Приказы о запрете не дают 100% гарантии того, что страница не появится вновь. Страницы, защищенные паролем, могут создавать неудобства для пользователей.
Как удалить страницу из поисковой выдачи
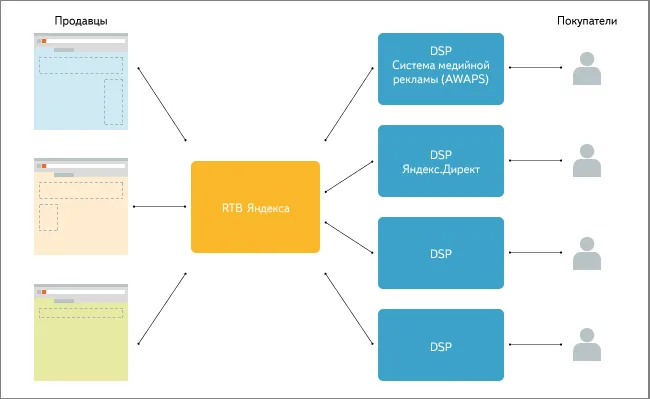
Владельцу бизнеса может потребоваться удалить страницу из поиска Google или Яндекса. Ресурс неправильно зарегистрирован или содержащаяся в нем информация теряет смысл. Однако хуже всего то, что поисковые системы возвращают страницы, содержащие конфиденциальные данные клиентов.
Чтобы избежать такой ситуации, необходимо знать, как удалить часть или части вашего сайта из индекса.
В зависимости от поисковой системы существует несколько способов сделать это. Давайте рассмотрим преимущества и недостатки каждого варианта.
Прежде чем выбрать метод, определите следующее
- нужно удалить доступ к странице только из поисковиков;
- нужно удалить доступ абсолютно для всех.
Ошибка 404
Важно: Это самый простой метод, но удаление информации из поисковых систем может занять до месяца. Удалите страницу из поисковой системы и сайта в целом.
При поиске конкретной информации пользователь столкнется с сообщением об ошибке 404 — «Страница не найдена». Это результат фактического удаления страницы сайта.
Это делается путем удаления страницы в таблице администрирования сайта. На языке поисковой системы сервер сконфигурирован для предоставления HTTP-статуса с кодом 404 not found для конкретного URL. В следующий раз, когда поисковый робот обращается к файлу, сервер сообщает ему, что документ не может быть найден.

Поисковая система понимает, что страница больше недоступна, и удаляет ее из результатов поиска, чтобы не загонять пользователя в поиск по странице ошибки 404.
Этот метод имеет свои уникальные особенности.
- Простота: настройки проводятся всего в несколько кликов.
- Страница полностью исчезает из сайта, поэтому если необходимо просто скрыть от выдачи конфиденциальную информацию, то лучше обратиться к другим методам.
- Если на страницу, которую нужно скрыть, имеются входящие ссылки то эффективнее будет настроить 301 редирект.
- Непосредственно к выпадению страницы из поиска приводит не ее удаление из сайта, а последующая за этим индексация. В среднем необходимо от 1–2 дня до месяца, чтобы робот посетил ресурс и отпинговал страницу.
Хотя этот вариант является одним из самых простых и удобных для администраторов сайта, сообщение об ошибке 404 редко бывает приятным для посетителей сайта. В некоторых случаях это может привести к тому, что клиенты не возвращаются на данный ресурс.
Чтобы избежать таких последствий, все больше и больше веб-мастеров сегодня пытаются творчески подойти к размещению страниц или информации об ошибке 404. Это интересное предложение для пользователей. Такая политика может помочь веб-сайтам стать более удобными для клиентов и популярными.
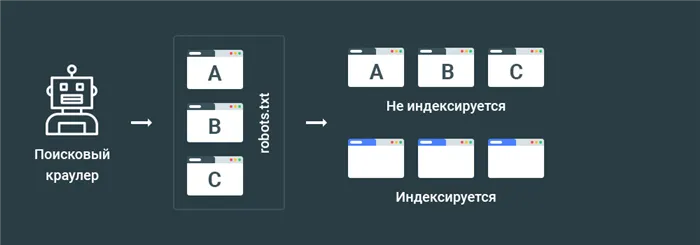
Robots.txt
Важно: Этот метод не удаляет страницу из поиска, а только скрывает ее из результатов. Страница по-прежнему видна из других каналов трафика.
Довольно распространенный метод удаления отдельных объектов и целых участков. Поскольку через robot.txt предоставляются как лицензии, так и запреты на индексацию, неудивительно, что в Интернете было создано множество полезных инструкций на тему алгоритмов удаления страниц таким способом. Из Деваки. Однако все они зависят от одного начала.
Чтобы поисковые системы не смогли найти страницу, они должны иметь доступ к радикальному каталогу домена. В противном случае необходимо использовать метатеги.
Файл robots.txt содержит всего две строки.
- User-agent: сюда вносится название робота, к которому требуется применить запрет (наименование можно брать из Базы данных сканеров, но в случае, но если вы хотите в будущем закрывать страницу от всех, то просто используйте « User-agent: * »);
- Disallow: в этой директиве указывается непосредственно адрес, о котором идет речь.
Эта пара команд относится к определенному URL. При необходимости в файл можно запретить помещать много объектов в одном и том же месте. Они полностью независимы друг от друга.
После закрытия страницы или раздела с помощью robots.txt необходимо дождаться следующего индекса.
Обратите внимание, что это всего лишь рекомендация, что в случае с поисковыми системами действия в robots.txt не всегда соблюдаются. Даже если эта директива будет соблюдена, ресурс продолжит появляться в выдаче, но уже путем регистрации закрытия через robots.txt.
Если статус объекта в файле не меняется с течением времени, искатель удаляет его из базы данных.
В любом случае, удаленный объект будет отображен при нажатии на внешнюю ссылку, если таковая имеется.
Эта статья поможет вам понять, какие страницы не должны индексироваться, как удалить страницы из индекса поисковых систем и зачем это нужно делать.
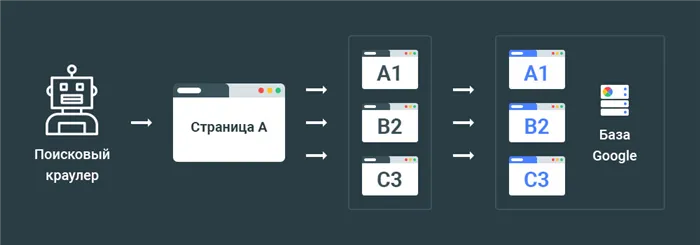
Способ 1 — Noindex
Директива NOINDEX поддерживается поисковыми системами только в том случае, если запись размещается в HTTP-ответе страницы, если запись размещается в мета-метке.
Ранее эта директива была разрешена в файле robots.txt. Однако модель протокола исключения robots изменилась, и использование директивы в файле больше не допускается.
Ссылка ниже на блог MegainDex о рекомендуемом материале robots.txt — Google обновляет правила robots.txt. Что изменилось и что необходимо сделать?
На практике необходимо запретить индексацию с помощью роботов с пост-тегами. Например, если вы хотите отключить индексирование сайта Indexoid, вам нужно использовать этот код на страницах, которые будут запрещены.
Если вам не нужно индексировать страницы по HTTP для этой цели, то вам понадобится код ответа сервера, в котором будет указано следующее
Пример кода ответа сервера:.
HTTP/1.1 200 OK Дата: Tue, 25 May 2010 21:42:43 GMT
В результате поисковая система удалит страницу из своего индекса во время следующей итерации обнаружения.
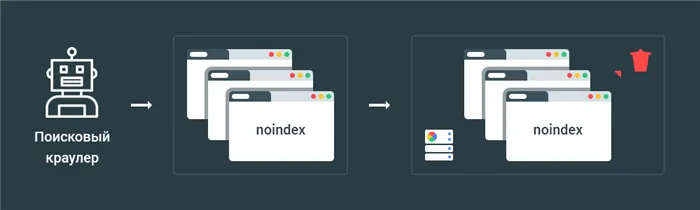
Способ 3 — Disallow в файле robots.txt
Директива ban поддерживается протоколом блокировки роботов.
Применение этой директивы приводит к созданию списка страниц, которые детектор поисковой системы должен игнорировать, т.е. не обращаться к ним.
Хотя директива запрета запрещена, страницы сайта могут быть добавлены в индекс, если об этих страницах сообщают другие страницы. Эта информация проверена на практике.
В результате такой подход оказывается неэффективным.
Поэтому директива DisAllow используется для указания ссылок на страницы, которые не должны индексироваться, но их содержимое все равно может быть внесено в индекс. Например, если есть открытые ссылки с других страниц на закрытые страницы.
Способ 4 — Защита страниц паролем
Защита паролем не позволяет поисковым системам получить доступ к содержимому страниц сайта.
Обычно такая защита используется для ограничения доступа к разделам сайта, доступным по модели платной зарплаты.
Поисковые системы индексируют защищенные паролем страницы и часто удаляют их из своих индексов.
Чтобы избежать таких последствий, все больше и больше веб-мастеров сегодня пытаются творчески подойти к размещению страниц или информации об ошибке 404. Это интересное предложение для пользователей. Такая политика может помочь веб-сайтам стать более удобными для клиентов и популярными.
Способ #3: Удаление URL навсегда
Если страница не служит цели, ее можно просто удалить с сайта. Когда робот сканирует страницу, сервер сообщает ему, что ее не удалось найти (404) или что она была навсегда удалена (410).
Обратите внимание, что предпочтительнее использовать вызов ошибки сервера 410. Если стандартный 404 не найден, URL может привести к переиндексации, см. справку Google для получения дополнительной информации.
Инструменты сервиса Яндекс Вебмастер — Инструменты Контроль ревизии
Страницы, которые будут удалены из поиска, могут иметь постоянный трафик или входящие ссылки для SEO.
В таких случаях, чтобы облегчить работу пользователей, рекомендуется использовать редирект 301 для перенаправления новых посетителей и роботов на другую соответствующую страницу или раздел.
Не рассчитывайте на Robots.txt
robots.txt — это специальный файл, используемый для регулирования процесса индексации сайта поисковыми системами.
Например, с его помощью можно ограничить доступ роботов Google к определенным страницам и разделам. Законодательство указывает на то, что полностью полагаться на этот файл нельзя.
Если страница, которую необходимо удалить из поиска, имеет доверенную входящую ссылку, Google может проигнорировать требование Robots.txt и отобразить страницу в поиске с ограниченным переходом.
Как удалить весь сайт из Google
Лучший способ удалить сайт из Google — добавить метку Noindex на каждую страницу. Вы также можете использовать Add -On для ограничения доступа к содержимому с помощью аутентификации сервера или просто установить пароль пользователя для загрузки и просмотра документов.
Вы также можете блокировать сайты, которые обходят роботов, указав в файле robots.txt следующее
Директива DisAllow сообщает детекторам поисковых систем, что им не нужно индексировать содержимое. Такие страницы могут по-прежнему индексироваться. Например, если на эти страницы есть ссылки с других страниц.
Как удалить страницу сайта из поиска Google
Не срочное удаление страницы
Содержимое сайта или всей страницы необходимо удалить, но только срочно. Например, контент больше не актуален. Если он «висит» в кэше Google уже некоторое время (недели) (и поэтому может появиться в SERPs), я согласен.
В вышеуказанных случаях можно предложить простое удаление всего содержимого страницы.
Удаление веб-сайта немного отличается в каждой CMS. Например, в WordPress нужно открыть страницу в процессоре и выбрать «Удалить корзину».
Удаленная страница со временем начнет генерировать ошибку 404. Через несколько дней детектор Google автоматически блокирует такие страницы из индекса.
Объединение нескольких страниц и указание главной
Существуют разные версии одной и той же страницы. Вы хотите объединить все эти страницы и перенести их на один URL. Содержание этих страниц не представляет особого интереса.
В этом случае следует использовать одну обычную этикетку. Более подробную информацию о том, как определить, какие страницы являются нормальными, можно найти в справке Google.
Убедитесь, что Rel Canonical относится к основному сайту, а не к вторичному.
Обратите внимание, что стандартная метка не является директивой. В результате детекторы могут игнорировать его.
Кстати, помимо метки, после URL можно использовать редирект (желательно 301) и параметр (параметром является символ «?»). сразу после этого). Информацию о том, как блокировать двухпараметрический контент, см. в консоли поиска Google.
Существует несколько способов нормализации контента. Выберите инструмент, с которым вы наиболее хорошо знакомы.
Срочное удаление страницы из результатов поиска
Вам необходимо как можно скорее удалить страницы из индекса. Обычно нет времени разбираться с тегами /meta. Речь идет о конфиденциальных данных или об исполнении судебного решения.
В этом случае необходимо использовать ‘URL Removal Tool’. Откройте инструмент и выберите местоположение.
Укажите полный URL-адрес страницы, которую нужно скрыть.
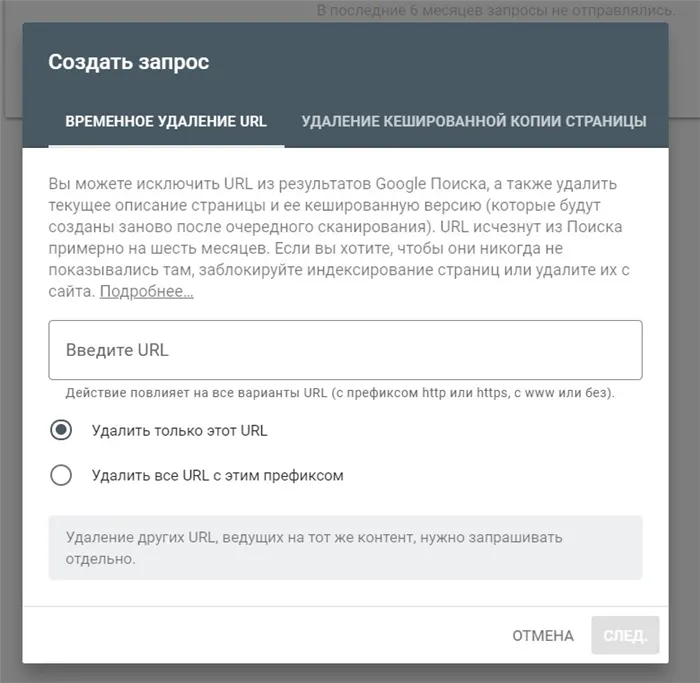
Кстати, здесь же можно удалить все URL с текущим префиксом и скрыть сохраненную копию страницы. Проверьте свой запрос:.
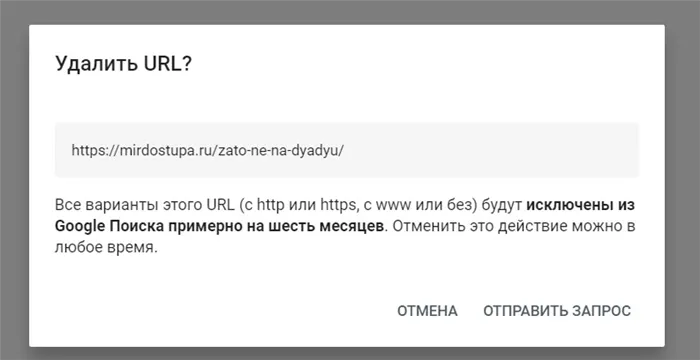
Этот инструмент не буквально удаляет страницу из индекса, а только на шесть месяцев. Затем вам необходимо принять окончательное решение. Удалить все содержимое страницы или ограничить доступ к ней.
Инструмент действует не сразу. Он скрывает проблемные страницы на 24 часа.
Это самый быстрый способ указать Google на необходимость удаления страницы из результатов поиска.
Страницу нужно удалить из поиска, но она должна быть доступной
Всю страницу нужно удалить из индекса, но она будет доступна некоторым посетителям сайта.
Как удалить / стереть страницу из результатов поиска «Яндекс»
Далее рассмотрим, что предлагает Яндекс для удаления URL-адреса из результатов поиска.
Чтобы эффективно удалить URL полностью, домашняя поисковая система рекомендует использовать известный порядок запрета. Это должно быть указано непосредственно в файле robots.
Второй метод. На удаляемой странице должен быть установлен метатег robots (помните об инструкции noindex).
Стоит отметить, что домашние поисковые машины сначала анализируют файл robots, а затем начинают сканирование сайта. Убедитесь, что ваш robots.txt содержит правильные инструкции. Для этого можно использовать специальные инструменты.
Другой вариант — установить статус HTTP (чтобы удалить его, необходимо установить его на самой веб-странице). В последнем случае необходимо установить точный редирект (редирект 404 или 403).
Если вы явно запретите ползать по веб-странице в системном файле роботов, то примерно через 24 часа (или раньше) краулер прекратит ползать по сайту-нарушителю.
Альтернативный сценарий. Вы «стираете» веб-страницу с помощью тега robots (или сразу же создаете перенаправление с помощью http-status), а краулер продолжает ползать по проблемной веб-странице (в течение нескольких дней, хотя и не наверняка). Страница по-прежнему недоступна и не обновляется спустя несколько дней? Это означает, что он будет автоматически удален из YandexSERP в ближайшее время.
Как ускорить удаление URL в «Яндексе»
Это может повлиять на скорость удаления URL-адресов. Во-первых, удалите веб-страницу из используемой вами панели администрирования CMS (URL должен вернуть код 404). При необходимости можно также удалить всю группу URL-адресов.
Кстати, Яндекс позволяет удалять страницы из поиска, даже если вы не являетесь владельцем сайта и не имеете прав доступа к домену Яндекс.Вебмастер (где находится удаляемая страница). Откройте инструмент и укажите URL-адрес, о котором идет речь.
Этот инструмент полезен только в том случае, если у вас есть причина удалить URL. Это могут быть коды 403/404/410, ограничения на немедленный индекс в robots.txt или мета-теги noindex.
Одновременно можно удалить до 500 URL-адресов, если авторитетность сайта ‘Ya.V’ проверена.
Это все способы удаления страниц из индексов Яндекса и Google. Здесь рекомендуется рассмотреть наиболее распространенные ошибки, которые могут возникнуть при удалении страниц.
Как не надо удалять страницу из поиска
Nofollow – только рекомендация
Этот метод вообще не работает, так как nofollow — это просто рекомендация краулера, и он, скорее всего, не будет ее выполнять.
Тег noindex уже не работает
Этот метод частично работал, но в 2019 году Google объявил, что noindex больше не поддерживается в robots.txt.
Каноникал на другой URL
Canonical используется для указания главной страницы, которая будет индексироваться. Noindex, с другой стороны, говорит краулеру не индексировать страницу. Именно здесь и возникает конфликт. Поэтому страницы с регулярными тегами, указывающими на другие URL, не следует использовать.
Блокировка поисковых роботов в robots.txt
Таким образом, вы только советуете краулеру не пропускать страницу, но он все равно может свободно проползти по ней и включить ее в SERP.
Если вам нужна данная страница на вашем сайте, создайте обычный элемент. Если это не требуется, создайте 301/404 редирект.
Социальные сети, рассылки, видеоплатформы и блоггеры в Google и Yandex