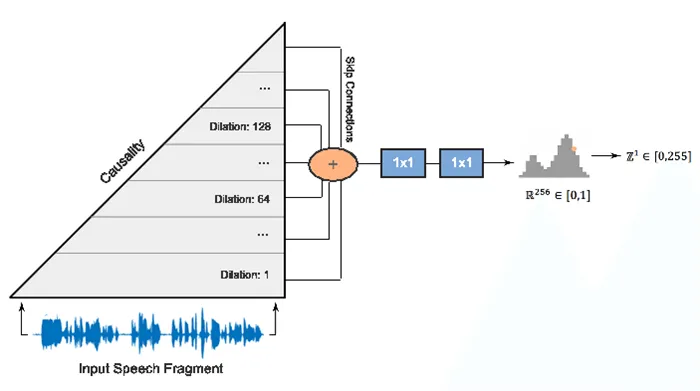
Основным недостатком WaveNet является низкая скорость, связанная с последовательной схемой выборки сигнала. Это может быть преодолено либо технической оптимизацией под конкретную аппаратную архитектуру, либо заменой схемы выборки на более быстрый метод. Оба подхода успешно используются в промышленности. С первым можно ознакомиться на сайте Tinkoff.ru, а в рамках второго подхода компания Google в 2017 году представила параллельную сеть WaveNet 10, наработки которой используются в Google Assistant.
Примерные значения MOS для нейросетевых методов: 4,4-4,5 5, 11, т.е. синтетическая речь практически неотличима от человеческой.
Преимущества параметрического синтеза:
- Более естественное и ровное звучание благодаря непрерывному подходу.
- Больше разнообразия в интонации.
- Использование меньшего количества данных по сравнению с моделями выбора единиц измерения.
Как работает синтез речи в Tinkoff
Как показывает обзор, параметрические методы синтеза речи, основанные на нейронных сетях, в настоящее время значительно превосходят подход, основанный на выборе единиц измерения, и гораздо проще в разработке. Поэтому мы использовали их для создания собственного механизма синтеза. Для обучения моделей мы использовали около 25 часов чистой речи профессионального диктора. Тексты для чтения были намеренно подобраны таким образом, чтобы максимально охватить фонетику разговорного языка. Чтобы внести разнообразие в интонацию синтеза, мы также попросили диктора читать тексты с контекстуальным выражением.
Архитектура нашего решения концептуально выглядит следующим образом:
- NLP front-end, включающий нейронную сеть для нормализации текста и модель для расстановки пауз и ударений.
- Такотрон 2, который принимает буквы в качестве входных данных.
- Autoregressive WaveNet, которая работает в реальном времени на центральном процессоре.
Благодаря такой архитектуре наш движок производит высококачественную, выразительную речь в реальном времени, не требует словаря фонем и позволяет управлять интонацией отдельных слов. Примеры синтетического аудио можно прослушать, перейдя по этой ссылке.
Для предварительной обработки данных используются два подхода. Либо вы генерируете спектрограммы из аудио (используя преобразование Фурье) или из текста (используя модель синтеза). Google рекомендует второй подход.
Как генерировать правдоподобную речь с помощью нейросетей

GAN-TTS — это продуктивная модель для преобразования текста в речь. Архитектура модели состоит из генератора условий и набора дискриминаторов. Дискриминаторы оценивают сгенерированные аудиоданные в случайных окнах разного размера. Дискриминаторы анализируют речь с точки зрения реалистичности и того, насколько точно произнесен входной текст. Исследователи вводят две количественные метрики для оценки качества генерируемой речи: Frechet DeepSpeech Distance и Kernel DeepSpeech Distance. Чтобы узнать, как нейронная сеть выражает текст резюме исследования, перейдите по этой ссылке.
Ранее применение генеративных контрфактических моделей к задаче создания аудиоматериалов было ограниченным. Автопараллельные модели, такие как WaveNet, остаются на переднем крае моделирования человеческой речи. GAN-TTS показывает, как GAN справляется с задачей преобразования текста в речь. Для оценки эффективности модели исследователи используют субъективные отзывы добровольцев и собственные количественные измерения. Количественные входные метрики соотносятся с человеческими оценками.
Основными преимуществами модели являются генерация более реалистичной речи по сравнению с существующим уровнем техники и возможность параллелизации благодаря структуре генератора. Автопараллельные модели, которые часто используются для задач генерации речи, менее поддаются распараллеливанию.
Некоторые сепараторы учитывают лингвистические особенности генерируемой речи, чтобы оценить, насколько хорошо она соответствует входному тексту. Другие разделители фокусируются на реалистичности генерируемой речи.
Архитектура модели
Модели обучаются на наборе данных, состоящем из записей человеческой речи с соответствующими лингвистическими характеристиками и речевых текстов.
Генератор
Генератор получает на вход лингвистические и акустические характеристики. Генератор производит аудиосигнал с частотой 24 килогерца. Генератор состоит из 7 блоков, каждый из которых состоит из двух остаточных блоков. Исследователи используют обширные конволюционные слои, чтобы модель могла изучать долгосрочные зависимости.
Последний слой свертки с тангенсом в качестве функции активации генерирует одноканальный аудиосигнал.
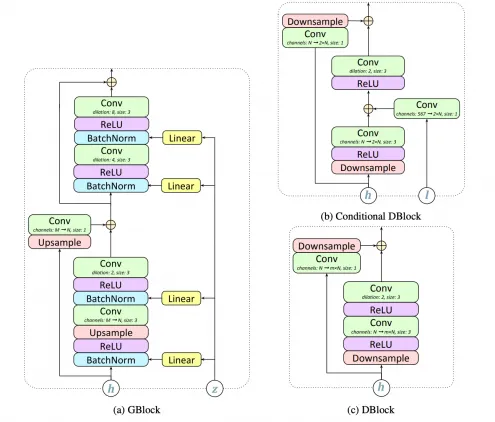
Компоненты генератора (GBlock) и разделителя (DBlock)
Дискриминатор
Сплиттер состоит из блоков, аналогичных блокам генератора, но без нормализации Butch. Архитектура условного блока и стандартного блока показана выше на рисунке (b и c). Единственное отличие условного блока от стандартного заключается в том, что дополнительное включение лингвистических особенностей включено в первый конволюционный слой. Разделитель применяется к случайным небольшим окнам сгенерированного звука.
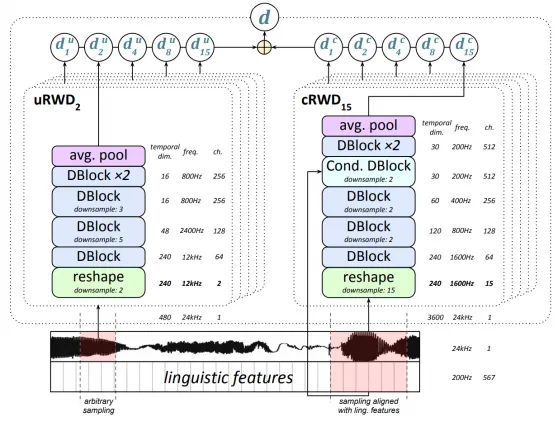
Иллюстрация структуры сепаратора
Оценка результатов модели
Исследователи изучили, какие части модели вносят наибольший вклад в качество прогнозов. Они также сравнили полную версию модели с моделью WaveNet и ее распараллеленной версией. Далее будет показано, что GAN-TTS обеспечивает результаты, сопоставимые с уровнем техники.
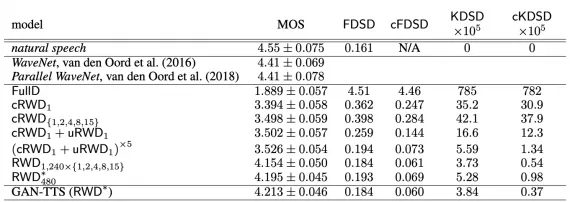
Исследование расстояния между GAN-TTS и сравнение модели с WaveNet, MOS — оценка реализма человека, FDSD и KDSD — предложенные количественные метрики.
В этой статье я хотел бы дать краткий обзор технологий синтеза речи, используемых в отрасли, и представить опыт нашей команды в создании собственного синтезирующего движка.
Ищем семантическую близость
Предположим, нас интересуют следующие слова (пример для русского языка):
Мы спрашиваем у модели 10 ближайших соседей для каждого слова и коэффициент косинусной аппроксимации для каждого слова:
> День_НОУН Неделя_НОУН 0.7375996112823486 День_ПРОПН 0.7067666053771973 Месяц_НОУН 0.7037326097488403 Час_НОУН 0.6643950343132019 Утро_НОУН 0. 6526744365692139 вечер_НОУН 0. 6038411855697632 день_НОУН 0.5923081040382385 воскресенье_НОУН 0.5842781066894531 полдень_НОУН 0.5743687748908997 суббота_НОУН 0.5345946550369263
ночь_NOUN 0.8310786485671997 вечер_NOUN 0.7183679342269897 рассвет_NOUN 0.696594774723053 ночь_NOUN 0.692021906375885 полночь_NOUN 0 6704976558685303 ночь_NOUN 0. 6615264415740967 утро_НОУН 0.6263935565948486 ночь_АДЖ 0.6024709939956665 полдень_НОУН 0.5835086107254028 сумерки_НОУН 0.5671443343162537
человек_НОУН человек_РОПН 0.7850059270858765 человек_АДЖ 0.5915265679359436 существо_НОУН 0.573693037033081 человек_НОУН 0.535444466438293457 человек_НОУН 0. 5296981334686279 человечество_НОУН 0.5282931327819824 человек_РОПН 0.5047001838684082 индивид_НОУН 0.5000404119491577 мораль_АДЖ 0.4972919821739197 поэтому_АДВ 0.49293622374534607
semantic_NOUN semantic_ADJ 0.8019332885742188 syntactic_ADJ 0.7569340467453003 modal_ADJ 0.7296056747436523 semantic_ADV 0.7209396958351135 semantic_ADJ 0. 7159026861190796 референтный_НОУН 0.7135108709335327 ноэтический_АДЖ 0.7080267071723938 лингвистический_АДЖ 0.7067198753356934 лингвистический_АДЖ 0.6928658485412598 предикатный_НОУН 0.68775475025177
Студент_НОУН преподаватель_НОУН 0.6743764281272888 студент_АДЖ 0.6486333608627319 университет_АДЖ 0.6442699432373047 студент_НОУН 0.6423174142837524 первокурсник_НОУН 0. 6409708261489868 студент_НОУН 0.636457085609436 выпускник_НОУН 0.6341054439544678 выпускник_НОУН 0.6337910890579224 университет_НОУН 0.6302101612091064 студент_НОУН 0.629903737303162
student_ADJ не присутствует в модели
Как мы видим, модель сгенерировала 10 ближайших семантических «соседей» для каждого слова. За исключением прилагательного student («student_ADJ»), которое неизвестно модели (и нам). Конечно, он знает прилагательное студенческий:
(‘university_ADJ’, 0.6642225384712219), (‘student_NOUN’, 0.6486333012580872), (‘student_NOUN’, 0.6344770789146423), (‘institute_ADJ’, 0.6142880320549011), (‘grammar school_ADJ’, 0. 5510081648826599), (‘postgraduate_ADJ’, 0.5403808951377869), (‘school_ADJ’, 0.5198260545730591), (‘student_ADJ’, 0.5004373788833618), (‘student_ADJ’, 0.48894092440605164), (‘youth_ADJ’, 0.4792458781849854).
Теперь давайте узнаем, как найти косинус близости пары слов. Это очень просто:
Более сложные операции над векторами
Помимо простейших операций с векторами (нахождение косинуса близости между двумя векторами и ближайшего соседа вектора), мы можем использовать gensim для выполнения более сложных операций с несколькими векторами. Например, мы можем найти лишнее слово в группе. Лишним словом считается то, чей вектор наиболее удален от векторов других слов.
Мы также можем складывать и вычитать векторы из нескольких слов. Например, складывая два вектора и вычитая из них третий вектор, мы можем решить некую аналогию. Подробнее о семантических аналогиях вы можете узнать в материале о системном блоке.
Заключение
В этом руководстве мы попытались понять, как работать с семантическими векторными моделями и библиотекой gensim. Теперь вы можете:
- предварительная обработка текстовых данных, которая может быть полезна во многих задачах обработки естественного языка,
- обучать векторные семантические модели. Формат моделей совместим с форматом веб-сервиса RusVectōrēs,
- выполняет простые операции над векторами слов.
Мы надеемся, что этот учебник поможет нашим читателям глубже погрузиться в мир дистрибутивной семантики и использовать эти инструменты в своей работе!