Это похоже на исключение другого рода. Это может быть исключение другого типа, которое подхватывает блок try-catch. Попробуйте добавить эти два обработчика исключений:
Голосовой бот с искусственным интеллектом на Python

В этом уроке мы создадим речевого робота, используя технологию нейронных сетей Python. Робот может распознавать человеческий голос в режиме реального времени с вашего устройства, например, микрофона ноутбука, и давать осознанные ответы, которые обрабатываются нейронной сетью.
Робот состоит из двух основных частей: словарной части и части голосового помощника.
Вы можете выполнять всю разработку бота в PyCharm IDE, которую можно загрузить с официального сайта JetBrains.
Все необходимые библиотеки могут быть установлены непосредственно в консоли PyCharm с помощью PyPI. Инструкции по установке можно найти на официальном сайте в разделе необходимой библиотеки.
Проблема возникала только с библиотекой PyAudio в Windows. Помогло следующее решение:
pip install pipwin pipwin install pyaudio
Дата-сет
Набор данных — это набор данных для анализа. В нашем случае это текстовый файл со строками в формате вопрос/ответ.
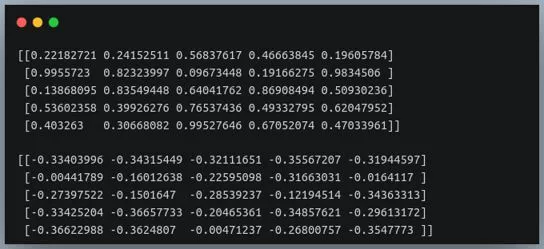
Все текстовые строки оцениваются с помощью функции for, удаляя все ненужные символы из маски, найденной в переменной alphabet. Каждое строковое значение хранится отдельно в таблице записей.
После обработки текста все значения преобразуются в векторы с помощью библиотеки машинного обучения Scikit-learn. В данном примере используется функция CountVectorizer(). Затем все векторы присваиваются классу с помощью функции LogisticRegression().
Когда от пользователя приходит сообщение, оно также преобразуется в вектор, а затем нейронная сеть пытается найти в наборе данных похожий вектор, соответствующий вопросу. Когда вектор найден, мы получаем ответ.
Голосовой ассистент
Библиотека SpeechRecognition используется для распознавания речи и произношения ответов бота. Система ждет в бесконечном цикле вопроса, в нашем случае голоса с микрофона, затем преобразует его в текст и отправляет в нейронную сеть для обработки. После получения текстового ответа он преобразуется в речь, запись сохраняется в папке проекта и удаляется после воспроизведения. Это так просто! Для простоты все сообщения воспроизводятся в текстовом виде на консоли.
При настройках по умолчанию время отклика было довольно долгим, иногда приходилось ждать 15-30 секунд. Кроме того, вопрос был принят с наименьшим количеством шума. Следующие настройки были полезны:
voice_recognizer.dynamic_energy_threshold = False voice_recognizer.energy_threshold = 1000 voice_recognizer.pause_threshold = 0.5
И timeout = None, phrase_time_limit = 2 в listen()
Затем
Качество голоса RHVoice неплохое, и вы быстро привыкнете к нему, но eSpeak очень специфичен и имеет акцент. eSpeak работает на любом железе и является хорошим последним средством, если ничего другое не работает или у пользователя нет установленной программы.
Готовим поляну
Установка речевых компьютеров, голосов и модулей в Windows
При установке Synthesisers под Windows не должно возникнуть никаких проблем. Единственный нюанс — для русского голоса eSpeak и eSpeak NG необходимо скачать расширенный словарь произношения. Распакуйте файл в подкаталог espeak-data или espeak-ng-data в каталоге программы. Теперь замените старый словарь на новый: Переименуйте ru_dict-48 в ru_dict после удаления существующего файла с тем же именем (ru_dict).
- голосовой движок (синтезатор речи) с поддержкой нужных нам языков,
- голоса дикторов для этого движка.
Теперь установите модули pywin32, python-espeak и py-espeak-ng, которые нужны нам для доступа к функциям TTS:
pip install pywin32 python-espeak pyttsx3 py-espeak-ng
- RHVoice от Ольги Яковлевой — имеет четыре голоса для русского языка (один мужской и три женских), а также поддерживает татарский, украинский, грузинский, киргизский, эсперанто и английский. Работает в Windows, GNU/Linux и Android.
- eSpeak и его ответвление — eSpeak NG — c поддержкой более 100 языков и диалектов, включая даже латынь. NG означает New Generation — «новое поколение». Эта версия разрабатывается сообществом с тех пор, как автор оригинальной eSpeak перестал выходить на связь. Система озвучит ваш текст в Windows, Android, Linux, Mac, BSD. При этом старый eSpeak стабилен в ОС Windows 7 и XP, а eSpeak NG совместим с Windows 8 и 10.

Если рядом с вашим компьютером стоит Python 2 и 3, напишите «pip3» и «python3» здесь и впредь при запуске скриптов.
Установка eSpeak(NG) в Linux
Чтобы стать «дружелюбным пингвином» с eSpeak, включая NG, требуется всего минута:
sudo apt-get install espeak-ng python-espeak
pip3 install py-espeak-ng pyttsx3
Затем скачайте словарь ru_dict с официального сайта и распакуйте его:
Теперь найдите адрес каталога espeak-data (или espeak-ng-data) где-нибудь в /usr/lib/ и переместите словарь туда. В моем случае команда перемещения выглядела следующим образом:
sudo mv ru_dict-48 /usr/lib/i386-linux-gnu/espeak-data/ru_dict.
Примечание: Вместо «i386» вы также можете использовать «x86_64″. » или что-то еще. Если вы не уверены, воспользуйтесь поиском:
find /usr/lib/ -name «espeak-data»
RHVoice в Linux
Инструкции по установке RHVoice на Linux можно найти в начале этой статьи. Это несложно, но занимает больше времени, так как приходится скачивать несколько сотен мегабайт.
PyTTSx3 — это удобная мультиплатформенная библиотека для реализации TTS в приложениях на Python 3, использующая различные системы синтеза речи в зависимости от операционной системы:
Это очень удобно: вы пишете код один раз, и он работает везде. Кстати, eSpeak NG поддерживается так же, как и оригинальная версия.
А теперь несколько примеров!
Как и в оригинальной версии, как и в оригинальной версии.
Каждый голос имеет несколько параметров для работы:
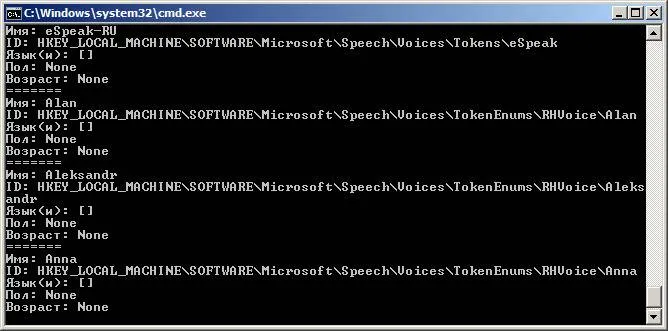
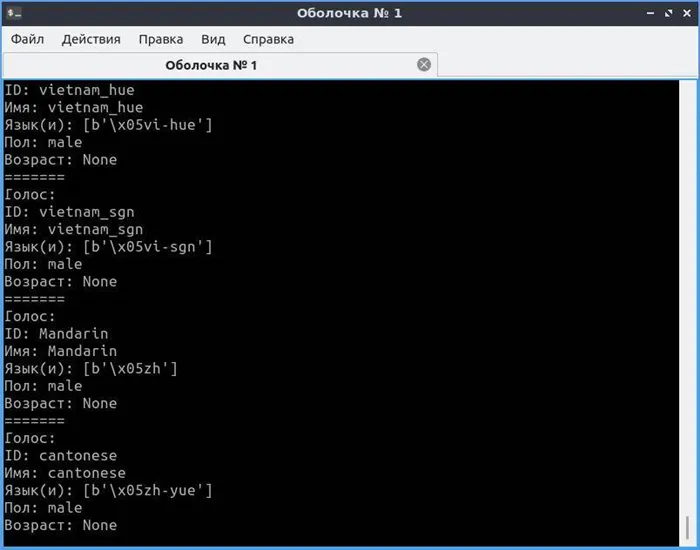
Первый вопрос всегда заключается в том, какие голоса определены на стороне пользователя. Поэтому мы хотим создать скрипт, который показывает все доступные голоса, их имена и метки. Например, назовем файл list_voices.py:
Библиотека pyttsx3
tts = pyttsx3.init() # Инициализация голосового движка.
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Активный двигатель имеет параметр по умолчанию «voices», который содержит список всех голосов, доступных для этого двигателя. Это позволит
Например, RHVoice Aleksandr имеет то преимущество, что его имя уникально, поскольку оно написано в транскрипции и не встречается в таком виде у других известных производителей голосов. Но по pyttsx3 этот голос будет работать только в Windows. Чтобы воспроизвести его в Linux, необходим диспетчер речи (подробнее об этом позже), с которым библиотека не может взаимодействовать. О том, как общаться с «диспетчером», мы поговорим позже, а пока давайте посмотрим на доступные голоса.
Чтобы выбрать голос по имени
В Windows легко выбрать голос по идентификатору и имени. В Linux проще работать с именем или языком. Давайте создадим новый файл set_voice_and_say.py:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
# Установить голос по умолчанию
# Попробуйте установить предпочтительный голос.
для голоса в голосах:
если voice.name == ‘Aleksandr’:
tts.say(‘Командирский голос, товарищ генерал-полковник!’)
В Windows вы услышите голос Александра, а в Linux — стандартный русский язык eSpeak. Если бы мы вообще не указали голос, то после начала была бы тишина, так как композитор по умолчанию говорит по-английски.
Примечание: tts.say() не экспортирует транскрипты сразу, а собирает их в очередь, которую затем нужно запустить для воспроизведения с помощью tts.runAndWait().
Это небольшое приложение каждую минуту обновляет системные часы текущим временем. Точнее, он отображает время каждый раз, когда меняется минута. Например, если вы запустите сценарий в 14:59:59, он заговорит на одну секунду позже.
Давайте создадим новый файл под названием time_tts.py. Всего, о чем мы рассказали выше, должно быть достаточно, чтобы вы смогли легко прочитать и понять приведенный ниже код:
# «Говорящие часы» — это программа для отображения системного времени.
from datetime import datetime, date, time
pyttsx3, импорт времени
tts.setProperty(‘voice’, ‘ru’) # Наш голос по умолчанию
100)
tts.setProperty(‘volume’, 0.8) # Объем (значение от 0 до 1)
def set_voice(): # Поиск и выбор нужного голоса на основе имени
для голоса в голосах:
если voice.name == ‘Aleksandr’:
def say_time(msg): # функция, которая извлекает время в указанном формате.
tts.say(‘Командирский голос, товарищ генерал-полковник!’)
tts.runAndWait() # воспроизведение очереди и ожидание окончания голоса
time_checker = datetime.now() # Получение текущего времени с помощью datetime
если time_checker.second == 0:
say_time(‘ ‘.format(h=time_checker.hour, m=time_checker.minute))
Как озвучить системное время в Windows и Linux

Программа отслеживает и запоминает время, пока вы не остановите ее с помощью Ctrl+Break или Ctrl+C (в Windows или Linux).
Следите за алгоритмом: Чтобы зафиксировать изменение минут, следите за значением секунд и ждите, пока оно не достигнет нуля. Затем мы объявляем время и переводим программу в спящий режим на 55 секунд для сохранения памяти. После этого текущее время снова
Я буду использовать Ubuntu Linux для этого проекта, но вы также должны быть в состоянии использовать его на Windows или Mac. Однако, поскольку это требует много работы в командной строке, я бы рекомендовал делать это на машине Linux.
Существует несколько API и программ для приложений преобразования текста в речь. Espeak и pyttsx работают из коробки, но звучат очень роботизированно. Мы решили использовать Google Text To Speech API, gTTS.
sudo pip install gTTS
Он настолько прост в использовании:
tts.setProperty(‘rate’, 150) # Скорость в % (может быть>С сайта
gtts
импортировать
tts.say(‘Командирский голос, товарищ генерал-полковник!’)
tts.runAndWait() # воспроизведение очереди и ожидание окончания голоса
os
tts = gTTS(text=
Здравствуй мир
, lang=
en
tts.save(
«hello.mp3»
os.system(
«mpg321 hello.mp3»
jarvis python code

#!/usr/bin/env python3
# Требуется PyAudio и PySpeech.
Импорт
Answer in spoken voice (Text To Speech)
Распознавание речи
старшая
из
ВремяВведениеctimeимпортироватьctimeимпортироватьosс сайтаgttsимпортировать)gTTSdef)Звоните наaudioString)

Complete program
вывести(audioString)ctimeenastts.save(Времяos.system(ctimedefctime# запись звукаctimeимпортироватьВремяВведениеctimeимпортироватьaudio = r.listen(source)# Распознавание речи с помощью Google Speech Recognition(Данные =):Попробуйте# Используйте ключ API по умолчанию# Чтобы использовать другой ключ API: `r.recogn_google(audio, key=»GOOGLE_SPEECH_RECOGNITION_API_KEY»)`.импортировать)gTTS«Вы сказали:»)Звоните накроме)audio = r.listen(source)вывести():«Система распознавания речи Google не смогла понять аудиозапись»за исключениемsr.RequestErrore:asвывестиПопробуйте((e)))возвратДанныеdef«»Джарвис:Данные«Как дела?»Данные:Попробуйте(«Я в порядке»«Который час?»Данные:speak(ctime())Попробуйте(Данные:)Данные:местоположение = данныеasговорить(Попробуйте(«Could not request results from Google Speech Recognition service;<0>«.+ местоположение +» есть».os.system(«chromium-browser https://www.google.nl/maps/place/»audio = r.listen(source)«/&?»(# инициализация):iftime.sleep(inговорить(«Привет, Фрэнк, чем могу помочь?»в то время как)ifdata = recordAudio()inговорить(Оставьте ответ:ifЧтобы скомпилировать и запустить эту программуinговорить(Здравствуйте, я получаю сообщение об ошибке. Вы можете мне помочь? Я погуглил, но не смог найти решение….» «)ALSA lib pcm_dsnoop.c:618:(snd_pcm_dsnoop_open) cannot open slave ALSA lib pcm_dmix.c:1022:(snd_pcm_dmix_open) cannot open slave ALSA lib pcm_dmix.c:1022:(snd_pcm_dmix_open) cannot open slave Cannot connect to server socket err = No such file or directory Cannot connect to server request channel jack сервер не запущен или не может быть запущен2«Привет, Фрэнк, чем могу помочь?»Как вообще работают навыки? Проще говоря, Алиса и ваш сервер обмениваются файлами в формате JSON, содержащими необходимую информацию. И сервер получает не только распознанный текст, но и уже подготовленный к обработке запрос. Вы можете выбрать любой язык программирования — все, что вам нужно, это способность создать веб-сервер на этом языке. Мы выбрали Python как один из самых простых и популярных языков.Возможности Алисы — это, по сути, чатбот. И первое, что пытаются сделать разработчики чатботов, это написать «эхо-бота», который посылает вам одно и то же, когда вы ему что-то посылаете.Для начала, основные понятия таковы:)Звоните наfrom flask import flask import request import json app = Flask(__name__) @app.route(‘/post’, methods=’POST’) def main(): ## Создание ответа response =.Возможности Алисы — это, по сути, чатбот. И первое, что пытаются сделать разработчики чатботов, это написать «эхо-бота», который посылает вам одно и то же, когда вы ему что-то посылаете.Это очень много кода. Давайте разберем это по частям. Прежде всего, важно упомянуть, что наш сервер написан на Flask, и если вы хотите разобраться в этом фреймворке более глубоко, на Хабрахабре есть отличное руководство. Однако здесь следует помнить о нескольких важных моментах.)Мы покончили с основами Flask — в принципе, нам больше ничего не нужно для разработки простых возможностей. Давайте посмотрим, что происходит в наших двух функциях.В main() мы сначала создаем шаблон для ответа. Обратите внимание, что мы передаем два параметра из запроса: сессию и версию, а затем во второй функции мы передаем шаблон ответа и запрос, преобразованный в JSON.2)«Привет, Фрэнк, чем могу помочь?»Когда пользователь входит в навык в первый раз, запрос также приходит, но в нем нет текста. Чтобы справиться с этой ситуацией, я добавил элемент управления в функцию.)И это все? Теперь нам нужно проверить, работает ли наш пример или мы где-то допустили ошибку. Но как мы можем проверить это?1:Существует несколько способов проверки возможностей. Одним из самых простых способов является использование утилиты alice-nearby, которую вы можете запустить локально на своем компьютере. Как его установить, подробно описано, поэтому я не буду заострять на этом внимание. Так что тесты можно начинать.Поздравляю, ваш первый навык работает! Примечание: Запрос и ответ отображаются в JSON справа. Но авторы этой утилиты не сами разработали интерфейс. Они просто создали локальную версию приложения для проверки навыков на основе тестового состояния
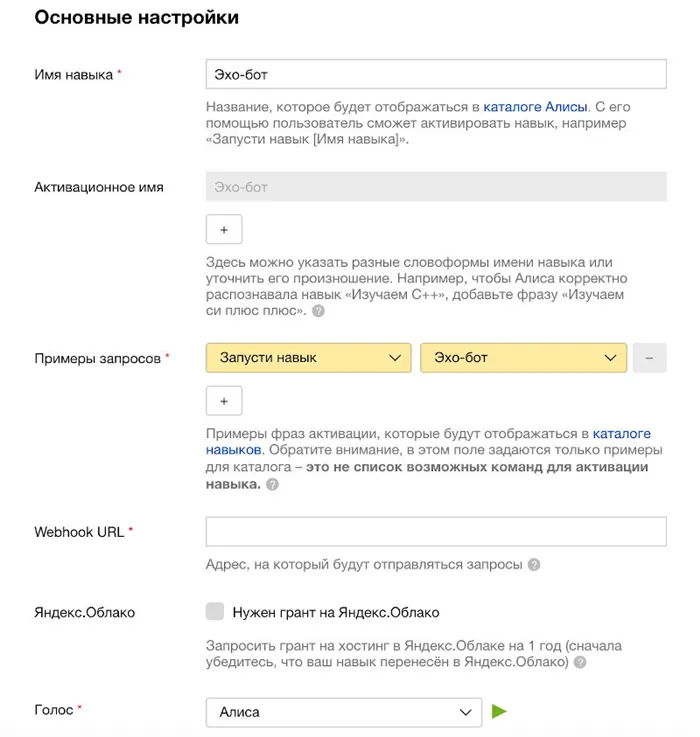
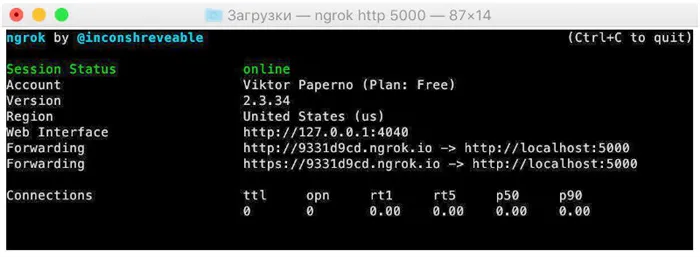
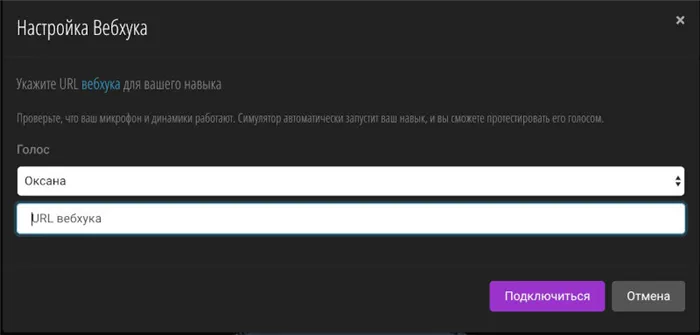
Запустите ngrok, скопируйте URL, который мы указали в поле Webhook URL, сохраните настройки и перейдите на вкладку Test. Обратите внимание, что ngrok экспортирует два URL-адреса: HTTP и HTTPS, нам нужен HTTPS. И не забудьте добавить /post, чтобы убедиться, что запросы обрабатываются правильно.
Помимо написания, я хочу проверить, как все это будет звучать, если наши ответы зачитает Алиса. Это возможно, если наши навыки выходят за рамки обычных. Это вряд ли удастся, но не отчаивайтесь! Есть два решения.
За последний год технология машинного обучения развивалась поразительными темпами. Все больше компаний делятся своим опытом, открывая новые возможности для разработки интеллектуальных цифровых помощников.
В этой статье я хотел бы поделиться своим опытом внедрения голосового помощника и представить несколько идей о том, как сделать его еще умнее и полезнее.
Описание сообразительности
Все мы не в своем уме. Как сделать новый навык для «Алисы» на Python

Работа в автономном режиме
Необходимые зависимости

Распознавание речи и синтез речи
При поддержке
- request — запрос, который поступил от «Алисы»;
- response — ответ нашего сервера, который отправляется «Алисе».
pip install PyAudio (с использованием микрофона)
pip install pyttsx3 (синтез речи)<'session': request.json'session', 'version': request.json'version', 'response':<'end_session': False>>Для распознавания речи можно использовать один или оба варианта:Давайте начнем с изучения того, как работать с речевым вводом. Нам понадобится микрофон и несколько установленных библиотек: PyAudio и SpeechRecognition.
- Важно не забыть импортировать модули: Flask отвечает непосредственно за работу веб-приложения, request — за работу с запросами, а json необходим, потому что мы и получаем, и отправляем файлы JSON, а не объекты из Python.
- Нужно создать экземпляр класса Flask, а затем его запустить. Это и есть непосредственно «ядро» сервера.
- Декоратор app.route необходим, чтобы связать URL, тип запроса и функцию, которая будет обрабатывать этот запрос.
Давайте подготовим основные инструменты для распознавания речи:
Теперь создадим функцию для записи и распознавания речи. Для распознавания онлайн нам нужен Google, поскольку он обеспечивает высококачественное распознавание на большом количестве языков.
Но что делать, если у вас нет доступа в Интернет? Вы можете использовать автономные решения для распознавания. Лично я с энтузиазмом отношусь к проекту Vosk.
Теперь, если вы реализуете автономное решение и добавляете в проект необходимые языковые модели, вы автоматически переключаетесь на автономное распознавание, когда находитесь вне сети.
Чтобы не повторять одно и то же предложение дважды, я решил записать звук микрофона во временный wav-файл, который удаляется после каждого распознавания.
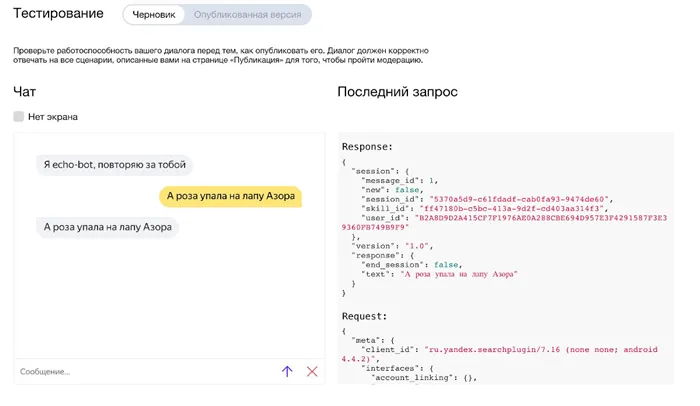
Тестирование навыков
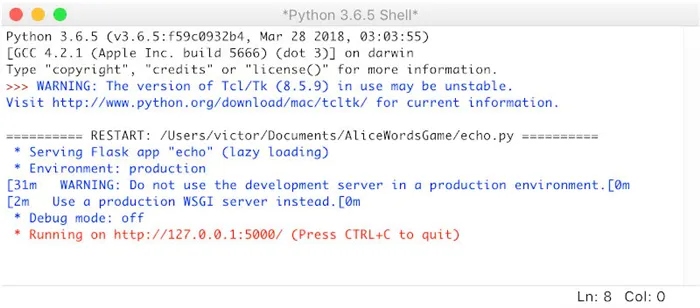
Полученный код выглядит следующим образом
- Запускаем наше приложение.
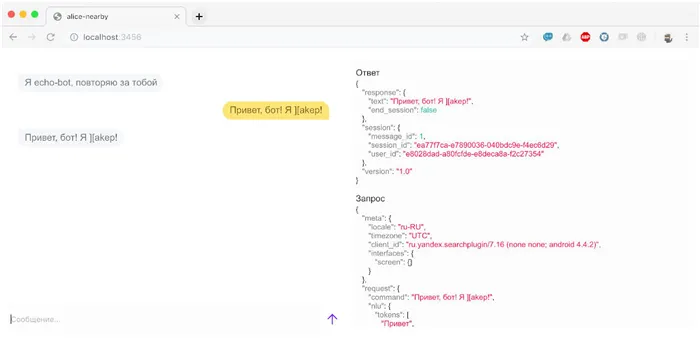
- Запускаем alice-nearby, указав в качестве значения webhook http://localhost:5000/post .

- Открываем любой браузер и переходим по ссылке localhost:3456, чтобы убедиться, что открылось приложение для тестирования.
Вы можете спросить себя: «Зачем поддерживать автономные функции?».
Я думаю, что всегда следует помнить о том, что пользователь может быть отключен от сети. В этом случае голосовой помощник все равно может быть полезен при использовании в качестве собеседника или для выполнения ряда простых задач, таких как подсчет чего-либо, рекомендация фильма, помощь в выборе блюд, игра и т.д.
Поскольку наш голосовой помощник может иметь пол, язык и, классически, имя, мы создаем отдельный класс для этих данных, с которым будем работать в будущем.
Чтобы наделить нашего помощника голосом, мы используем библиотеку автономного синтеза речи pyttsx3. Он автоматически находит голоса, доступные для синтеза на нашем компьютере, в зависимости от настроек нашей операционной системы (поэтому возможно, что вы можете использовать другие голоса в
pip install requirements.txt
Настройка синтеза и анализа речи в автономном режиме
Голосовой помощник использует функции синтеза речи, встроенные в операционные системы (т.е. голоса зависят от настроек операционной системы). Для этого используется библиотека pyttsx3. Нажмите здесь для получения дополнительной информации.
- Сделать навык приватным. Для этого в настройках необходимо поставить соответствующую галочку. В таком случае модераторы проверят только название, активационное имя и приветственное сообщение, где должно быть описано, что делает навык. Подробнее про модерацию навыков можно узнать из видеоруководства.
- Воспользоваться симулятором. В настройках необходимо указать URL — и можно начинать.

Как создать своего голосового помощника python
В целом, решение работает на Windows, Linux и macOS с небольшими отличиями при установке библиотек PyAudio и Google.
Чтобы установить PyAudio на Windows, вы можете найти и загрузить необходимый файл whl, который зависит от архитектуры и версии Python, здесь, в папке проекта. Затем его можно установить с помощью аналогичной команды:

Что умеет мой голосовой ассистент?
| pip install PyAudio-0.2.11-cp38-cp38m-win_amd64.whl. | Если у вас возникли проблемы с установкой PyAudio на macOS, это решение может помочь. | Чтобы избежать проблем с установкой Vosk на Windows, я рекомендую загрузить файл whl в зависимости от архитектуры и версии Python, которая вам нужна. Вы можете найти его здесь. Если вы загрузите файл в папку проекта, вы можете начать установку с помощью аналогичной команды: |
| pip install vosk-0.3.7-cp38-win_amd64.whl | Модели для распознавания речи с помощью Vosk можно найти здесь. Я использовал модели en и ru. | Настройка данных прогноза погоды из OpenWeatherMap |
Для получения данных прогноза погоды я использовал сервис OpenWeatherMap, для которого требуется ключ API. Вы можете получить ключ API и ознакомиться с документацией после регистрации (есть бесплатная цена) здесь. Примеры его использования можно найти здесь
Команды для установки других библиотек сторонних разработчиков:
- pip install SpeechRecognition (высокое качество online-распознавания, множество языков)
- pip install vosk (высокое качество offline-распознавания, меньше языков)
Шаг 1. Обработка голосового ввода
Команда установки
Делегировать библиотеку
Pip install google
Поиски Google
pip install SpeechRecognition
Распознавание речи (преобразование речи в текст)
pip install vosk
Независимое распознавание речи (Speech-To-Text)
pip install pyttsx3
Шаг 2. Конфигурация голосового ассистента
Автономный синтез речи в Windows (Text-To-Speech)
pip install wikipedia-api
API Википедия
Как создать своего голосового помощника python
pip install googletrans
Google Translate
- распознавать и синтезировать речь в offline-режиме (без доступа к Интернету);
- сообщать о прогнозе погоды в любой точке мира;
- производить поисковый запрос в поисковой системе Google (а также открывать список результатов и сами результаты данного запроса);
- производить поисковый запрос видео в системе YouTube и открывать список результатов данного запроса;
- выполнять поиск определения в Wikipedia c дальнейшим прочтением первых двух предложений;
- переводить с изучаемого языка на родной язык пользователя (с учетом особенностей воспроизведения речи);
- искать человека по имени и фамилии в соцсетях ВКонтакте и Facebook;
- «подбрасывать монетку»;
- воспроизводить случайное приветствие;
- воспроизводить случайное прощание с последующим завершением работы программы;
- менять настройки языка распознавания и синтеза речи;
- TODO многое другое.
pip install pyowm
Получение данных о погоде с помощью OpenWeatherMap
pip install python-dotenv
Манипулирование файлами .env для хранения ключей API
pip install scikit-learn
Машинное обучение для оценки намерений
В этом учебном пособии мы рассмотрим создание речевого робота с использованием технологии нейронных сетей на языке Python. Робот может распознавать человеческий голос в режиме реального времени с вашего устройства, например, микрофона ноутбука, и генерировать осознанные ответы, которые обрабатываются нейронной сетью.
Робот состоит из двух основных частей: словарной части и части голосового помощника.
Вы можете выполнять всю разработку бота в PyCharm IDE, которую можно загрузить с официального сайта JetBrains.
Все необходимые библиотеки могут быть установлены непосредственно в консоли PyCharm с помощью PyPI. Команды установки можно найти на официальном сайте в разделе необходимой библиотеки.
Официальный сайт PyPI
Проблема возникала только с библиотекой PyAudio под Windows. Помогло следующее решение:
Набор данных — это совокупность данных, подлежащих анализу. В нашем случае это текстовый файл, содержащий строки в формате вопрос/ответ.
Все текстовые строки перебираются с помощью функции for, удаляя из текста все ненужные символы с помощью маски, расположенной в переменной alphabet. Каждое строковое значение хранится отдельно в таблице набора данных.
| После обработки текста все значения преобразуются в векторы с помощью библиотеки машинного обучения Scikit-learn. В данном примере используется функция CountVectorizer(). Затем все векторы относят к классу с помощью классификатора LogisticRegression(). | Когда от пользователя приходит сообщение, оно также преобразуется в вектор, а затем нейронная сеть пытается найти в наборе данных похожий вектор, соответствующий вопросу, и если такой вектор найден, мы получаем ответ. |
|---|---|
| Библиотека SpeechRecognition используется для распознавания речи и произношения ответов бота. Система ждет в бесконечном цикле вопроса, в нашем случае голоса с микрофона, затем преобразует его в текст и отправляет в нейронную сеть для обработки. После получения текстового ответа он преобразуется в речь, запись сохраняется в папке проекта и удаляется после воспроизведения. Это так просто! Для простоты все сообщения воспроизводятся в текстовом виде на консоли. | При настройках по умолчанию время отклика было довольно долгим, иногда приходилось ждать 15-30 секунд. Этот вопрос также был принят без малейшего шума. Следующие настройки были полезны: |
| И timeout = None, phrase_time_limit = 2 в listen(). | В результате бот начал отвечать с минимальной задержкой. |
| Потребовалось несколько минут, чтобы сообщение прекратилось, но это произошло. Описание этой и других настроек можно найти на той же странице PyPI в разделе библиотеки SpeechRecognition, но настройку phrase_time_limit я там почему-то не нашел. Я случайно наткнулся на него в Stack Overflow. | Это небольшой текстовый пример. Конечно, вопросов и ответов должно быть гораздо больше. |
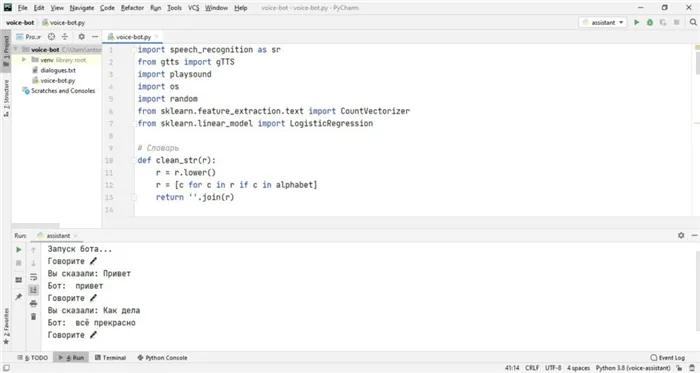
| Как работает бот в PyCharm | Примером одного из самых популярных голосовых помощников является Яндекс Алиса. |
Голосовой бот с искусственным интеллектом на Python
В этом уроке мы создадим речевого робота, используя технологию нейронных сетей Python. Робот может распознавать человеческий голос в режиме реального времени с вашего устройства, например, микрофона ноутбука, и давать осознанные ответы, которые обрабатываются нейронной сетью.
Робот состоит из двух основных частей: словарной части и части голосового помощника.
Вы можете выполнять всю разработку бота в PyCharm IDE, которую можно загрузить с официального сайта JetBrains.
Все необходимые библиотеки могут быть установлены непосредственно в консоли PyCharm с помощью PyPI. Инструкции по установке можно найти на официальном сайте в разделе необходимой библиотеки.
Проблема возникала только с библиотекой PyAudio в Windows. Помогло следующее решение:
Дата-сет
Все текстовые строки оцениваются с помощью функции for, удаляя все ненужные символы из маски, найденной в переменной alphabet. Каждое строковое значение хранится отдельно в таблице записей.
После обработки текста все значения преобразуются в векторы с помощью библиотеки машинного обучения Scikit-learn. В данном примере используется функция CountVectorizer(). Затем все векторы присваиваются классу с помощью функции LogisticRegression().
Когда от пользователя приходит сообщение, оно также преобразуется в вектор, а затем нейронная сеть пытается найти в наборе данных похожий вектор, соответствующий вопросу. Когда вектор найден, мы получаем ответ.
Голосовой ассистент
Библиотека SpeechRecognition используется для распознавания речи и произношения ответов бота. Система ждет в бесконечном цикле вопроса, в нашем случае голоса с микрофона, затем преобразует его в текст и отправляет в нейронную сеть для обработки. После получения текстового ответа он преобразуется в речь, запись сохраняется в папке проекта и удаляется после воспроизведения. Это так просто! Для простоты все сообщения воспроизводятся в текстовом виде на консоли.
При настройках по умолчанию время отклика было довольно долгим, иногда приходилось ждать 15-30 секунд. Кроме того, вопрос был принят с наименьшим количеством шума. Следующие настройки были полезны:
И timeout = None, phrase_time_limit = 2 в listen()
Затем
Качество голоса RHVoice неплохое, и вы быстро привыкнете к нему, но eSpeak очень специфичен и имеет акцент. eSpeak работает на любом железе и является хорошим последним средством, если ничего другое не работает или у пользователя нет установленной программы.
Текст дата-сета
Код Python