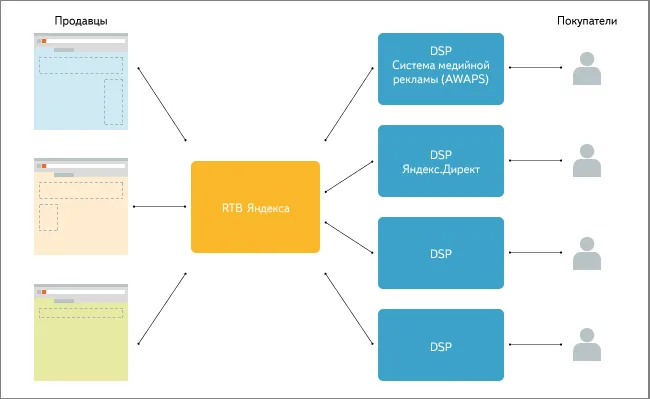
Можно открыть другой файл. При необходимости также используется команда load. Индексирует необходимые объекты и запрещает доступ к папкам.
Рекомендации по настройке файла robots txt
robots.txt представляет собой индексный файл в формате UTF-8.
Он индексируется с рекомендациями для детекторов, т.е. какие страницы должны быть обнаружены, а какие нет.
Если кодировка отличается от UTF-8, поисковые системы могут неправильно интерпретировать содержимое сайта.
Этот файл действителен для протоколов HTTP, HTTPS и FTP и «действителен» только в пределах хоста/протокола/номера порта, на котором размещен хост.
Где находится robots.txt на сайте?
Файл robots.txt имеет только одно местоположение: корневой каталог гостеприимства. Это выглядит так: http: //vash-site.xyz/robots.txt
Директивы файла robots txt для сайта
Существенными деталями файла robots.txt сайта являются правила отказа и указания пользовательского агента. Существуют также вторичные правила.
Правило Disallow
Запреты — это правила, которые указывают поисковым роботам, какие страницы они не должны обнаруживать. И есть несколько конкретных примеров того, как эти правила работают.
Пример 1 — Разрешить индексацию всего сайта.
Пример 2 — Запрет индексирования целых веб-сайтов:.
В таком случае продвижение сайта было бы бесполезным. Применение этого примера относится к случаям, когда сайт «закрыт» для доработки (например, не работает должным образом). В этом случае для сайта нет места в SERP, поэтому для его индексации необходимо использовать близлежащий TXT-файл робота. Конечно, после того как сайт будет доработан, запрет на индексацию нужно снять, но забыть об этом нельзя.
Пример 3 — Все документы в папке / papka / не должны индексироваться.
Пример 4 — Запрет индексирования страниц с определенными URL:.
Пример 5 — Запрет на индексирование определенных файлов (в данном случае изображений):.
Пример 6 — Способ Robot TXT закрыть файлы с определенным расширением (в данном случае — .gif) из индекса:.
Звездочка перед .gif $ означает любое имя файла, а символ указывает на конец строки. Другими словами, такая «маска» запрещает сканирование всех файлов GIF.
Правило Allow в robots txt
Правило Allow прямо противоположно: индексируйте файл/папку/страницу.
И вот конкретный пример:.
Мы с вами уже знаем, что можно исключать сайты из robots txt. В то же время, существует лул, который позволяет /catalogy обнаруживать папки: /catalogy. Поэтому комбинация этих двух правил распознается поисковым детектором как «сайты запрещены, кроме папок /catalogy».
Перестройте правила на разрешающие и разрешенные: порядок длин URL увеличивается и применяется последовательно. Если для одной и той же страницы имеются разные правила, робот выбирает из списка последнее.
Рассмотрим две ситуации с двумя противоречивыми правилами: одно запрещает индексировать папку/контент, а другое разрешает.
В этом случае разрешающие директивы имеют приоритет, как показано в конце списка.
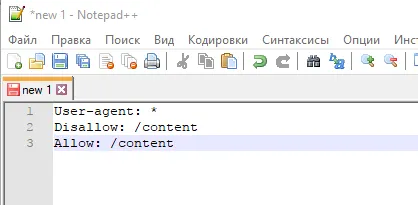
И здесь директива запрета приоритетна по той же причине (ниже в списке): директива
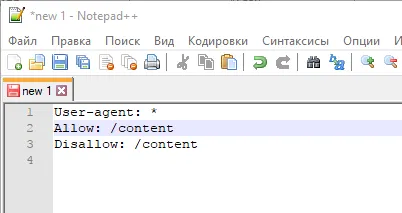
User-agent в robots txt
User-Agent — это правило, которое «адресовано» детекторам поисковых систем, например, «список рекомендаций специально для вас» (по совпадению, в robots.txt могут быть разные списки для разных поисковых систем Google и Яндекс)
Например, в этом случае он говорит: «Привет, GoogleBot, вот несколько рекомендаций, специально подготовленных для вас». .
Правильный робот Google TXT (GoogleBot)
Почти такая же история с поисковым роботом Яндекса. Забавно, но список рекомендаций Яндекса почти в 100% случаев несколько отличается от списка других поисковых ботов (почему — объясним чуть позже). Но суть та же: «Здравствуйте Яндекс, у нас для вас есть еще один список» — «Хорошо, давайте его изучим».
Самые частые вопросы
Как в robots.txt запретить индексацию?
Для этой цели было придумано правило запрета. То есть, скопируйте ссылку из индекса на документ/файл, который вы хотите закрыть, и введите ее после точки с одной стороны и ниже.
Затем удалите адрес поля (в данном случае удалите это расположение — http: // -site.xyz). После удаления остается именно то, что необходимо оставить.
Если вы хотите заблокировать все файлы с определенным расширением из индекса, правила следующие
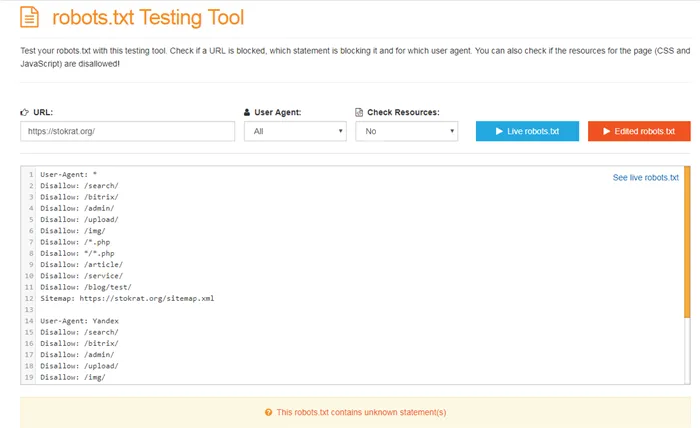
Как в robots.txt указать главное зеркало?
Для этой цели была придумана директива host. Это означает, что адрес http://your-site.xyzとhttp://yoursite.comが同じサイトのミラーである場合, один из которых должен быть указан в директиве host. http://your-site.xyzをメインミラーとします. В этом случае правильным вариантом будет
— Если сайт работает по протоколу HTTPS, он должен это делать.
— Если сайт работает по протоколу HTTP, оба варианта верны.
Однако помните, что директива хоста — это рекомендация, а не правило. Это означает, что если центральный компьютер принимает решение по одному сектору, а Яндекс вводит соответствующие настройки в таблицу вебмастера, то может быть рассмотрено другое главное зеркало.
Простейший пример правильного robots.txt
В таком формате файл robots.txt может быть размещен практически на любом сайте (с небольшими корректировками).
Проанализируйте то, что у вас есть.
- Здесь 2 списка правил – один «персонально» для Яндекса, другой – для всех остальных поисковых роботов.
- Правило Disallow: пустое, а значит никаких запретов на сканирование нет.
- В списке для Яндекса присутствует директива Host с указанием основного зеркала, а также, ссылка на карту сайта.
Однако… Это не означает, что robots.txt должен быть оформлен именно таким образом. Правила должны быть строго индивидуальны для каждого места. Например, не имеет смысла индексировать «технические» страницы (страницы ввода логина или тестовые страницы, отлаженные с новым дизайном сайта, и т.д.). По совпадению, правила зависят от используемой CMS.
Закрытый от индексации сайт – как выглядит robots.txt?
Независимо от CMS, предоставьте код, готовый отключить сайт самостоятельно.
Как указать главное зеркало для сайта на https robots.txt?
Важно. Для https-леггинсов протокол должен быть строго обязательным!
Чтобы боты правильно интерпретировали ‘noindex’ и ‘nofollow’ и не добавляли страницы в индекс, не блокируйте одновременно доступ к файлу robots.txt. Таким образом, боты не смогут получить доступ к странице, и инструкции по запрету не будут отображаться.
Когда закрывать сайт целиком, а когда — его отдельные части?
Сайтам малого бизнеса обычно не требуется скрывать отдельные страницы. Если ресурс содержит большое количество информации о владельцах, создайте закрытые ворота или закрытую страницу и целый модуль.
Рекомендуется индексировать SO -Caled Pages ненужных страниц. Это старые новости, события и события календаря. Если вы поддерживаете интернет-магазин, убедитесь, что он не содержит устаревших предложений, скидок или товаров, которые были удалены поисковыми системами. Информационные сайты закрывают статьи с устаревшей информацией. В противном случае ресурс считается неактуальным. Чтобы избежать закрытия статей и ресурсов, регулярно обновляйте свои данные.
Также рекомендуется скрывать всплывающие окна и баннеры, скрипты и файлы, размещенные на сайте, особенно если последние имеют большой вес. Это сокращает общее время индексации, положительно воспринимается поисковыми системами и снижает нагрузку на сервер.
Как узнать, закрыт ресурс или нет?
Чтобы проверить, был ли проиндексирован робот TXT, сначала проверьте: был ли уже закрыт сайт или отдельная страница? В этом могут помочь yandex.webmaster и Google Search console. Они покажут вам, какие URL-адреса вашего сайта были проиндексированы. Если ваш сайт не был добавлен в сервисы поисковых систем, вы можете воспользоваться бесплатной программой Yandex Age Tools от Pixel Tools.
- Для начала найдите в корневой папке сайта файл robots.txt. Для этого используйте поиск.
- Если ничего не нашли — создайте в Блокноте или другом текстовом редакторе документ с названием robots расширением .txt. Позже его надо будет загрузить в корневую папку сайта.
- Теперь в этом файле HTML-тегами детально распишите, куда заходить роботу, а куда не стоит.
Как полностью закрыть сайт в роботс?
Пример закрытия основного участка робота показан ниже. Все они отмечены знаком *.

Файл robots.txt позволяет скрыть папки, файлы, сценарии и UTM-метки на вашем сайте. Они могут быть скрыты полностью или выборочно. В нем также указывается запрет на индексацию для всех роботов или тех, кто ищет изображения, видео и т.д. Например, команда яндексу не отправлять поиск изображений выглядит следующим образом
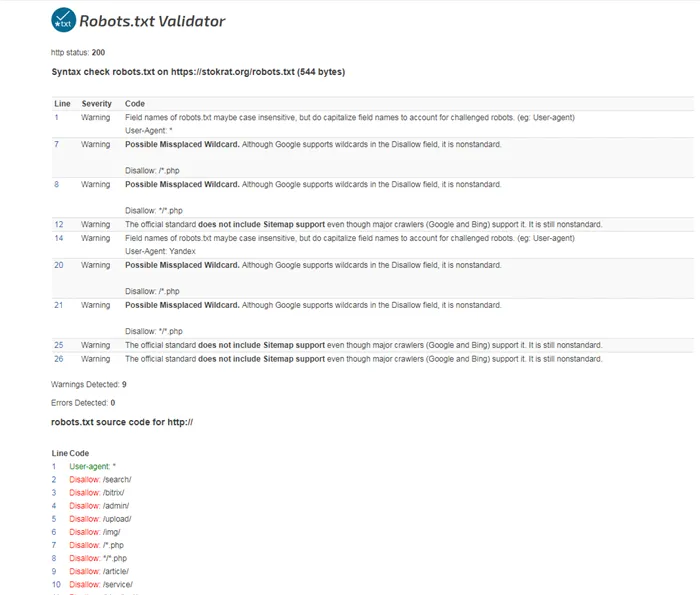
Здесь Yandeximages — это имя робота для поиска изображений Яндекса. С помощью поисковой системы можно увидеть полный список роботов.
Как закрыть отдельные разделы/страницы или типы контента?
Выше мы показали, как предотвратить проникновение основных или вспомогательных роботов на ваш сайт. Можно использовать несколько иные подходы. Вместо того чтобы искать имя робота, отвечающего за поиск изображений, вы можете запретить всем роботам искать определенные типы контента на вашем сайте. Это должно быть указано либо через disallow:/ типа *.extensionFiles, либо соответствующим адресом страницы или класса.

Прячем ненужные ссылки
Может возникнуть необходимость скрыть ссылки из индекса на странице. Для этого есть два варианта.
- В HTML-коде самой этой страницы укажите метатег robots с директивой nofollow. Тогда поисковые роботы не будут переходить по ссылкам на странице, но на них может вести другой материал вашего или сторонних сайтов.
- В саму ссылку добавьте атрибут rel=»nofollow».
Эта функция указывает роботу игнорировать ссылку. В этом случае запрет на индексацию действует и тогда, когда поисковая система находит ссылку не через пеллет. Здесь переход ограничивается HTML-кодом.
Как закрыть сайт через мета-теги
Альтернативой файлу robots.txt является метка, которая предотвращает индексирование сайта или типа контента. Это робот мета-тегов. Он размещается в исходном коде сайта в файле index.html.
Существует два способа написания мета-ярлыка.

Определите, какие трекеры не индексируются. Для всех остальных напишите робота. Для роботов укажите их название: GoogleBot, Yandex.
Поле «Содержание» в варианте 1 может иметь следующие значения.
- none — индексация запрещена, включая noindex и nofollow;
- noindex — запрещена индексация содержимого;
- nofollow — запрещена индексация ссылок;
- follow — разрешена индексация ссылок;
- index — разрешена индексация;
- all — разрешена индексация содержимого и ссылок.
Поэтому вы можете запретить содержимое сайта независимо от файла robots.txt, используя content = «noindex, follow». Или частично разрешить: например, не нужно индексировать текст, но не ссылки. Используйте комбинацию цен для разных случаев.
Если вы хотите заблокировать сайт от индексирования метатегов, вам не нужно создавать отдельный файл Robots.txt.
Директива — это список из одной или нескольких команд или инструкций поискового робота robots.txt для управления индексацией сайта.
Синтаксис и директивы robots.txt
Аннуитет robots.txt состоит из двух частей.
Чтобы поисковые системы правильно поняли эти инструкции, они должны быть расположены в строго определенном порядке. Первая инструкция в следующем разделе — это пользовательский агент, который должен разрешить основное зеркало сайта, а затем разрешить хостинг, а затем хостинг.
Самое главное — не допускать ошибок или тщательно подходить к созданию инструкций, а следить за тем, чтобы инструкции были правильными и не вводили в заблуждение. Помните, в начале статьи мы говорили о персонаже, ответственном за срыв всех SEO-задач? Именно ‘non-ban:/’ сделал невозможным индексирование целых веб-сайтов. Разработчики часто делают это при создании тестовых версий сайтов, которые не попадают в поисковые системы.
Главное — открыть весь сайт для индексации или запретить определенные страницы после их загрузки на сервер.
Если вы не хотите, чтобы это произошло, вам необходимо знать определенные правила создания robots.txt.
- Одна строка — одна директива.
- Любая директива записывается только с новой строки.
- Недопустимы пробелы в начале строк и между ними.
- Когда вы описываете параметр, его нельзя переносить на новую строку.
- Как в названии самого файла, так и в параметрах директив не должно быть строчных букв.
- Перед всеми папками нужно ставить прямой слэш (/): например /category.
- Все директивы описываются только латинскими символами.
- Допускается использовать в директивах Allow и Disallow только один параметр.
- Если Disallow не содержит в себе параметр, она считается эквивалентной Allow: /, что разрешает индексацию всех страниц сайта.
- Если Allow не содержит в себе параметр, онай считается эквивалентной Disallow: /, что запрещает индексацию всех страниц сайта.

Давайте рассмотрим основные инструкции для robots.txt.
Пользовательский агент. Это обязательная директива, записываемая в начале файла и инициирующая вызов детектора поисковой системы.
#Привлекательно для всех поисковых систем.
#Адрес только для роботов яндекса
#Привлекателен только для роботов Google.
Запрет. Директива запрещает обход различных частей сайта.
#Все роботы исключены из индекса Unity и всех страниц в нем
Разрешено. Эта директива позволяет обнаружить все разделы сайта и все содержащиеся в них страницы.
# Разрешить всем детекторам поисковых систем обнаруживать весь сайт.
noindex. Эта директива гарантирует, что программе обнаружения не будет разрешено пересекать части содержимого конкретной страницы. Она отличается от запрета тем, что прописана в кодексе страницы и выглядит как
Чистая парама. Эта директива отключает индексацию параметров адреса страницы. Он требуется только для Yandex Crawler. Это позволяет удалять UTM из индекса и предотвращает появление двойных страниц.
Clean-Param: Директива UTM# применяется к любому параметру адресной страницы
Задержка ползучести. Директива определяет минимальный период между обнаружениями.
После # индексации страницы робот Google начинает индексировать начальную страницу через 4 секунды.
Ведущий. Устанавливает главное зеркало директивного сайта.
Карта сайта. Корневая директива Sitemap:.
Карта сайта: yoursite.com/sitemap.xml
Как упоминалось ранее, файл может быть использован для индексации всех страниц, так что сайт может быть полностью запрещен.
Вы также можете выборочно блокировать индексируемую часть сайта для различных роботов.
Если вы хотите, чтобы директива применялась ко всем детекторам, добавьте звездочку (*) в конце первой строки. Если вы хотите, чтобы инструкция применялась только к определенному роботу, укажите его имя после инструкции агента пользователя.
Инструкции, заданные для всех роботов, имеют звездочку (*) в конце первой строки. При обращении к конкретной поисковой системе укажите ее название в первой строке инструкции user-agent.
Как запретить индексацию сайта в robots.txt
Чтобы запретить индексирование отдельных страниц, разделов или всего сайта, используйте инструкцию запрета следующим образом.
# Доступ роботов ко всем страницам сайта запрещен
Как закрыть страницу от индексации в robots.txt
# Отказано роботу Google в доступе ко всем страницам, начинающимся с ‘/page’.
Сервисы проверки robots.txt
В качестве примера рассмотрим файл с сайта Kokoc.com.
Откройте сервис и перейдите в Инструменты -> Разрешение Robots.txt. Далее введите адрес рассматриваемого сайта и все его данные должны быть получены.
Как и ожидалось, в файле нет ошибок.
К сожалению, сервис здесь предлагает выбрать объекты управления только с моих ресурсов, поэтому прошу привести пример robots.txt.
Я рад, что чек оказался успешным.
На главной странице сайта выберите Инструменты → Все инструменты → разрешение robots.txt. Введите целевой URL-адрес и получите результаты.
Это, пожалуй, самая полезная из всех исследованных услуг.
Выберите тестер robots.txt на главной странице сайта. В появившемся окне введите URL-адрес назначения и выберите из списка роботов (можно выбрать всех). Нажмите красную кнопку в разделе «Тест». Стоит отметить, что файлы можно открывать в «живом» режиме и в режиме обработки.
Сервис также отображает маршрут к карте страницы и ее статус.
На домашней странице службы выберите Технические средства контроля → Проверить файл robots.txt. В окне Проверка можно ввести как URL, так и файл сайта для получения проверяемого URL. Результаты показаны ниже.
Особенностью сервиса является то, что вы можете выбрать как роботов, необходимых для проверки каждой инструкции, так и целевую CMS, на которой был создан сайт.
Помните о роботах!
robots.txt — это небольшой файл, который скрывает большие возможности для грамотных веб-мастеров и SEO-специалистов, и большие проблемы, если их не решать.
Это один из гарантов быстрой и правильной индексации сайта. Поисковые системы очень уважительно относятся к тем, кто выполняет их требования.