На некоторых сторонних платформах нет возможности управлять файлом robots.txt. Wix, например, автоматически создает robots.txt для каждого проекта на платформе. Вы можете просмотреть файл, добавив «/robots.txt» в конец домена.
Роботы поисковых систем Яндекс и Google посещают страницы, оценивают содержание и добавляют новые ресурсы и информацию о страницах в базу данных индекса поисковой системы. Боты регулярно посещают страницы, чтобы добавить обновленный контент в базу данных и отметить новые ссылки и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты не изучают все страницы сайта. Их количество ограничено бюджетом краулинга, который представляет собой количество URL-адресов, которые может просмотреть краулинг-бот. Бюджета на создание большого сайта может не хватить. Существует риск, что бюджет на краулинг будет использован для нерелевантных или «нежелательных» страниц, и чтобы избежать этого, веб-мастера направляют краулеры с помощью файла robots.txt.
Боты заходят на сайт, находят файл robots.txt в корневом каталоге, анализируют доступ к страницам и переходят к карте сайта, чтобы сократить время сканирования без доступа к закрытым ссылкам. После проверки файла боты переходят на главную страницу и оттуда углубляются на сайт.
Какие страницы краулер просканирует быстрее:
- Находятся ближе к главной. Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI).
- Имеют много ссылок. Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается.
- Быстро загружаются. Проверьте скорость загрузки инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
Все посещения краулер-бота не регистрируются такими инструментами, как Google Analytics, но поведение бота можно отследить в журналах. Некоторые SEO-проблемы крупных сайтов можно решить путем анализа журналов, которые также помогают выявить проблемы со ссылками и распределить бюджет на ползание.
Robots.txt для Яндекса и Google
Администраторы сайтов могут контролировать поведение ботов, ползающих по сайту, с помощью файла robots.txt. robots.txt — это текстовый файл для поисковых машин с указаниями по индексированию. Он используется для указания того, какие страницы и файлы на сайте могут быть запрещены к просмотру. Это позволяет ботам сократить количество запросов к серверу и не тратить время на неинформативные, одинаковые или нерелевантные страницы.
В файле robots.txt можно разрешить или заблокировать доступ ко всем файлам или индивидуально указать, какие файлы могут быть просканированы, а какие нет.
Требования к robots.txt:
- файл называется » robots.txt «, название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, переведите все кириллические ссылки в Punycode для robots.txt с помощью любого конвертера Punycode: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt применяется к HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и указывает только хост, протокол и номер порта, на котором он находится.
Он может быть добавлен к адресам с поддоменами — http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если сайт имеет несколько поддоменов, поместите файл в корневой каталог каждого поддомена.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt вы можете запретить ботам индексировать определенный контент.
Яндекс поддерживает протокол блокировки ботов. Администратор сайта может скрыть контент от индексации ботами Яндекса, указав директиву «disallow». Тогда при следующем посещении сайта боты загружают файл robots.txt, видят запрет и игнорируют страницу. Другой способ удалить страницу из индекса — добавить в HTML-код тег «noindex» или «none».
Google предупреждает, что robots.txt не предназначен для предотвращения появления страниц в результатах поиска. Вы можете исключить из индексации только определенные типы контента: Медиафайлы, неинформативные изображения, скрипты или стили. Вы можете заблокировать страницу из результатов Google, используя пароль на сервере или HTML-элементы «noindex» или атрибут «rel» со значением «nofollow».
Если есть ссылка на страницу на этом или другом сайте, она может попасть в индекс, даже если она недоступна в файле robots.txt.
пароль или «nofollow», если вы не хотите, чтобы страница индексировалась Google. Если вы этого не сделаете, ссылка появится в результатах, но будет выглядеть следующим образом:
Этот тип ссылки означает, что страница доступна для пользователей, но бот не может создать описание, поскольку доступ к странице заблокирован в файле robots.txt.
Содержимое файла robots.txt — это инструкции, а не команды. Большинство поисковых роботов, включая Googlebot, принимают этот файл, но некоторые системы могут его игнорировать.
Если нет доступа к robots.txt
Если у вас нет доступа к robots.txt и вы не знаете, доступна ли страница в Google или Yandex, введите ее URL в строке поиска.
Как составить robots.txt правильно
Файл может быть создан с помощью любого текстового редактора и сохранен в формате txt. В нем должны содержаться инструкции для роботов, указывающие, на какие роботы отвечать, а также разрешение или запрет на сканирование файлов.
Инструкции отделяются друг от друга переводом строки.
Символы robots.txt
Символ «*» обозначает любую последовательность символов в файле.
«$» — ограничивает действие символа «*», который обозначает конец строки.
«/» — указывает на то, что он закрыт для сканирования.
«/catalog/» — закрывает раздел каталога,
«/catalog» — закрывает все ссылки, начинающиеся с «/catalog».
«#» — используется для комментариев, боты игнорируют текст с этим символом.
Пользовательский агент: * Disallow: /catalog/ #запрещает сканирование каталога.
Директивы robots.txt
Заявления, которые распознаются всеми краулерами:
User-agent
В первой строке напишите правило user-agent, определяющее, какой бот должен отвечать на рекомендации. Если нет правила запрета, файлы считаются доступными.
Поисковые системы используют разных ботов для разных типов контента:
- Google: основной поисковый бот называется Googlebot, есть Googlebot News для новостей, отдельно Googlebot Images, Googlebot Video и другие;
- Яндекс: основной бот называется YandexBot, есть YandexDirect для РСЯ, YandexImages, YandexCalendar, YandexNews, YandexMedia для мультимедиа, YandexMarket для Яндекс.Маркета и другие.
Вы можете задать собственную политику для отдельных ботов, если вам нужны рекомендации по типу контента.
Пользовательский агент: * — это правило для всех ботов поисковых систем,
Пользовательский агент: Googlebot — только для основного поискового бота Google,
User-Agent: YandexBot — только для основного бота Яндекса,
Пользовательский агент: Яндекс — для всех ботов Яндекса. Если бот Яндекса распознает эту строку, другой агент пользователя: * не принимается во внимание.
Sitemap
Отображает ссылку на sitemap — файл со структурой сайта, в котором перечислены страницы, подлежащие индексации:
User-Agent: * Sitemap: http://site.com/sitemap.xml
Некоторые веб-мастера не делают sitemap, это не является обязательным требованием, но лучше сделать sitemap — этот файл воспринимается краулерами как структура страниц, которые не могут быть проиндексированы, но должны быть проиндексированы.
Disallow
Правило показывает, какую информацию они не должны вылавливать
Предотвращение сканирования всех файлов, заканчивающихся на «.pdf»:
Файл, созданный для сайта, является важным аспектом оптимизации для поисковых систем. Зачем нам нужен robots.txt? В оптимизации поисковых систем robots.txt необходим, например, для исключения из индексации страниц, не содержащих полезного контента. Как, что, почему и зачем исключается, уже было описано в статье о запрете сайтов к индексации, поэтому здесь мы не будем углубляться в эту тему. Всем ли сайтам нужен файл robots.txt? И да, и нет. Когда речь идет об исключении страниц из поиска, эти исключения могут быть излишними для небольших сайтов с простой структурой и статичными страницами. Но даже для небольшого сайта некоторые политики могут быть полезны, например, политика хоста или sitemap, но об этом подробнее ниже.
Поскольку это текстовый файл, вы должны использовать любой текстовый редактор, например, Блокнот. Открыв новый текстовый документ, вы уже приступили к созданию robots.txt; вам просто нужно составить содержимое в соответствии с вашими требованиями и сохранить его в виде текстового файла в формате robots in txt. Это легко, и создание файла не представляет проблемы даже для новичков. В следующих примерах я покажу вам, как создавать роботов и что можно в них включать.
Вариант для ленивых: скачать в готовом формате. Многие сервисы предлагают создание текстовых роботов онлайн, выбор за вами. Самое главное — четко знать, что запрещено, а что разрешено. В противном случае создание файла robots.txt в Интернете может стать трагедией, которую потом будет трудно исправить. Особенно если поисковая система находит то, что не должно было быть разрешено. Внимание — проверьте файл robots, прежде чем загружать его на сайт. Однако пользовательский файл robots.txt более точно отражает структуру ограничений, чем файл, который был автоматически создан и загружен с другого сайта. Читайте далее, чтобы узнать, на что следует обратить внимание при редактировании robots.txt.
После того как вам удалось создать файл robots.txt в Интернете или своими руками, вы можете отредактировать robots.txt. Вы можете изменять содержимое по своему усмотрению, если соблюдаете определенные правила и синтаксис robots.txt. По мере работы над вашим сайтом файл robots.txt может меняться, поэтому, если вы редактируете robots.txt, не забудьте загрузить обновленную версию файла со всеми изменениями. Далее рассмотрим правила настройки файла, чтобы вы знали, как изменить файл robots.txt и "не нарубить дров".
Правильно настроенный файл robots.txt не позволяет частной информации быть
# Задает инструкции для всех роботов сразу User-agent: # Задает инструкции для всех роботов Яндекса User-agent: Yandex # Задает инструкции только для главного робота индексации Яндекса User-agent: YandexBot # Задает инструкции для всех роботов Google User-agent: Googlebot
Обратите внимание, что такая конфигурация файла robots.txt определяет, что робот будет использовать только инструкции, соответствующие названному агенту пользователя.
Пример robots.txt с несколькими экземплярами агента пользователя:
# Используется всеми роботами Яндекса User-agent: Yandex Disallow: /*utm_ # Используется всеми роботами Google User-agent: Googlebot Disallow: /*utm_ # Используется всеми роботами, кроме роботов Яндекса и Google User-agent: # Allow: /*utm_
Директива user-agent дает указания только для конкретного робота, в то время как за директивой user-agent должны непосредственно следовать одна или несколько команд, которые напрямую задают условие для выбранного робота. В приведенном примере используется директива disallow, которая имеет значение «/*utm_». Если вы правильно настроили robots.txt, пустые строки между «User-agent», «Disallow» и директивами, следующими за «Disallow» в пределах текущего «User-agent», не будут разрешены.
Пример неправильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=.
Пример правильного перевода строк в robots.txt:
User-Agent: Yandex Disallow: /*utm_ Allow: /*id= User-Agent: * Disallow: /*utm_ Allow: /*id=.
Для чего нужен robots.txt
Как видно из примера, инструкции в robots.txt разделены на блоки, причем каждый блок содержит инструкции либо для конкретного робота, либо для всех роботов «*».
Кроме того, важно поддерживать правильный порядок и сортировку инструкций в robots.txt, когда такие инструкции, как «Disallow» и «Allow», используются вместе. Директива «Allow» противоположна директиве «Disallow» в robots.txt.
Cоздать robots.txt онлайн
Пример совместного использования директив в файле robots.txt:
Пользовательский агент: * Разрешить: /blog/page Запретить: /blog.
Правильная настройка robots.txt
Этот пример запрещает всем роботам индексировать все страницы, начинающиеся с «/blog», но разрешает индексировать страницы, начинающиеся с «/blog/page».
Предыдущий пример robots.txt отсортирован правильно:
Агент пользователя: * Не разрешать: /blog Разрешить: /blog/page.
Сначала запретите весь раздел, а затем разрешите некоторые его части.
Еще один пример действующего robots.txt с общими инструкциями:
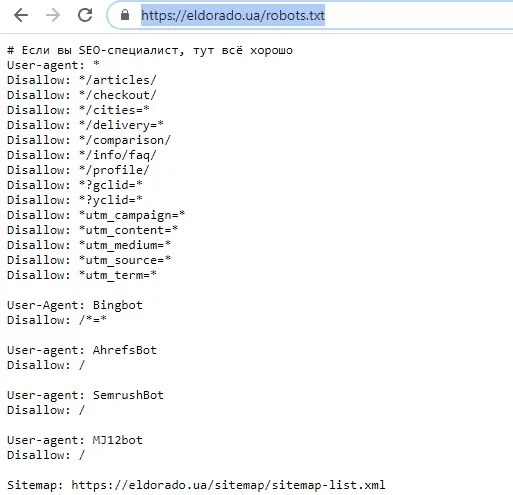
Файл robots.txt располагается в корневом каталоге сайта. Например, на сайте https://webmasterie.ru путь к файлу robots будет таким: https://webmasterie.ru/robots.txt.
Чтобы создать файл самостоятельно, вы можете использовать любой текстовый редактор:
В документе установите инструкции в соответствии с вашими целями и сохраните
Одним из вариантов для ленивых людей являются онлайн-сервисы, которые автоматически создают роботов. В Интернете можно найти множество подобных инструментов, например, CY-PR.
Этот вариант хорош для владельцев большого количества сайтов, поскольку вручную написать почти одинаковые инструкции для всех сайтов было бы сложно.
Автоматически созданные файлы robots.txt могут нуждаться в самостоятельной корректировке, поэтому необходимы базовые знания синтаксиса и правил написания файла.
Нетрудно найти готовые шаблоны robots.txt для популярных поисковых систем, таких как WordPress, Joomla, Drupal и так далее. В шаблоне останется только избавиться от повторяющегося написания стандартных инструкций и учесть нюансы конкретного движка сайта. Но опять же, требуются знания, поскольку сам шаблон не предоставляет правильно настроенного файла, а каждый проект может быть разным.
Автоматически созданные файлы robots.txt могут нуждаться в самостоятельной корректировке, поэтому необходимы базовые знания синтаксиса и правил написания файла.
Файл Robots.txt содержит инструкции для поисковых машин, которые помогают им понять, какие страницы/разделы должны быть проиндексированы, а какие нет. Давайте теперь проанализируем смысл этих указаний:
1) User-Agent: Это обязательная политика, которая определяет, к какому роботу должны применяться следующие правила. По сути, это ссылка на конкретного робота или на всех поисковых роботов. Все файлы начинаются с этой строки.
2. запрет. Это наиболее распространенная политика, запрещающая индексирование отдельных страниц или целых разделов сайта. Эта политика часто указывается здесь:
В нем можно использовать специальные символы * и $.
3) Разрешить. Эта директива противоположна директиве Disallow и позволяет краулерам получать доступ к определенным страницам или разделам сайта. Здесь, как и в случае с Disallow, разрешены подстановочные знаки.
4) Sitemap. Эта политика позволяет ботам определять местоположение XML-карты сайта. Указание полного URL важно для поисковых систем Google и Yandex, поскольку при обходе сайта они сначала попадают на сайт, где указана структура ресурса с внутренними ссылками, приоритеты индексации страниц и дата их создания или изменения.
5. clean-param. Предотвращает обход ботами страниц с динамическими параметрами, которые полностью дублируют содержание основных страниц. Проблема динамических параметров решается
7. хост (больше не поддерживается Яндексом): Это была междоменная директива, которая существовала только на Яндексе и не понималась другими поисковыми системами. Он использовался для того, чтобы показать главному роботу Яндекса основное зеркало сайта, когда к сайту обращаются несколько доменов. Но по состоянию на март 2018 года Яндекс больше не использует политику хостинга. Его функции взял на себя модуль миграции сайтов в Вебмастере и 301 перенаправление.
1. Прежде всего, роботам должно быть запрещено добавлять в индекс дубликаты страниц. Для доступа к странице должен использоваться только один URL. Обращаясь к сайту, поисковый робот должен получить в ответ страницу с уникальным содержимым для каждого URL. Дубликаты часто уже отображаются в CMS при создании страницы. Например, один и тот же документ можно найти под техническими URL http://site.ru/?p=391&preview=true и CNC http://site.ru/chto-takoe-seo. Из-за динамических ссылок часто возникают дубликаты. Все они должны быть скрыты от индекса с помощью масок:
Где находится и как создать?
Вот как выглядит типичный шаблон файловой структуры робота для обычного веб-сайта:
Ручное создание robots.txt
User-agent: Yandex Disallow: /admin Disallow: *?s= Запретить: *?p= User-agent: Googlebot Disallow: /admin Disallow: *?s= Запретить: *?p= User-agent: * Disallow: /admin Disallow: *?s= Запретить: *?p= Sitemap: https://site.ru/sitemap.xml
- Блокнот;
- Microsoft Word;
- NotePad++;
- SublimeText и т.д.
Как видно из приведенных выше утверждений, файл содержит блоки утверждений и, как упоминалось ранее, начинается с правила user-agent, которое определяет, на какого бота оно нацелено, и устанавливает следующие утверждения.
Вот несколько примеров заявлений пользовательского агента для различных ботов поисковых систем:
- панель управления сервером, к примеру, Cpanel или ISPmanager;
- консоль, админку в CMS;
- FTP-клиент, например, TotalCommander или FileZilla.
# Для всех ботов поисковых систем User-agent: *
# Для всех ботов Яндекса User-agent: Yandex
Онлайн генераторы
# Для основного индексирующего бота Google User-agent: Googlebot
Оптимизаторы чаще всего используют эти три директивы в файле robots.txt. Это обычные краулеры поисковых систем, но есть и директивы, описанные для ботов, которые индексируют, например, только новостные разделы:
У них также есть возможность указать определенные каталоги.
Готовые шаблоны
Таким образом, мы позволяем ботам из Yandex и Google только обходить сайт.
Как редактировать?
#Пусть краулер Яндекса проиндексирует весь сайт User-agent:Yandex Allow:/
#Позвольте роботу Google проиндексировать весь сайт User-agent:Googlebot Allow: /
# Разрешить всем остальным роботам индексировать сайт User-agent: * Disallow: /
За каждым правилом для пользовательского агента следуют инструкции для робота, указанные в этой строке. Наиболее часто используемые инструкции — Disallow. Опция Allow используется редко, поскольку отсутствие состязательного каталога эквивалентно разрешению индексирования.
- страницы пагинации;
- страницы с личными данными пользователей;
- страницы с результатами поиска внутри ресурса;
- дублирующиеся страницы;
- логи;
- служебные/технические страницы.
Файл-шаблон с фактическими инструкциями поможет вам создать правильных роботов
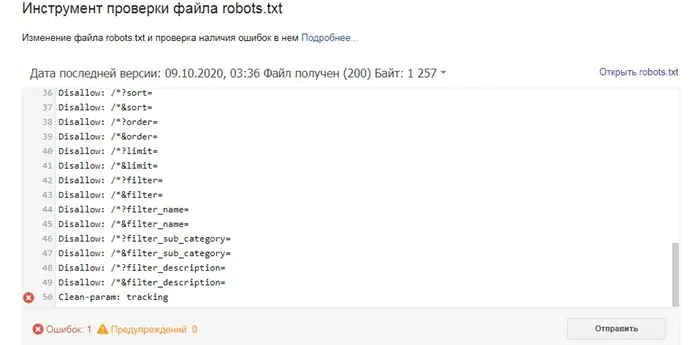
Опция проверки файла robots.txt отсутствует в новом интерфейсе Google Search Console. Теперь можно проверить индексирование страниц по отдельности (URL Check) или сделать запрос на удаление URL (Index — Deletions). Вы можете напрямую обратиться к инструменту для проверки файла robots.txt.
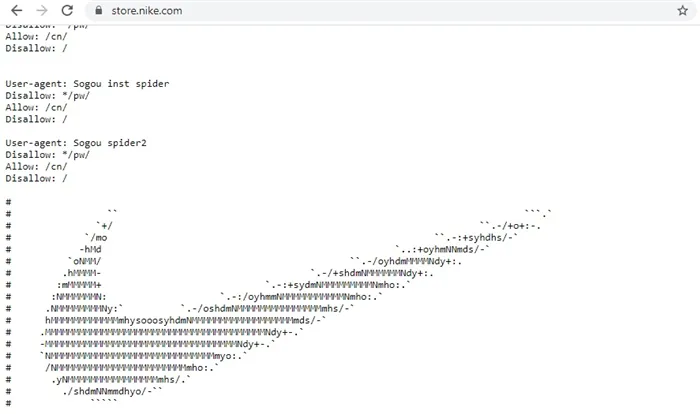
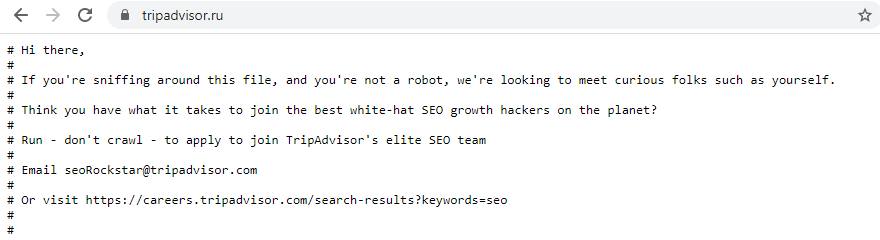
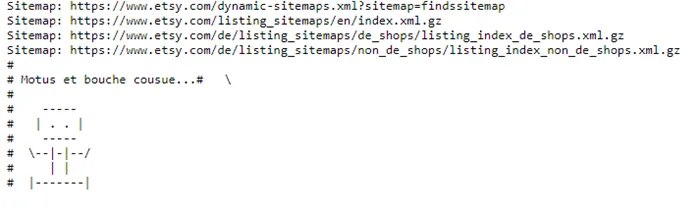
Содержание robots.txt может содержать не только простой список инструкций для поисковых систем. Поскольку файл находится в открытом доступе, некоторые компании используют творческий и юмористический подход. Иногда там можно найти фотографию, логотип бренда или даже предложение о работе. Нестандартный robots.txt реализуется с помощью комментариев # и других символов.
Вот как выглядит robots.txt для интернет-магазина Nike:
Пользователи, которые интересуются robots.txt сайта, вероятно, знают об оптимизации. Поэтому документ может стать дополнительным способом поиска SEO-экспертов.
TripAdvisor:

Веб-сайт Esty Marketplace:
Что нужно исключать из индекса
Есть удивительный инструмент, который позволяет творчески подойти к инструкциям и написать правильный robots.txt — это инструмент от Яндекс.Вебмастер .
Структура Robots.txt
Перейдите к инструменту, введите свой домен и содержимое файла.
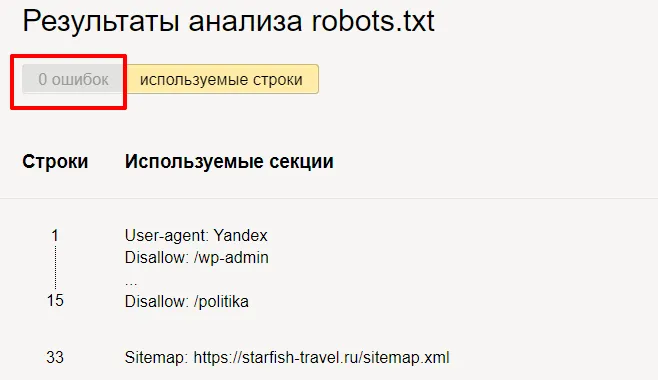
Нажмите кнопку "Проверить" и получите результаты анализа. Здесь мы можем увидеть, есть ли ошибки в robots.txt.Но на этом функции инструмента не заканчиваются. Вы можете проверить, индексируются или нет определенные страницы вашего сайта.
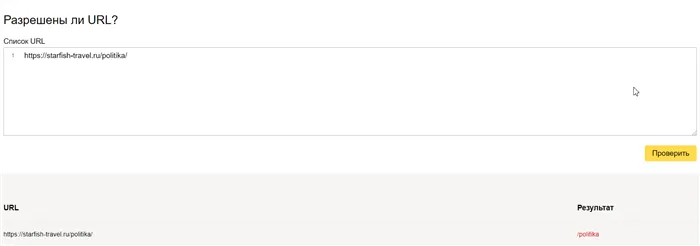
Введите нужные адреса и нажмите на кнопку «Проверить». В колонке «Результат» вы можете увидеть, почему сайт был проиндексирован или нет.
Здесь вы можете проявить творческий подход. Используйте звездочку или знак доллара, чтобы исключить из индексации страницы, которые не полезны для посетителей. Убедитесь, что вы не проиндексировали ни одной важной страницы.Кстати, если вы поставите #, вы сможете оставлять комментарии, которые не будут учитываться роботами.User agent: * Disallow: /cgi-bin # Папки на хостинге Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ # Все служебные файлы могут быть закрыты в противном случае: Disallow: /wp- Disallow: /xmlrpc.php # WordPress API файл Disallow: /*? # search Disallow: /?s= # search Allow: /*.css # styles Allow: /*.js # scripts Sitemap: https://site.ru/sitemap.xml # путь к карте сайта (вы должны указать свой сайт)Существуют разные названия каталогов, но смысл один и тот же: закрыть мусорные и служебные страницы, чтобы показывать поисковым системам только то, что они хотят видеть.
Правильно настроенный файл robots.txt может оказать положительное влияние на продвижение сайта. Если вы хотите избавиться от мусора, хорошая система фильтрации может оказать положительное влияние на производительность вашего сайта.
Пример содержимого robots.txt

Как проверить файл robots.txt
Как еще можно использовать robots.txt?
Проверка файла robots